I resolved it with this.
!pip install torch_nightly -f https://download.pytorch.org/whl/nightly/cu92/torch_nightly.html
!pip install fastai
I resolved it with this.
!pip install torch_nightly -f https://download.pytorch.org/whl/nightly/cu92/torch_nightly.html
!pip install fastai
I am new, so not sure this is right way to share info, but I faced to same issue, then search the forum and get this comment at the first.
In my case, the cause of the issue was that the notebook did not import the module.
Put the from fastai.datasets import Config before running path = Config.data_path()/'planet, then everything worked fine.
Hope it helps other guys
I upgraded pandas lib to 0.24.2 ( it was 0.22.x ) and the error went away.
I guess this is the effect of the one cycle policy on each epoch.
You can call it a U-Resnet  You will not exactly initialize with a resnet, you will create a new network that is very similar to Resnet in encoding pass, but saves the activations on some steps so that you can concat them with the input in the decode pass. There is a lesson in dl2 2018 about that. It is about segmentation on carvana dataset. Check the video.
You will not exactly initialize with a resnet, you will create a new network that is very similar to Resnet in encoding pass, but saves the activations on some steps so that you can concat them with the input in the decode pass. There is a lesson in dl2 2018 about that. It is about segmentation on carvana dataset. Check the video.
In the head-pose regression problem, why was a size of 120 by 160 selected? Why these specific numbers and why is it a rectangle rather than a square?
Moreover, what exactly is the output of the model?
I tried to do:
pred = learner.predict(data.valid_ds.x[0])
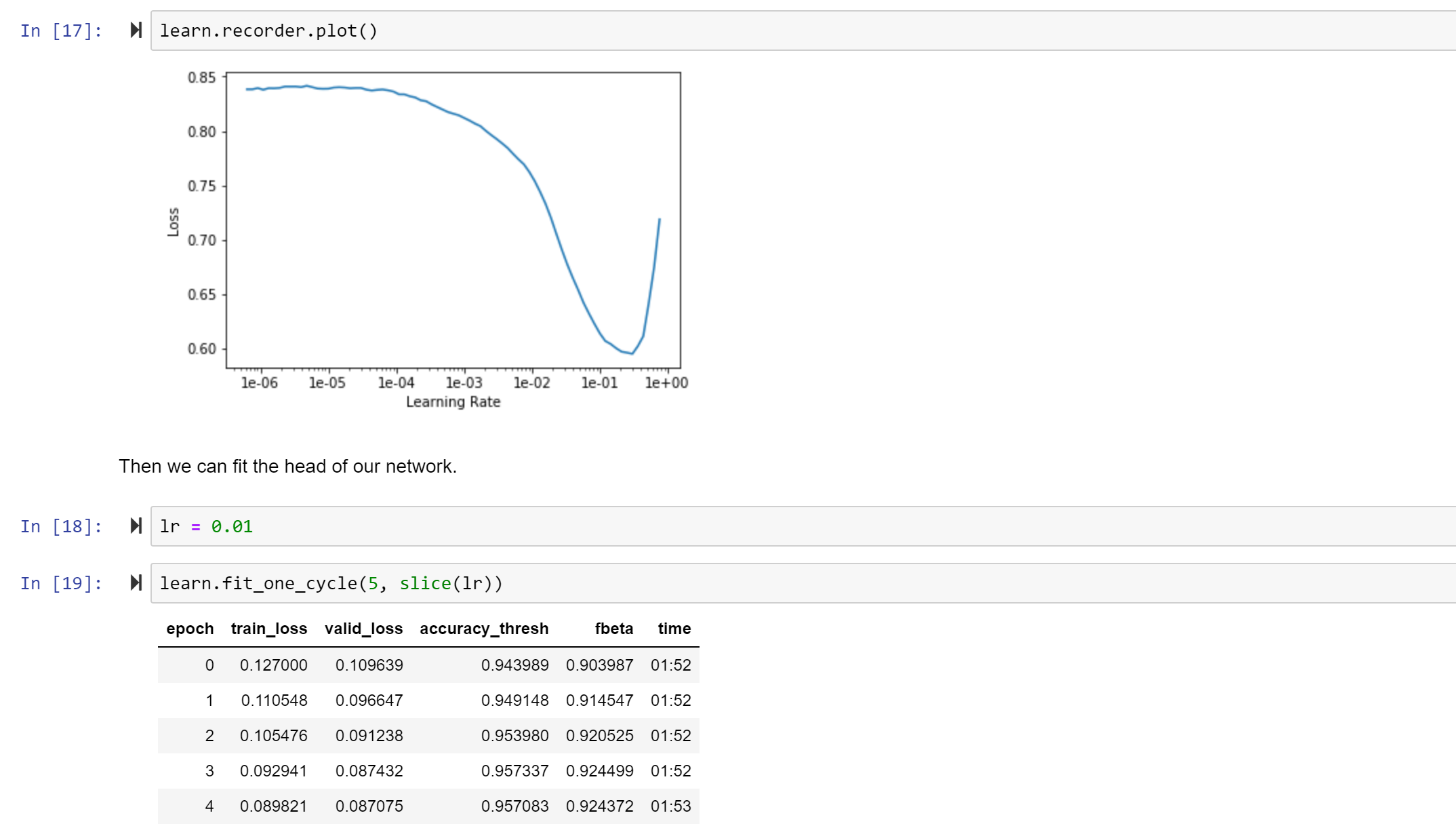
The output was:
(ImagePoints (120, 160), tensor([[0.0895, 0.0582]]), tensor([0.0895, 0.0582]))
How do I interpret this? and why is the last item in this tuple equal to the second one?
I also tried to visualize this for a single image without using a the learner.show_results() method; however, I couldn’t do so.
I tried data.valid_ds.x[0].show(y=pred[0], figsize=(9, 9)) But the red point showed in some random spot of the image.
Also tried this and the result didn’t make sense either:
data.valid_ds.x[0].show(y=get_ip(data.valid_ds.x[0], pred[1]), figsize=(9, 9))
I have been running in out of memory for the planet lesson, but changed it to
data = (src.transform(tfms, size=256)
