can we use slice(1e-5, 1e-3) as explained in lesson1 instead of 3e-02?
Hi 
I had a quick question regarding accuracy (in a regular classifier not multi classifier). Jeremy said that basically what happens is we use argmax to find the index/label of the predicted class and compare it to the actual and then we take a mean.
What I can’t figure out is where does a mean come from? What are we taking a mean of? ie if we have a predict value with an index of 4 for example and an actual with index of 5 when we compare those (4==5) how can we take a mean on that? 
I feel like it has to do something that these might be vector/matrices but I was hoping someone could clarify this up a bit. 
Where are you running your Jupiter notebook at?
I think windows commands assume you are running your notebook locally on your windows machine or windows VM and in case that you are doing that my best guess would be to run last two commands and not first two ones.
In case that you are running your notebook on google cloud and similar platforms just run first two regardless of if you have a windows/Mac/linux machine since that’s running in the cloud. Hopefully that helps!
Hi, @novarac23! I’m new at this, too, so this might not be correct, but reading the docs for the accuracy function:
def accuracy(input:Tensor, targs:Tensor)->Rank0Tensor:
"Computes accuracy with `targs` when `input` is bs * n_classes."
n = targs.shape[0]
input = input.argmax(dim=-1).view(n,-1)
targs = targs.view(n,-1)
return (input==targs).float().mean()
It looks like the == operator is returning not True or False but instead a tensor of numeric values, which are then converted to floats, and then it takes the mean of those floats? I’m not sure what it’s doing to generate the numeric values instead of the boolean values we’d expect from ==, so hopefully someone else will chime in, too.
It’s a Boolean. So we take if they’re the same, it’s 1. If not. It’s 0. Then we sum up all those correct and incorrect predictions, and take the average. This gets us accuracy. Total amount of 1’s / total
2 Likes
Ah, that makes sense! Thanks. 
Sorry to post this again, but I’m hoping someone will have an idea about what I might try to fix this. I’ve since found that if I restart the kernel and set the batch size to 1 (bs=1), I get a different error:
ValueError: Expected more than 1 value per channel when training, got input size torch.Size([1, 4096])
So that makes sense, and it shows that I’m successfully changing the batch size, but changing the batch size does not resolve the memory error.
Here’s my original post:
I’d deeply appreciate any ideas!
@go_go_gadget thank you for the answer!
@muellerzr so accuracy is total_amount_of_correct_predictions/total_amount_of_data_points?
I’m a bit confused by the part where you said we sum up correct and incorrect predictions. Thought it was only the correct ones 
1 Like
That’s at the bottom. Yes your logic is right. Think of it the same as how well you did in an exam
That makes sense! Thank you for answering! 
No problem Glad I could help!
1 Like
Just to clarify (sorry I sometimes can’t let go of these things haha) by at the bottom you mean total_amount_of_data_points?
total_amount_of_data_points = correct + incorrect predictions
Sorry to be annoying with questions ![]()
Yup!  on the nose! and not annoying at all
on the nose! and not annoying at all
2 Likes
Thank you so much!
1 Like
Hi friends!
