Hi @jin_and_tonic, Were able to download the file? I have the same problem, no seeders available.
Hi Folks, Hope y’all are doing well.
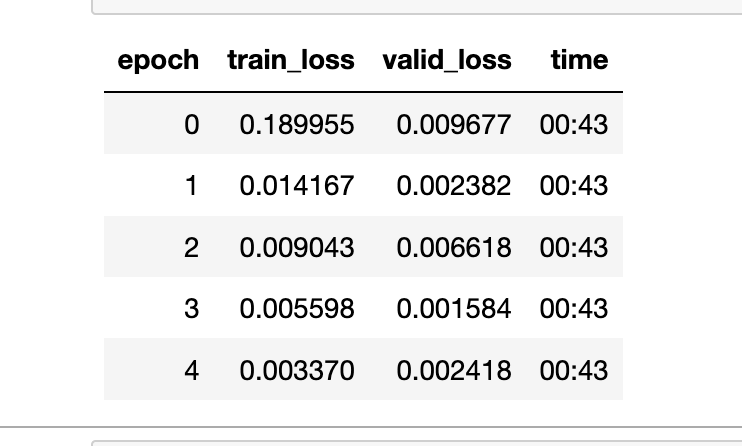
I have this following metrics from training a learner on the BIWI head pose dataset. My training loss is higher that validation loss. I tried to increase the learning rate
(from 2e-2 to 8e-2 ), still behaves the same. Can someone comment on this behavior.
Thanks,
/bin/bash: move: command not found
I am getting this error when I try to execute the following command from Planet competition code in lesson 3:
! mkdir %userprofile%.kaggle
! move kaggle.json %userprofile%.kaggle
What is the issue? Could anyone please help to resolve?
Hi saurabh_wadhawan I hope you are having a beautiful day!
Have you tried mv instead of move 
Cheers mrfabulous1 
Thanks. This worked!
But facing another error now.
! kaggle competitions download -c planet-understanding-the-amazon-from-space -f train-jpg.tar.7z -p {path}
! kaggle competitions download -c planet-understanding-the-amazon-from-space -f train_v2.csv -p {path}
! unzip -q -n {path}/train_v2.csv.zip -d {path}
When I execute these, I get this error:-
Could not find kaggle.json. Make sure it’s located in /root/.kaggle. Or use the environment method… But I have already uploaded kaggle.json
Also, this command doesn’t work:
! conda install --yes --prefix {sys.prefix} -c haasad eidl7zip
Error: /bin/bash: conda: command not found
Kindly help to resolve. Thanks.
Can you try to run only the non-windows commands:
! mkdir -p ~/.kaggle/
! mv kaggle.json ~/.kaggle/
# For Windows, uncomment these two commands
# ! mkdir %userprofile%\.kaggle
# ! move kaggle.json %userprofile%\.kaggle
I believe it should solve your problem.
1 Like
Hi, I’m having trouble creating a databunch for image classification. The dataset is called MIT indoor scenes.
The images are under folders which contain the labels. But the problem is that the file names for which should be taken as train and test set is in a text file. How do I create the data bunch? Please help.
Hi All,
I have tried to do multi-label image classification on the dataset below:
While training for I am getting negative training and validation loss. What is could be going wrong here? I am running on collab.
Thanks
Mainak
The code is available here:
I try to dig deep about mixed training precision - how new it is.
Found at Nvidia docs:
|Model|Speedup| - with Pytorch
|—|---|
|NVIDIA Sentiment Analysis| 4.5X speedup|
|FAIRSeq| 3.5X speedup|
|GNMT| 2X speedup|
|ResNet-50| 2X speedup|
Q: Is Automatic Mixed Precision (AMP) dependent on a PyTorch version or can any PyTorch version enable AMP?
A: AMP with CUDA and CPP extensions requires PyTorch 1.0 or later. The Python-only build might be able to work with PyTorch 0.4, however, 1.0+ is strongly recommended.
https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html#faq-pytorch
My question is concerning the image segmentation lecture in lesson 3. I have created my own datasets. How are you able to determine the number of neurons that are in your input layer of the Neural Network? Saying that the train data:
ImageDataBunch;
Train: LabelList (160 items)
x: SegmentationItemList
Image (3, 128, 128),Image (3, 128, 128),Image (3, 128, 128),Image (3, 128, 128),Image (3, 128, 128)
y: SegmentationLabelList
ImageSegment (1, 128, 128),ImageSegment (1, 128, 128),ImageSegment (1, 128, 128),ImageSegment (1, 128, 128),ImageSegment (1, 128, 128)
Unfortunately it looks like the file train–jpg.tar is no longer listing in Kaggle’s download API.