.databunch(bs=32).normalize(imagenet_stats))
I have like 6GB of mem
| 0 4951 C ...tyoc213/anaconda3/envs/swift/bin/python 5057MiB |
This is with 32, the questions are the batch size should be in powers of 2? and is possible to know before hand that I will get out of memory? or until I run and hit the problem? how many memory do I need for run this on the default size of 64?
I have problem with “to_fp16()”, in the class Howard said that this trick will help in case of running out of memory. What happened with me is the opposite, whenever I use fp16 I have to restart the notebook every time I run “fit_one_cycle” or it will show me an error message of not enough memory (collecting the garbage and setting the learner to False was not enough). Whereas, using the regular precision I can do “unfreeze” and “fit_one_cycle” indefinitely without requiring me to restart the notebook.
I am using Cuda version is 10.1.105 and 418.56 graphics card driver, OS is Ubuntu 16.04
I have Titan V with 12GB
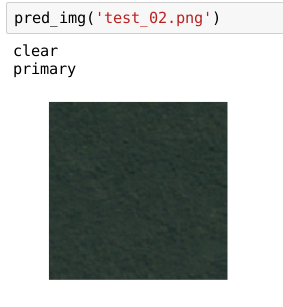
It took me about an hour and a half. But i managed to finally figure out how to do a prediction on a single image with a multi class label. I’m not sure if it’ll work this way on all the classes but it definitely worked for me on the planet data set.
def pred_img(img_path, learn=learn, data=data, thresh=.2):
img = open_image(img_path)
c = data.c
pred = learn.predict(img)[2] > thresh
for i in range(c):
if pred[i]==1:
print(data.classes[i])
img.show()
Here’s how it looks when I run it.
I’m noticing in the image segmentation example when using learn.show_results() with a requested row size in the arguments that the actual number of rows of images displayed doesn’t match the requested number of rows. There seems to be an upper bound it never goes past (e.g. never more than 2 or 3 rows displayed no matter the number requested). Is this normal behavior?
path = Config.data_path()/‘planet’
path.mkdir(parents=True, exist_ok=True)
path
When we run the above code on Google Colab, it makes a directory named ‘planet’. But I can’t seem to find out where is the directory? I go on the left side panel and see under the Files section but nothing is created. When I run !ls, still it shows that no files are created. When I run ‘path’ it shows me :- PosixPath(’/root/.fastai/data/planet’). I am totally confused here about where is this ‘planet’ folder guy? Can anyone please guide me through this maze.
