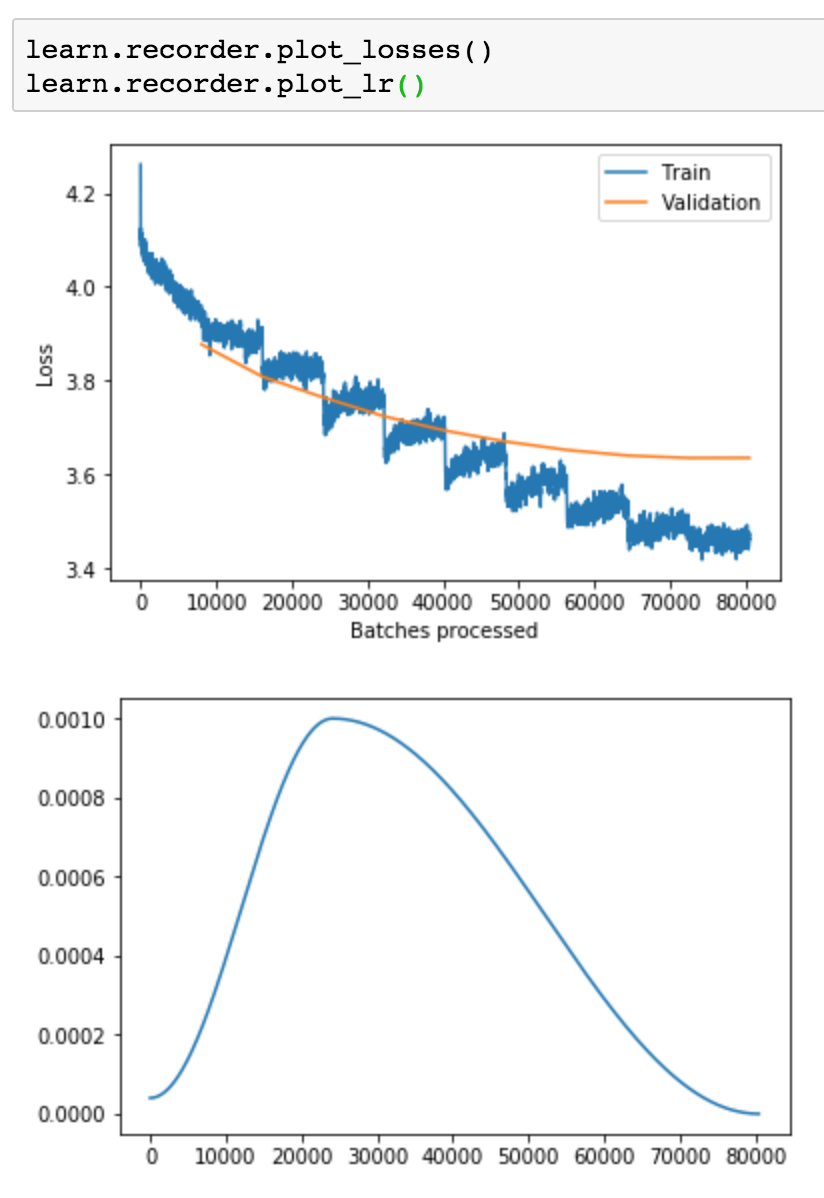
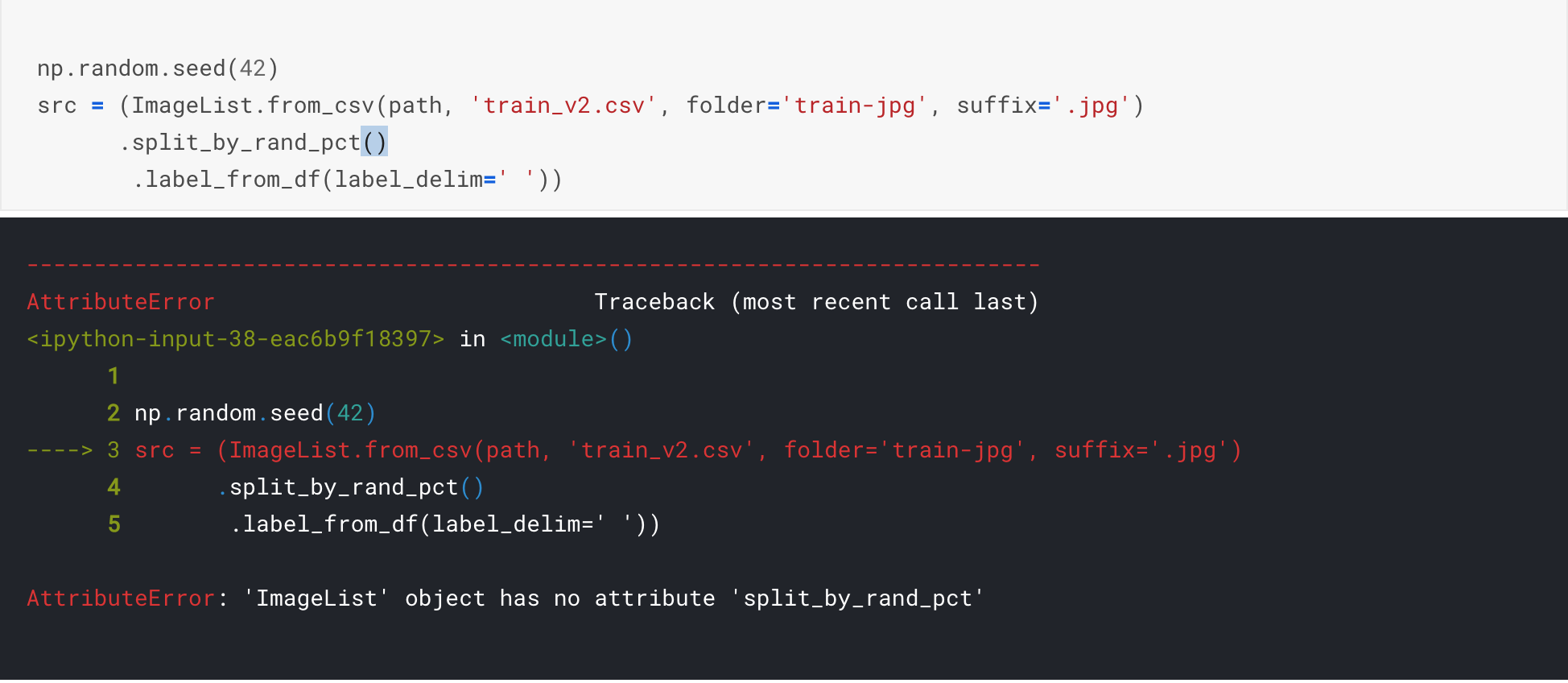
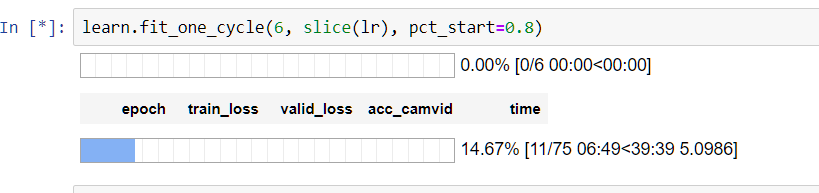
I am doing the planet example from less3-planet notebook. Just training the model with resnet50 and getting below error. Not sure if something changed in the API internally which is breaking it.