So I just wrapped up homework for lesson 3. I ended up building an image classifier to recognize genres of a movie based on a movie poster. Accuracy was around 89%  Here’s the dataset: https://www.kaggle.com/neha1703/movie-genre-from-its-poster
Here’s the dataset: https://www.kaggle.com/neha1703/movie-genre-from-its-poster
It took me around 8 hrs to preprocess all of the data to get it to a point where it’s actually usable for a mode. I feel like most of ML work is data engineering
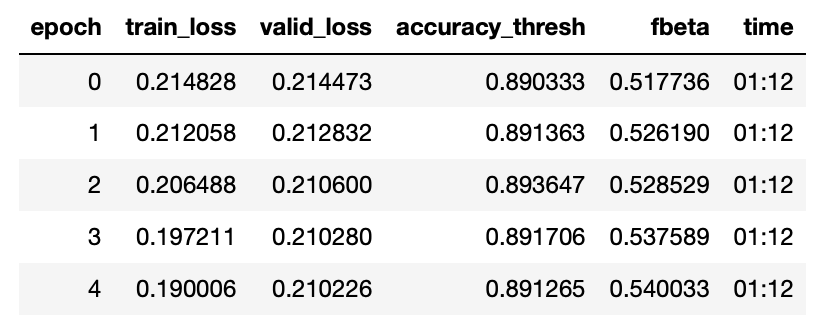
I had a quick question about training/validation loss. Most of my losses up until this homework were roughly below 0.10. However on my homework assignment it was around 0.20 which is not super high but it’s not as low as I’d like it to be. Any ideas on how to debug this? Here’s a screenshot of my losses etc:
Another question I had was regarding plot_losses. After training a bunch, switching infrastructures etc. I still landed around the same accuracy I had before. However when I plotted losses my last model (Resnet 50) here’s the chart that I’ve gotten:
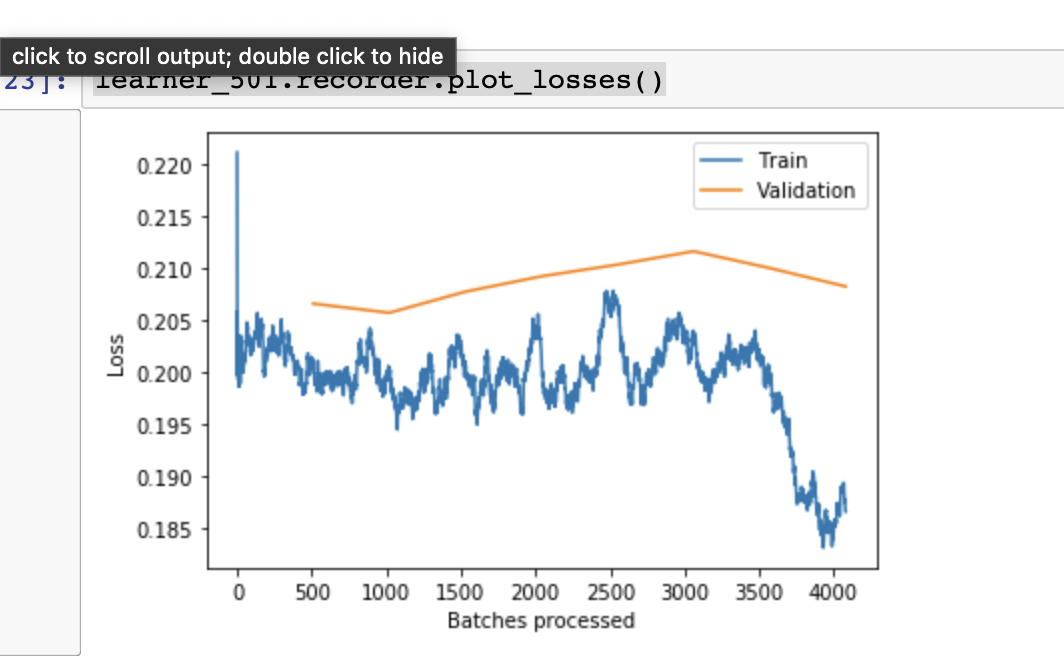
It’s a bit odd that validation loss is not going up first rather it goes down slightly. Any ideas on how to debug that or should I be even worried about it?
AAnnnnnd for fun here’s results after I wrapped up training resnet34, it’s pretty sweet:

1 Like
Hi novarac23 hope you are well.
having created a few image classifiers 89% is not bad.
I am still learning ai/ml and am currently completing apps for the head pose, tabular data, multi segmentation, described in lesson 3.
If it were my model I would check what the winning or highest percentage for accuracy is on Kaggle. Then investigate how they achieved it.
Having read a few papers now on machine learning, it appears that some people do many things to tweak their models, such as feature engineering, trying different algorithms and like you mentioned different models in the transfer learning.
One thing I have noticed is in a pocket watch classifier that I created the images of watches are so similar that for every class I created the value for accuracy went down.
Have a jolly day.
mrffabulous1 
1 Like
Did you ever have any luck with this (creating a classifier for the card game SET)? I’m wondering if I should train four models (shape/color/number/fill) or somehow one. (I’m only on lesson 1). I was just going to assemble a training set manually, and maybe run it through some elements of the barely-working manual approach I tried before: https://github.com/djMax/setbot
Just added this The Universal Approximation Theorem for neural networks video to the wiki of the lesson. It helped me understand it very well as he visualizes everything. Hope it helps you too.
2 Likes
Great find @kelwa!!! That helped make so much sense to me ![]() Thank you!
Thank you!
1 Like
HI kelwa
Great video!
A picture paints a thousand words and video even more!
Cheers mrfabulous1
1 Like