Hi, I tried to figure out downloading the planet kaggle dataset for a while now and it seems the files are no longer available in the format it was before? I can see other data-set but this competition only has 3 mb of files with 2 torrents instead of the actual pictures. I’m not sure how to torrent this as I haven’t used torrent in a long time and my attempts with chrome free software did not work.
Can someone confirm if its just me or what has changed? I could not find any posts in this thread about problems with downloading the data.
Maybe this link above will help. When I did this lesson the files were in the old format.
I went to the new site and had a look and was able to download some files using BitTorrent Classic https://www.bittorrent.com/ on my mac. see image in above post. I am not aware of a way to download the files with anything from Google.
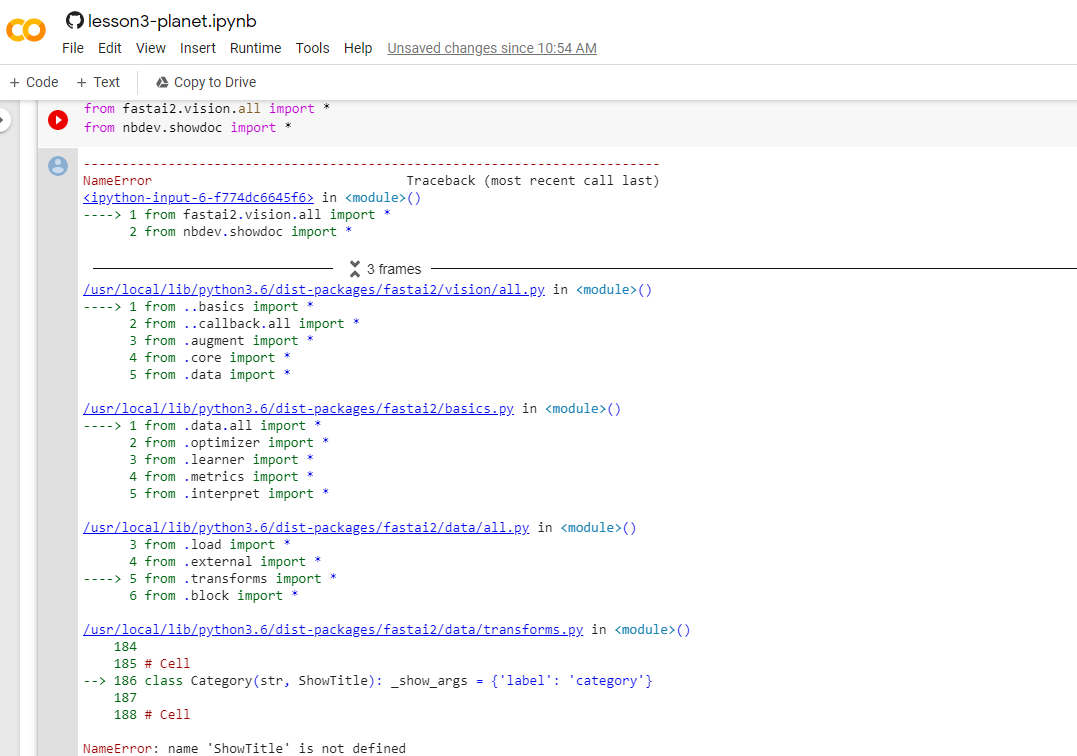
Hi, Can anyone help me with this simple error? I am trying to run the lesson3 notebook on CoLab and when I try to run the cells importing fastai2.vision.all I get the error that “name ‘ShowTitle’ is not defined”. Before running the imports cell, I did run the command “!curl -s https://course.fast.ai/setup/colab | bash” and I also ran the command “pip install fastai2”. I also tried to Reset Runtime but that also didn’t help. Can anyone provide any help or suggestion?
