Hey! Can you try df['Unnamed: 0']=df['Unnamed: 0'].astype(int) + 1 on your original table? This basically casts every item in this column to an integer.
2 Likes
Thanks! I don’t think that Unnamed col was a problem - at that point the problem with creating the databunch was fixed; that Unnamed col was just a leftover empty col from when I was manipulating the csv in Excel.
Now I’m working with the df and everything runs OK, but the TextLMDataBunch seems to be reading labels instead of the text :
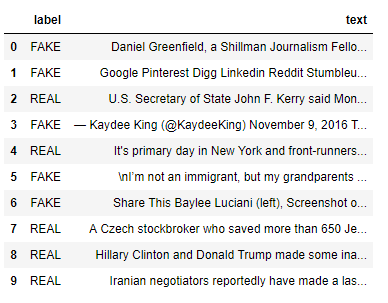
df = pd.read_csv(path/'fake_or_real_news.csv', usecols=["label", "text"])[["label", "text"]]
df.head(10)
data_lm = (TextList.from_df(df, col='text')
.random_split_by_pct(0.2)
.label_for_lm()
.databunch())
data_lm.save('tmp_lm')
data_lm = TextLMDataBunch.load(path, 'tmp_lm')
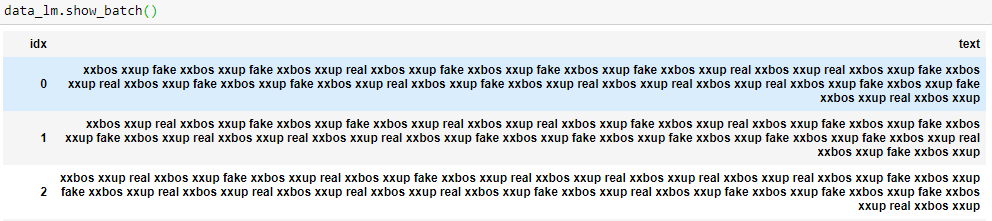
Why would it do that??
Can you try running this instead?
data_lm = (TextList.from_df(df, cols=1)
.random_split_by_pct(0.2)
.label_for_lm()
.databunch())
data_lm.save('tmp_lm')
data_lm = TextLMDataBunch.load(path, 'tmp_lm')Thanks, I tried that (very hopeful!) but got almost the same result - slight differences but same basic pattern:
Hi,
I am trying to create a Image Data Bunch form a CSV file and trying to display sample images, receiving below error, can someone please help.
data = ImageDataBunch.from_csv(path, csv_labels=‘train.csv’,folder=‘train’,tfms=tfms)
data.show_batch(rows=2, figsize=(9,7))
RuntimeError: invalid argument 0: Sizes of tensors must match except in dimension 0. Got 465 and 498 in dimension 2 at /pytorch/aten/src/TH/generic/THTensorMoreMath.cpp:1325
2 Likes
What about:
data_lm = (TextList.from_df(df, cols=‘text’)
.random_split_by_pct(0.2)
.label_for_lm()
.databunch())
data_lm.save(‘tmp_lm’)data_lm = TextLMDataBunch.load(path, ‘tmp_lm’)
I’m having some trouble labeling my images using the data block API. Since it’s a multi-class classification problem where most classes have just one example, I want to duplicate images from the underrepresented classes. I now have a DataFrame with image names and labels, including duplicates. My images are in path/train. Here’s my code:
src = (ImageItemList.from_df(df=train_df, path=path, cols='Name', folder='train')
.split_by_valid_func(lambda o: o in val_n)
.label_from_df(cols='Id'))
However, label_from_df throws the following error:
IndexError: index 0 is out of bounds for axis 0 with size 0
Any thoughts? Here’s the full traceback:

What happens if you run:
data_lm = (TextList.from_df(df, cols=[0,1])
.random_split_by_pct(0.2)
.label_for_lm()
.databunch())
data_lm.save(‘tmp_lm’)data_lm = TextLMDataBunch.load(path, ‘tmp_lm’)
and
data_lm = (TextList.from_df(df, cols=[‘text’,‘label’])
.random_split_by_pct(0.2)
.label_for_lm()
.databunch())
data_lm.save(‘tmp_lm’)data_lm = TextLMDataBunch.load(path, ‘tmp_lm’)
Yes! Both worked. So it looks like, for some reason, I have to specify both cols, maybe because the df has a few more cols I’m not using? Does this make sense? Want to make sure I learn from it! thanks
I don’t really know what’s going on. This might give us more info. Try:
data_lm = (TextList.from_df(df, cols=[0])
.random_split_by_pct(0.2)
.label_for_lm()
.databunch())
data_lm.save(‘tmp_lm’)data_lm = TextLMDataBunch.load(path, ‘tmp_lm’)
and
data_lm = (TextList.from_df(df, cols=[‘label’])
.random_split_by_pct(0.2)
.label_for_lm()
.databunch())
data_lm.save(‘tmp_lm’)data_lm = TextLMDataBunch.load(path, ‘tmp_lm’)
I suspect you have an index column that took up column 0, hence pushing [‘label’] to column 1 and
[‘text’] to column 2
Maybe try removing the index?