You can see it from here !kaggle competitions files -c planet-understanding-the-amazon-from-space
def acc_camvid(input, target):
target = target.squeeze(1)
mask = target != void_code
return (input.argmax(dim=1)[mask]==target[mask]).float().mean()
Can someone explain to me how this function works in detail?
Hi, I’m untar the data of IMDB but only test data is there in the folder
Can anyone explain why?
Is there some changes in the URLs.IMDB?
I’ve been trying to make a text classifier model on the Spooky Author Identification competition dataset, but I haven’t really been able to get anywhere close to a good model. Every time I try to train it, my validation loss quickly outpaces my training loss, which seems to be a sign of overfitting(?) Also, I’ve been using text_classifier_learner, but should I actually be using language_model_learner instead?
I started working on global wheat detection data from kaggle. I’m trying to get familiar with datablock api.The data is placed in several folders, as shown in the train_csv_path , which has image-ids and the dependent variable and a folder containing images labelled under train . The path one random image is shown in the code below as train_images_path . I tried to create a databunch using the following code.
base_path='/kaggle/input/global-wheat-detection'
train_csv_path='../input/global-wheat-detection/train.csv'
train_images_path='../input/global-wheat-detection/train/00333207f.jpg'
train_df=pd.read_csv(os.path.join(base_path,'train.csv'))
src=(ImageList.from_df(train_df,base_path).split_by_idx(list(range(122787,147793))).label_from_df(label_delim=' '))
data=(src.transform(tfms,size=1024).databunch().normalize(imagenet_stats))
following error occured when I ran data
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
<ipython-input-125-892ab3edbe69> in <module>
----> 1 data=(src.transform(tfms,size=1024).databunch().normalize(imagenet_stats))
/opt/conda/lib/python3.7/site-packages/fastai/data_block.py in transform(self, tfms, **kwargs)
507 if not tfms: tfms=(None,None)
508 assert is_listy(tfms) and len(tfms) == 2, "Please pass a list of two lists of transforms (train and valid)."
--> 509 self.train.transform(tfms[0], **kwargs)
510 self.valid.transform(tfms[1], **kwargs)
511 if self.test: self.test.transform(tfms[1], **kwargs)
/opt/conda/lib/python3.7/site-packages/fastai/data_block.py in transform(self, tfms, tfm_y, **kwargs)
726 def transform(self, tfms:TfmList, tfm_y:bool=None, **kwargs):
727 "Set the `tfms` and `tfm_y` value to be applied to the inputs and targets."
--> 728 _check_kwargs(self.x, tfms, **kwargs)
729 if tfm_y is None: tfm_y = self.tfm_y
730 tfms_y = None if tfms is None else list(filter(lambda t: getattr(t, 'use_on_y', True), listify(tfms)))
/opt/conda/lib/python3.7/site-packages/fastai/data_block.py in _check_kwargs(ds, tfms, **kwargs)
595 if (tfms is None or len(tfms) == 0) and len(kwargs) == 0: return
596 if len(ds.items) >= 1:
--> 597 x = ds[0]
598 try: x.apply_tfms(tfms, **kwargs)
599 except Exception as e:
/opt/conda/lib/python3.7/site-packages/fastai/data_block.py in __getitem__(self, idxs)
118 "returns a single item based if `idxs` is an integer or a new `ItemList` object if `idxs` is a range."
119 idxs = try_int(idxs)
--> 120 if isinstance(idxs, Integral): return self.get(idxs)
121 else: return self.new(self.items[idxs], inner_df=index_row(self.inner_df, idxs))
122
/opt/conda/lib/python3.7/site-packages/fastai/vision/data.py in get(self, i)
269 def get(self, i):
270 fn = super().get(i)
--> 271 res = self.open(fn)
272 self.sizes[i] = res.size
273 return res
/opt/conda/lib/python3.7/site-packages/fastai/vision/data.py in open(self, fn)
265 def open(self, fn):
266 "Open image in `fn`, subclass and overwrite for custom behavior."
--> 267 return open_image(fn, convert_mode=self.convert_mode, after_open=self.after_open)
268
269 def get(self, i):
/opt/conda/lib/python3.7/site-packages/fastai/vision/image.py in open_image(fn, div, convert_mode, cls, after_open)
396 with warnings.catch_warnings():
397 warnings.simplefilter("ignore", UserWarning) # EXIF warning from TiffPlugin
--> 398 x = PIL.Image.open(fn).convert(convert_mode)
399 if after_open: x = after_open(x)
400 x = pil2tensor(x,np.float32)
/opt/conda/lib/python3.7/site-packages/PIL/Image.py in open(fp, mode)
2876
2877 if filename:
-> 2878 fp = builtins.open(filename, "rb")
2879 exclusive_fp = True
2880
FileNotFoundError: [Errno 2] No such file or directory: '/kaggle/input/global-wheat-detection/b6ab77fd7'`
I think the reason is I somehow couldn’t provide a link to match Image-ids from train.csv file to the set of images in the train folder. Can someone please help me to establish that link? TIA.