I still can’t understand how the model adapt? Can u elaborate?
Can you tell me where is it ? :D.
On google colab, for the planets example, I’m getting google drive timed out errors. I’ve been saving all my training data in
root_dir = "/content/gdrive/My Drive/planets"
but on lines like the following
data = (src.transform(tfms, size=128)
.databunch().normalize(imagenet_stats))
I’ve been getting messages from google drive saying timed out.
Has anyone else encountered this and come up with a workaround?
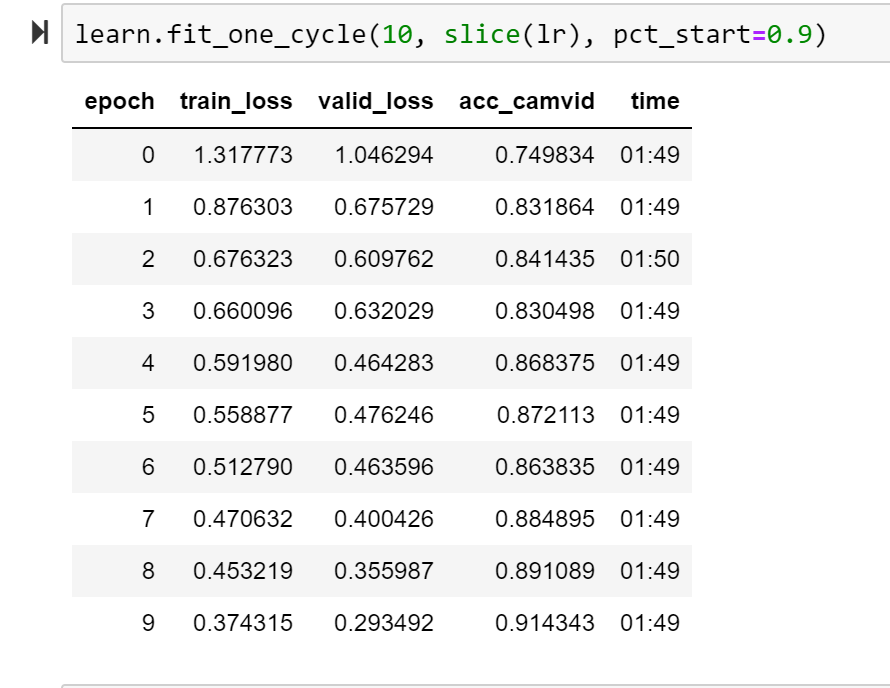
What does the batch display on camvid? Is it displaying 2 images that have the same colour coding? And if we have previously color coded images on camvid dataset, then what are trying to achieve using classification on this dataset?
colab’s file browser is not showing hidden folders (like /root/.fastai). But you should be able to do something like this in the notebook itself and list its contents.
! ls {path}??accuracy_thresh
Signature: accuracy_thresh(
y_pred:torch.Tensor,
y_true:torch.Tensor,
thresh:float=0.5,
sigmoid:bool=True)
sigmoid is defaulting to true and this looks suspicious. I see the solution to this problem listed elsewhere. Adding a note here so that people can find it more easily.
Planet problem
With sigmoid=True and running 2 epochs, fbeta=0.919897.
With sigmoid=False and running 2 epochs fbeta=0.877486.
I was wondering if anyone has used the ADE20K dataset. I’m not understanding how things are labeled and posted a question on stack overflow. https://stackoverflow.com/questions/56635061/ade20k-dataset-label-issue
Anyways, if anyone has any experience with ADE20K and can give some insight, it would be much appreciated.
In case anyone has the same issue, google drive does not do well with lots of images. Its best to copy the images to the google colab file system
In GCP mine is also slow too but in the lesson 3 planet notebook.
It took 10 minutes with tesla P4 gpu on gcp (normal config) instead of 3 minutes 30 sec shown on the notebook.
watch -n0.1 nvidia-smi
Add: For the camvid notebook the result is also slow too!
If anyone have a way to speed this up feel free to share!!