It seems you’re working out of fastai2. If that is intentional then see the v2 intro thread to setting everything up. If not you should be working out of fastai not fastai2
I am running Windows 10 64-bit
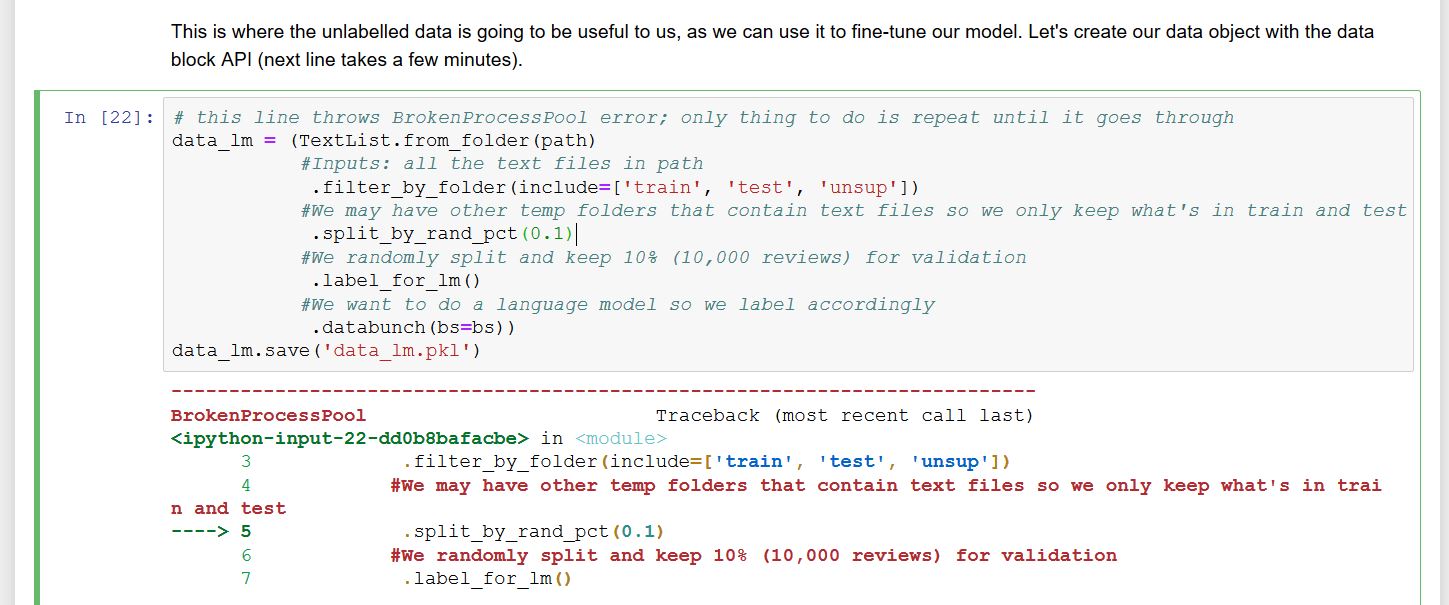
I’d appreciate hearing from anyone who has solved this issue. The BrokenProcessPool error occurs in many different places in the Fastai v1 library. I’ve spent a lot of time trolling the Forum, but have yet to find a post with a viable solution.
I’ve created an annotated and somewhat refactored version of the original lesson3-imdb.ipynb notebook (re-named lesson3-imdb_jcat.ipynb) and posted it here on github.
I had a few problems running the notebook on my Windows-10 64-bit machine.
Almost all blocks of code using Fastai’s data API failed with BrokenProcessPool errors. I discovered that this is a stochastic error – sometimes it fails, sometimes it doesn’t! So I implemented a brute-force approach: just repeatedly try the code block until it runs successfully.
I got a CUDA out of memory error with batch size bs = 48, so I had to change it to bs = 24; this allowed me to get past the error, but then the very last training step (fine tuning) failed with a CUDA out of memory error. At that point I lost patience – the next thing would be to reduce batch size again – bs = 16 or bs = 8 to get the final movie classifier. However, since we saved the pre-fine-tuned version of the model, we still end up with a classifier (albeit a sub-optimal one) to play with. And (spoiler alert) in spite of this, it turns out to be pretty good!
PyTorch doesn’t seem to allow me to use the GPU on my Windows 10 machine. The notebook does complete overnight, but it would probably be much faster on a Linux machine or even on Google Colab.
Update: I re-ran the notebook after reducing batch size from 24 to 16, but this time I got
RuntimeError: cuDNN error: CUDNN_STATUS_EXECUTION_FAILED
at the last step (in section 3.4).
I’m trying to solve s problem at work using a segmentation model, based on lesson 3. My data is a surface model made from aerial laser scanning showing buildings and their surroundings. The segmentation masks marks different types of roofs.
Since my data is a raster representation of height values, it has basically just one channel. I have, however, transformed it to grayscale images.
I’m getting somewhat good, camvid metric ~80%, results I think, based on mu small training set, about 40 images.
But am I on the right path? Is there a better way to deal with this kind of data?
I can use the corresponding aerial photos and add the surface model data as a fourth channel. Can fastai handle that kind of data and how?
Hi Peter I am using LIDAR images which sounds similar. Height as greyscale works just fine. Just 40 training images sounds challenging though. I use 13,000 and got 92 percent. Consider getting more samples.
Functionally it is meant to “reverse” the effect of the first part, which reduces the image dimensions, but the architecture may not be the exact reverse. Like if you adapt resnet34 for the first part, your second part will not be the exact reverse of resnet34.
Houston we got a problem. The train files for the kaggle planet dataset are non downloadable already, we can torrent if ourselves or you can follow the steps.
I hope this is useful for colab users it should work for the rest of the peeps ( minus those colab stuff )
Can someone please explain me that in the head-pose lesson, while we are creating the data bunch, we are writing something like ‘split_by_valid_func(lambda o: o.parent.name==‘13’)’ , so how the lambda function is working here to create a validation dataset for the model?
Thanks in advance.