OK, I’ll try that later. Meanwhile, I tried to move to a faster GPU (I was on a P5000), but Gradient is screwing up (again!) so I couldn’t get a faster one (couldn’t get any gpu’s at first) and then could only get a slower one (GPU+). So now I’m running on that - and
cols=['text','label']
doesn’t work anymore!
cols=[0,1]
does work so I’m running with that right now.
So now I wonder if these problems are due to some problems in the Gradient stack/infrastructure? Seems very weird that code would work with one GPU and not another.
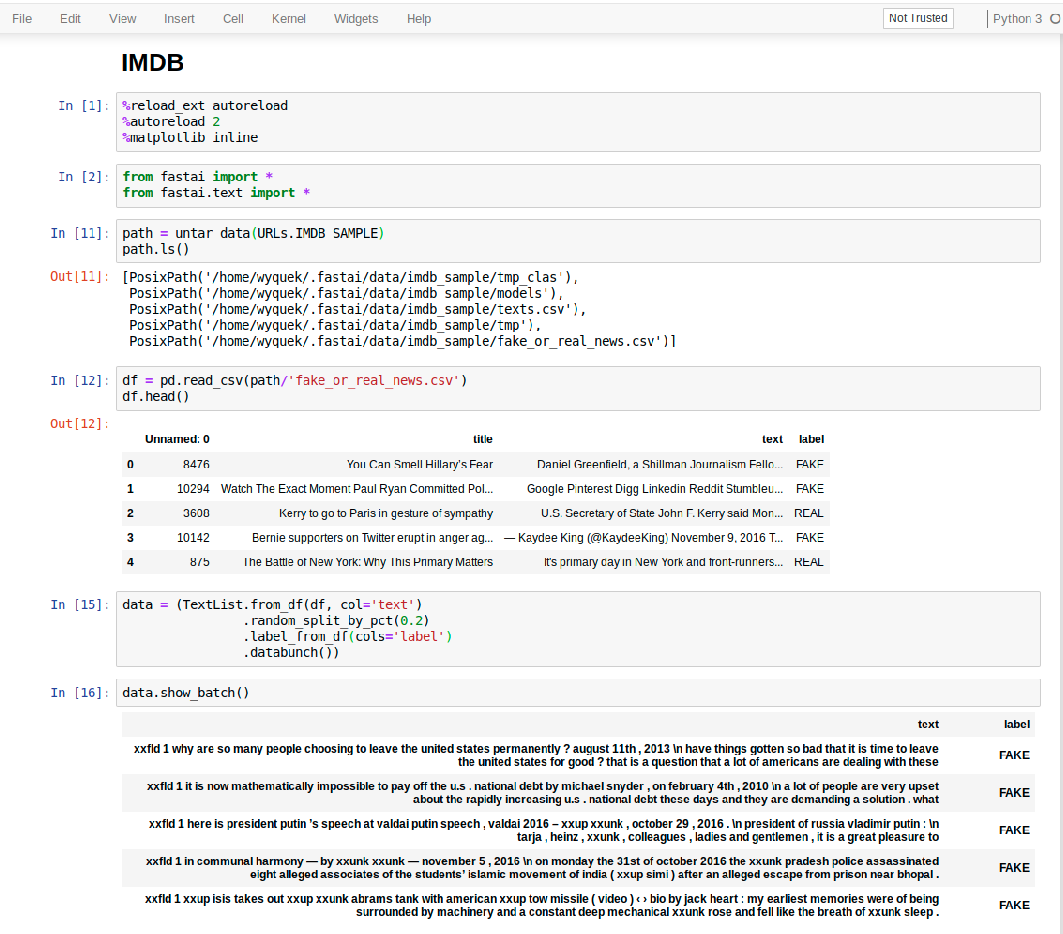
Thanks, there is an index col in the csv, but since I’m creating the df like this:
df = pd.read_csv(path/'fake_or_real_news.csv', usecols=["label", "text"])[["label", "text"]]
I don’t think the df can even see the index col. Also, I’m addressing the df cols explicitly by col name like this:
data_lm = (TextList.from_df(df, cols=[‘text’,‘label’])
so col order shouldn’t be a problem.