learn.fit_one_cycle(5, slice(lr))
0.00% [0/5 00:00<00:00]
epoch train_loss valid_loss accuracy_thresh fbeta
Interrupted
RuntimeError Traceback (most recent call last)
in ()
----> 1 learn.fit_one_cycle(5, slice(lr))
~/.anaconda3/lib/python3.7/site-packages/fastai/train.py in fit_one_cycle(learn, cyc_len, max_lr, moms, div_factor, pct_start, wd, callbacks, **kwargs)
19 callbacks.append(OneCycleScheduler(learn, max_lr, moms=moms, div_factor=div_factor,
20 pct_start=pct_start, **kwargs))
—> 21 learn.fit(cyc_len, max_lr, wd=wd, callbacks=callbacks)
22
23 def lr_find(learn:Learner, start_lr:Floats=1e-7, end_lr:Floats=10, num_it:int=100, stop_div:bool=True, **kwargs:Any):
~/.anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in fit(self, epochs, lr, wd, callbacks)
164 callbacks = [cb(self) for cb in self.callback_fns] + listify(callbacks)
165 fit(epochs, self.model, self.loss_func, opt=self.opt, data=self.data, metrics=self.metrics,
–> 166 callbacks=self.callbacks+callbacks)
167
168 def create_opt(self, lr:Floats, wd:Floats=0.)->None:
~/.anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in fit(epochs, model, loss_func, opt, data, callbacks, metrics)
92 except Exception as e:
93 exception = e
—> 94 raise e
95 finally: cb_handler.on_train_end(exception)
96
~/.anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in fit(epochs, model, loss_func, opt, data, callbacks, metrics)
87 if hasattr(data,‘valid_dl’) and data.valid_dl is not None and data.valid_ds is not None:
88 val_loss = validate(model, data.valid_dl, loss_func=loss_func,
—> 89 cb_handler=cb_handler, pbar=pbar)
90 else: val_loss=None
91 if cb_handler.on_epoch_end(val_loss): break
~/.anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in validate(model, dl, loss_func, cb_handler, pbar, average, n_batch)
52 if not is_listy(yb): yb = [yb]
53 nums.append(yb[0].shape[0])
—> 54 if cb_handler and cb_handler.on_batch_end(val_losses[-1]): break
55 if n_batch and (len(nums)>=n_batch): break
56 nums = np.array(nums, dtype=np.float32)
~/.anaconda3/lib/python3.7/site-packages/fastai/callback.py in on_batch_end(self, loss)
237 “Handle end of processing one batch with loss.”
238 self.state_dict[‘last_loss’] = loss
–> 239 stop = np.any(self(‘batch_end’, not self.state_dict[‘train’]))
240 if self.state_dict[‘train’]:
241 self.state_dict[‘iteration’] += 1
~/.anaconda3/lib/python3.7/site-packages/fastai/callback.py in call(self, cb_name, call_mets, **kwargs)
185 def call(self, cb_name, call_mets=True, **kwargs)->None:
186 “Call through to all of the CallbakHandler functions.”
–> 187 if call_mets: [getattr(met, f’on_{cb_name}’)(**self.state_dict, **kwargs) for met in self.metrics]
188 return [getattr(cb, f’on_{cb_name}’)(**self.state_dict, **kwargs) for cb in self.callbacks]
189
~/.anaconda3/lib/python3.7/site-packages/fastai/callback.py in (.0)
185 def call(self, cb_name, call_mets=True, **kwargs)->None:
186 “Call through to all of the CallbakHandler functions.”
–> 187 if call_mets: [getattr(met, f’on_{cb_name}’)(**self.state_dict, **kwargs) for met in self.metrics]
188 return [getattr(cb, f’on_{cb_name}’)(**self.state_dict, **kwargs) for cb in self.callbacks]
189
~/.anaconda3/lib/python3.7/site-packages/fastai/callback.py in on_batch_end(self, last_output, last_target, **kwargs)
272 if not is_listy(last_target): last_target=[last_target]
273 self.count += last_target[0].size(0)
–> 274 self.val += last_target[0].size(0) * self.func(last_output, *last_target).detach().cpu()
275
276 def on_epoch_end(self, **kwargs):
~/.anaconda3/lib/python3.7/site-packages/fastai/metrics.py in accuracy_thresh(y_pred, y_true, thresh, sigmoid)
20 “Compute accuracy when y_pred and y_true are the same size.”
21 if sigmoid: y_pred = y_pred.sigmoid()
—> 22 return ((y_pred>thresh)==y_true.byte()).float().mean()
23
24 def dice(input:FloatTensor, targs:LongTensor, iou:bool=False)->Rank0Tensor:
RuntimeError: The size of tensor a (418) must match the size of tensor b (64) at non-singleton dimension 1