Edit: I’m running the code on Kaggle kernel
yes. How did you unzip train-torrent files?
Hi! I’m running through the notebooks and I’ve encountered an error that I can’t fix in the head pose notebook… I’ve tried on both Google Colab and Kaggle, but the error is the same:
Whenever I run the notebook there’s an error message at the data part of head pose:
Entered code:
data = (PointsItemList.from_folder(path)
.split_by_valid_func(lambda o: o.parent.name==‘13’)
.label_from_func(get_ctr)
.transform(get_transforms(), tfm_y=True, size=(120,160))
.databunch(num_workers=0).normalize(imagenet_stats)
)
data.show_batch(3, figsize=(9,6))
Error:
RuntimeError Traceback (most recent call last)
in
----> 1 data.show_batch(3, figsize=(9,6))
/opt/conda/lib/python3.7/site-packages/fastai/basic_data.py in show_batch(self, rows, ds_type, reverse, **kwargs)
184 def show_batch(self, rows:int=5, ds_type:DatasetType=DatasetType.Train, reverse:bool=False, **kwargs)->None:
185 “Show a batch of data inds_typeon a fewrows.”
→ 186 x,y = self.one_batch(ds_type, True, True)
187 if reverse: x,y = x.flip(0),y.flip(0)
188 n_items = rows **2 if self.train_ds.x._square_show else rows
/opt/conda/lib/python3.7/site-packages/fastai/basic_data.py in one_batch(self, ds_type, detach, denorm, cpu)
167 w = dl.num_workers
168 dl.num_workers = 0
→ 169 try: x,y = next(iter(dl))
170 finally: dl.num_workers = w
171 if detach: x,y = to_detach(x,cpu=cpu),to_detach(y,cpu=cpu)
/opt/conda/lib/python3.7/site-packages/fastai/basic_data.py in iter(self)
73 def iter(self):
74 “Process and returns items fromDataLoader.”
—> 75 for b in self.dl: yield self.proc_batch(b)
76
77 @classmethod
/opt/conda/lib/python3.7/site-packages/torch/utils/data/dataloader.py in next(self)
343
344 def next(self):
→ 345 data = self._next_data()
346 self._num_yielded += 1
347 if self._dataset_kind == _DatasetKind.Iterable and \
/opt/conda/lib/python3.7/site-packages/torch/utils/data/dataloader.py in _next_data(self)
383 def _next_data(self):
384 index = self._next_index() # may raise StopIteration
→ 385 data = self._dataset_fetcher.fetch(index) # may raise StopIteration
386 if self._pin_memory:
387 data = _utils.pin_memory.pin_memory(data)
/opt/conda/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py in fetch(self, possibly_batched_index)
42 def fetch(self, possibly_batched_index):
43 if self.auto_collation:
—> 44 data = [self.dataset[idx] for idx in possibly_batched_index]
45 else:
46 data = self.dataset[possibly_batched_index]
/opt/conda/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py in (.0)
42 def fetch(self, possibly_batched_index):
43 if self.auto_collation:
—> 44 data = [self.dataset[idx] for idx in possibly_batched_index]
45 else:
46 data = self.dataset[possibly_batched_index]
/opt/conda/lib/python3.7/site-packages/fastai/data_block.py in getitem(self, idxs)
658 x = x.apply_tfms(self.tfms, **self.tfmargs)
659 if hasattr(self, ‘tfms_y’) and self.tfm_y and self.item is None:
→ 660 y = y.apply_tfms(self.tfms_y, **{**self.tfmargs_y, ‘do_resolve’:False})
661 if y is None: y=0
662 return x,y
/opt/conda/lib/python3.7/site-packages/fastai/vision/image.py in apply_tfms(self, tfms, do_resolve, xtra, size, resize_method, mult, padding_mode, mode, remove_out)
121 if resize_method in (ResizeMethod.CROP,ResizeMethod.PAD):
122 x = tfm(x, size=_get_crop_target(size,mult=mult), padding_mode=padding_mode)
→ 123 else: x = tfm(x)
124 return x.refresh()
125
/opt/conda/lib/python3.7/site-packages/fastai/vision/image.py in call(self, x, *args, **kwargs)
522 def call(self, x:Image, *args, **kwargs)->Image:
523 “Randomly execute our tfm onx.”
→ 524 return self.tfm(x, *args, **{**self.resolved, **kwargs}) if self.do_run else x
525
526 def _resolve_tfms(tfms:TfmList):
/opt/conda/lib/python3.7/site-packages/fastai/vision/image.py in call(self, p, is_random, use_on_y, *args, **kwargs)
468 def call(self, *args:Any, p:float=1., is_random:bool=True, use_on_y:bool=True, **kwargs:Any)->Image:
469 “Calc now ifargspassed; else create a transform called probpifrandom.”
