Yikes, we both made a simple mistake here! I just noticed that last night you had suggested:
data_lm = (TextList.from_df(df, cols=[0])
and
data_lm = (TextList.from_df(df, cols=[‘label’])
…but I think you meant to refer to the text field - like cols=[1] or cols=[‘text’]. When I do that it works fine, with 1 or ‘text’! So that is a shorter syntax that works well:
Oh, I did it on purpose, since we had already tried cols='text'. However, the difference here is you are sending a list instead of a string . I run GCP and it rocks but I am running out of credits and will turn back to my home server soon.
Can I have all my images in a single folder. Image names (w/o suffix) & labels (one label per image) in a labels.csv file and build a databunch like this?
I’m also having similar problems when trying to running data.show_batch(). I’m working with a really small image data set (only 12 images), and they’re all different sizes. Not sure if this plays any part into this error.
RuntimeError: Error(s) in loading state_dict for MultiBatchRNNCore:
size mismatch for encoder.weight: copying a param of torch.Size([33080, 400]) from checkpoint, where the shape is torch.Size([33387, 400]) in current model.
size mismatch for encoder_dp.emb.weight: copying a param of torch.Size([33080, 400]) from checkpoint, where the shape is torch.Size([33387, 400]) in current model.
I notice that fine_tuned_enc.pth appears to be unchanged from 2 days ago:
Yikes - yes I’m pretty sure I fixed it but it’s been weeks so I’ll have to go back to that nb and see if I have notes on it. I think it may have been fixed with a newer fastai version but don’t recall - but you should try that!
Yeah, I tried that already. I’ve updated to the latest version. I’m also getting another error saying “AttributeError: ‘float’ object has no attribute ‘replace’”
I just updated the Zeit script to the latest fastai (1.0.40) and it’s working properly. Be sure to pull the last version of the corresponding notebook as it’s using the new fast way to do inference.
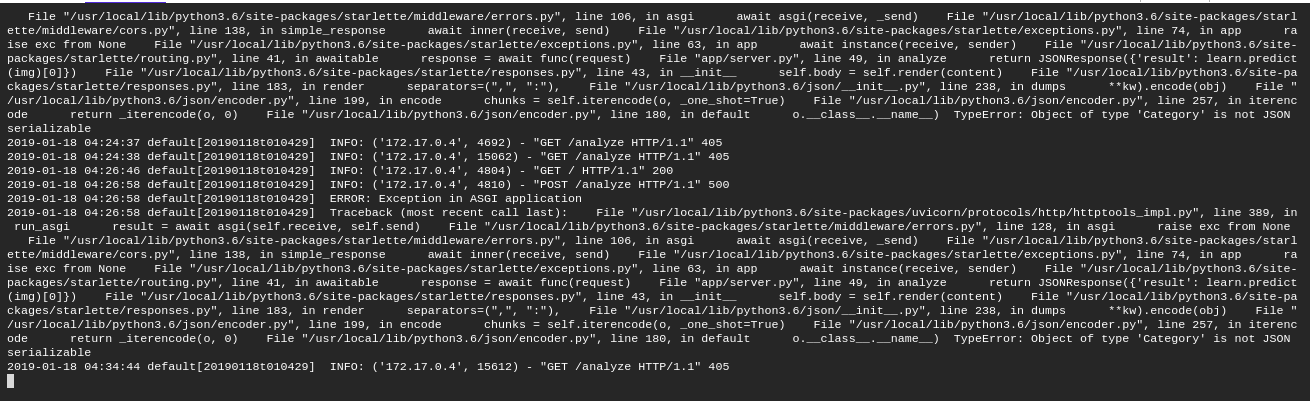
There is some new type of error coming up then @sgugger
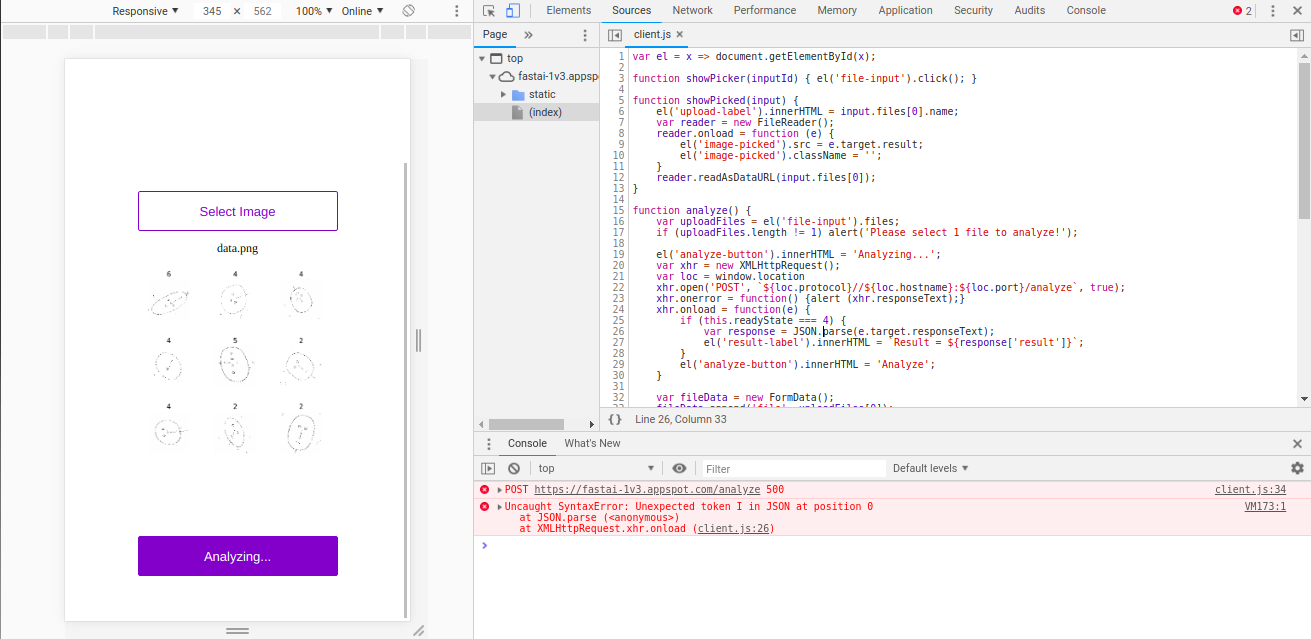
client.js:34 POST https://fastai-1v3.appspot.com/analyze 500
analyze @ client.js:34
onclick @ (index):28
VM173:1 Uncaught SyntaxError: Unexpected token I in JSON at position 0
at JSON.parse ()
at XMLHttpRequest.xhr.onload (client.js:26)
xhr.onload @ client.js:26
load (async)
analyze @ client.js:24
onclick @ (index):28
For an excellent code example for modifying 3 channel input pretrained models into 4 (or even more if you wish) by @wdhorton for the Human Protein Atlas competition here.
 . I run GCP and it rocks
. I run GCP and it rocks  but I am running out of credits and will turn back to my home server soon.
but I am running out of credits and will turn back to my home server soon.