I’m getting a strange error related to displaying DataFrames inside of the fastai Conda environment I’ve created.
The following occurs when calling df.head():
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
~/anaconda3/envs/fastaiv3/lib/python3.7/site-packages/IPython/core/formatters.py in __call__(self, obj)
343 method = get_real_method(obj, self.print_method)
344 if method is not None:
--> 345 return method()
346 return None
347 else:
~/anaconda3/envs/fastaiv3/lib/python3.7/site-packages/pandas/core/frame.py in _repr_html_(self)
647 # display HTML, so this check can be removed when support for
648 # IPython 2.x is no longer needed.
--> 649 if console.in_qtconsole():
650 # 'HTML output is disabled in QtConsole'
651 return None
~/anaconda3/envs/fastaiv3/lib/python3.7/site-packages/pandas/io/formats/console.py in in_qtconsole()
121 ip.config.get('KernelApp', {}).get('parent_appname', "") or
122 ip.config.get('IPKernelApp', {}).get('parent_appname', ""))
--> 123 if 'qtconsole' in front_end.lower():
124 return True
125 except NameError:
AttributeError: 'LazyConfigValue' object has no attribute 'lower'
I’ve tried printing Pandas dataframes in notebook in other virtual environments on my machine and it works, so I’m not sure what’s going on here.
I’m working on a local machine on Ubuntu 18.04 and I have pulled the latest version of the repo and updated everything.
I’m not clear on something in the IMDB nb. @lesscomfortable I’m hoping you can explain it for me!
In the following part, is the second line of code (data_lm = TextLMDataBunch.load(path, ‘tmp_lm’, bs=bs)) changing data_lm in any way? I don’t believe it does, but am not sure.
data_lm = (TextList.from_folder(path)
#Inputs: all the text files in path
.filter_by_folder(include=['train', 'test', 'unsup'])
#We may have other temp folders that contain text files so we only keep what's in train and test
.random_split_by_pct(0.1)
#We randomly split and keep 10% (10,000 reviews) for validation
.label_for_lm()
#We want to do a language model so we label accordingly
.databunch(bs=bs))
data_lm.save('tmp_lm')
We have to use a special kind of TextDataBunch for the language model, that ignores the labels (that’s why we put 0 everywhere), will shuffle the texts at each epoch before concatenating them all together (only for training, we don’t shuffle for the validation set) and will send batches that read that text in order with targets that are the next word in the sentence.
The line before being a bit long, we want to load quickly the final ids by using the following cell.
In the comment about “The line before being a bit long” I don’t know if “long” refers to execution time or the just the number of lines of code. That first line that creates data_lm runs fairly quickly, so I don’t really see what’s being gained by the second line that creates data_lm using TextLMDataBunch.
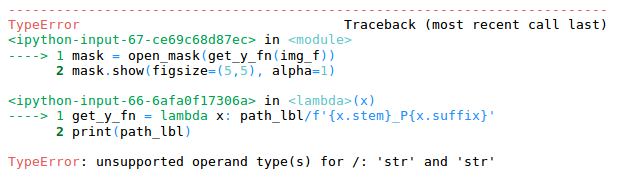
Getting a bunch of errors with Lesson 3, I’m on the planet kaggle.
Showing df results in the following error:
AttributeError Traceback (most recent call last)
D:\Anaconda3\envs\fastai_v3\lib\site-packages\IPython\core\formatters.py in __call__(self, obj)
343 method = get_real_method(obj, self.print_method)
344 if method is not None:
--> 345 return method()
346 return None
347 else:
D:\Anaconda3\envs\fastai_v3\lib\site-packages\pandas\core\frame.py in _repr_html_(self)
647 # display HTML, so this check can be removed when support for
648 # IPython 2.x is no longer needed.
--> 649 if console.in_qtconsole():
650 # 'HTML output is disabled in QtConsole'
651 return None
D:\Anaconda3\envs\fastai_v3\lib\site-packages\pandas\io\formats\console.py in in_qtconsole()
121 ip.config.get('KernelApp', {}).get('parent_appname', "") or
122 ip.config.get('IPKernelApp', {}).get('parent_appname', ""))
--> 123 if 'qtconsole' in front_end.lower():
124 return True
125 except NameError:
AttributeError: 'LazyConfigValue' object has no attribute 'lower'
Then, in the next cell when you define src, after the np.random.seed(42) you get the following error that ends with:
Exception: Your validation data contains a label that isn't present in the training set, please fix your data.
Can anyone help?
I’ve also noticed many differences between the code in the 2019 MOOC and the current code in the github repo. Is that intentional? I tried running the exact commands on the MOOC video, but ImageFileList does not appear to be a valid command?
I’m trying to train hand Segmentation for a new dataset (Egohands). However, I always get CUDA out of memory even with P100 (16Gb GPU). The error appear with even very small image size and batch size
size = src_size//32
bs=2
The original image shape is (1280,720)
Can someone suggest me how to deal with it ? Thank you in advance
Hey! The idea behind load is not to have write all that chunk of code and re-create the databunch object every time you want to use it. It is both a computation and code thing. You don’t want to do the same thing twice, if you can avoid it.
To your question, it is not changing data_lm in the same way that loading a model from saved weights does not change the Learner object. However, say you ran it yesterday, created the databunch object and want to run it again today. In that case, there will be nothing to overwrite, in other words no data_lm to change. You will use .load and that will load the same databunch you created yesterday with less computation time and less lines of code.