→ 470 if args: return self.calc(*args, **kwargs)
471 else: return RandTransform(self, kwargs=kwargs, is_random=is_random, use_on_y=use_on_y, p=p)
472
/opt/conda/lib/python3.7/site-packages/fastai/vision/image.py in calc(self, x, *args, **kwargs)
473 def calc(self, x:Image, *args:Any, **kwargs:Any)->Image:
474 “Apply to imagex, wrapping it if necessary.”
→ 475 if self._wrap: return getattr(x, self._wrap)(self.func, *args, **kwargs)
476 else: return self.func(x, *args, **kwargs)
477
/opt/conda/lib/python3.7/site-packages/fastai/vision/image.py in pixel(self, func, *args, **kwargs)
304 def pixel(self, func:PixelFunc, *args, **kwargs)->‘ImagePoints’:
305 “Equivalent toself = func_flow(self).”
→ 306 self = func(self, *args, **kwargs)
307 self.transformed=True
308 return self
/opt/conda/lib/python3.7/site-packages/fastai/vision/transform.py in _flip_lr(x)
65 #return x.flip(2)
66 if isinstance(x, ImagePoints):
—> 67 x.flow.flow[…,0] *= -1
68 return x
69 return tensor(np.ascontiguousarray(np.array(x)[…,::-1]))
/opt/conda/lib/python3.7/site-packages/fastai/vision/image.py in flow(self)
281 “Access the flow-field grid after applying queued affine and coord transforms.”
282 if self._affine_mat is not None:
→ 283 self._flow = _affine_inv_mult(self._flow, self._affine_mat)
284 self._affine_mat = None
285 self.transformed = True
/opt/conda/lib/python3.7/site-packages/fastai/vision/image.py in _affine_inv_mult(c, m)
572 c.flow = c.flow.view(-1,2)
573 a = torch.inverse(m[:2,:2].t())
→ 574 c.flow = torch.mm(c.flow - m[:2,2], a).view(size)
575 return c
576
RuntimeError: Expected object of scalar type Double but got scalar type Float for argument #3 ‘mat2’ in call to _th_addmm_out
Any help would be appreciated! Thanks! ![]()
I have already trained the model , and I have test data also ready , its an object detection model retinanet trained on midog 2021 challenge dataset.
I need various evaluation metrics for my model based on iou thresholding on bounding boxes predictions of model over ground truth bounding boxes(classic MSCOCO format object detection to classification evals)
This is my sample code:
train, valid ,test = ObjectItemListSlide(train_images), ObjectItemListSlide(valid_images), ObjectItemListSlide(test_images)
item_list = ItemLists(".", train, valid)
lls = item_list.label_from_func(lambda x: x.y, label_cls=SlideObjectCategoryList)
lls = lls.transform(tfms, tfm_y=True, size=patch_size)
data = lls.databunch(bs=batch_size, collate_fn=bb_pad_collate,num_workers=0).normalize()
learn = Learner(data, model, loss_func=crit,
callback_fns=[ShowGraph,CSVLogger,partial(GradientClipping, clip=2.0)])
learn.split([model.encoder[6], model.c5top5])
learn.freeze_to(-2)
learn.load('trained_model_bs64_GC',with_opt=True)
#test_data
item_list_t = ItemLists(".", train, test)
lls_t = item_list.label_from_func(lambda x: x.y, label_cls=SlideObjectCategoryList)
lls_t = lls_t.transform(tfms, tfm_y=True, size=patch_size)
data_t= lls_t.databunch(bs=batch_size, collate_fn=bb_pad_collate,num_workers=0).normalize()
detect_thresh = 0.5
nms_thresh = 0.2
image_count=15
show_results_side_by_side(learn, anchors, detect_thresh=detect_thresh, nms_thresh=nms_thresh, image_count=image_count)
I can see the results after the last function but its just prediction of box over with score over random patches of my data ,
I need the precision,recall, accuracy , confusion matrix ,roc auc curve ,etc, on all the test images . The metric for classification is iou =0.5 over the bounding box if the bounding boxe predicted by machine has iou >0.5 it is to be considered as true positive for positive ground truth, and vice versa.
Can you please share a notebook on how can I perform such an evaluation of model? Any kind of notebooks, resources, code snippets are welcome.
Thanking all of you for the great support on this wonderful platform.
You can mail me, or message me on this forum, all suggestions are really welcome.
Warm regards,
Harshit
Harshit_joshi@iiitb.ac.in
If train loss is less than your val loss than there’s good chance that your training and validation dataset have different distributions. By distribution I mean the ‘kind’ of data present in each of those sets; for instance, if training set has lots of black dog images and validation set has lots of brown dog images.