Hey guys! Can anyone advice if I can use lesson3-head-pose.ipynb notebook flow to find several faces on a picture? So each picture will be labeled with multidimensional tensor. Will it be possible if there will be a different amount of faces on each picture?
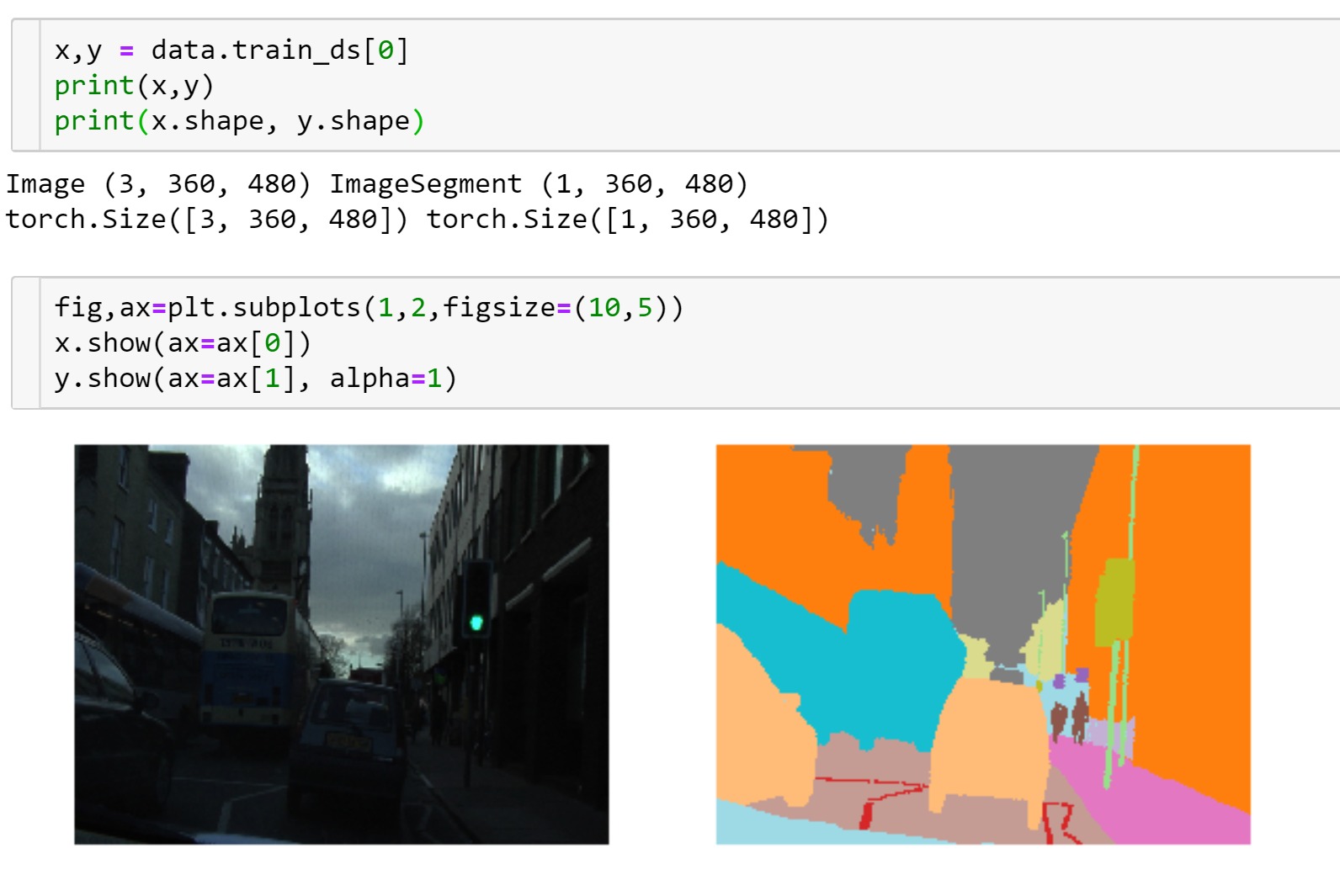
@sgugger, I’m wrong or in the jupyter notebook lesson3-camvid.ipynb, data.show_batch() does not show the real input to our model U-Net (real input = image transformed by tfms)?
(same question about learn.show_results() that does not show what will be predicted by the model (ie, a mask) but an overlay of the input image and its mask prediction)
I run the Multi-label prediction with Planet Amazon dataset example (lesson3-planet.ipynb) on a medical imaging data (MRI) and got (too)good results
To get more confident at the results I try to adjust the tools of the interpolation from a lesson 2 as plotting the confusion matrix and images of the top_losses + prediction / actual / loss / probability
Multi labels is when an object can have several tags, Multi class is classification with multi classes, but the object can only have one label. Isn’t that right?
Hi. Did anyone try the head pose notebook? I tried to run it and found out the training error and validation error would not go down after 5 epochs. They would actually go down at first two or three epochs then shoot up. I also tried different learning rate and unfreeze the model to fine-tune the model and train more epochs but it did not seem to solve the problem. My training error was way higher than the validation error. And those two errors were far higher than the error in the video.
BTW, the note seemed to have several changes comparing to the notebook in the video. There was PointsItemList rather than imagefilelist, and the error function was not changed in the notebook. I am assuming there was api updates so we have a specific class dealing with image to point,