Not sure if this is helpful, but I clobbered your codes together and ran them, the show_batch() seems to be working fine
How can we build a TextDataBunch to Classify more than one labels in one context i.e Tags?
That’s interesting, because I get the original error I had (TypeError: must be str, not int) if I do exactly the same thing:
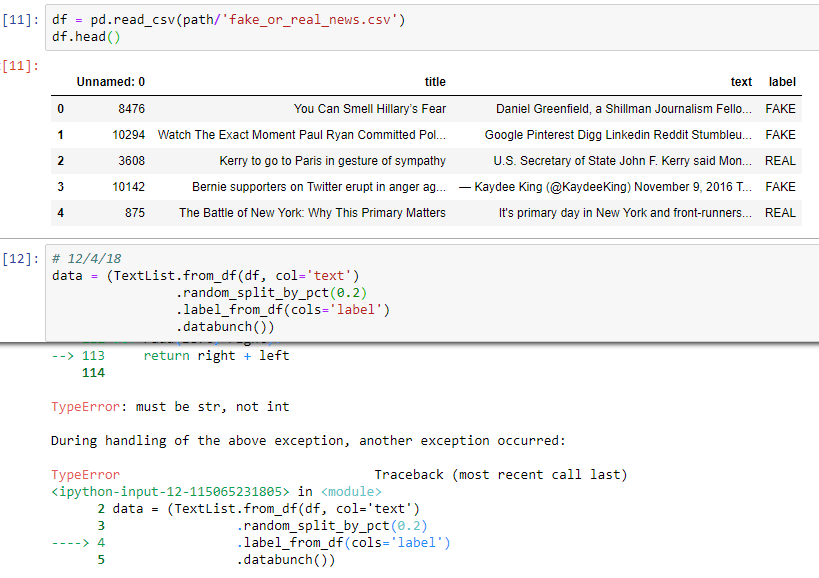
Which may be a result of the platform and/or versions. Which platform are you running on? I’m on Gradient and got weird behavior yesterday when I switched servers.
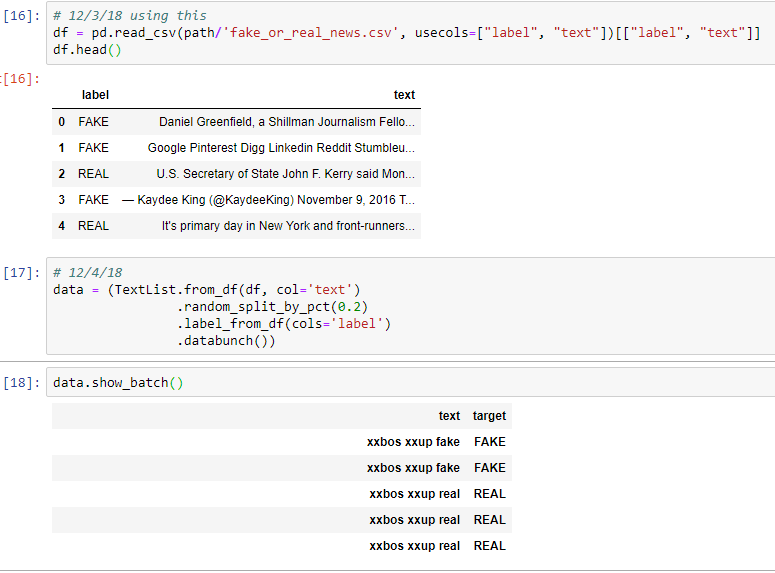
Also, if I specify the cols, I get around the TypeError, but then the text isn’t read correctly:
i’m not on cloud. i’ve got a humble little desktop with a 1070 gpu on ubuntu
Both of those result in the same scrambled text:
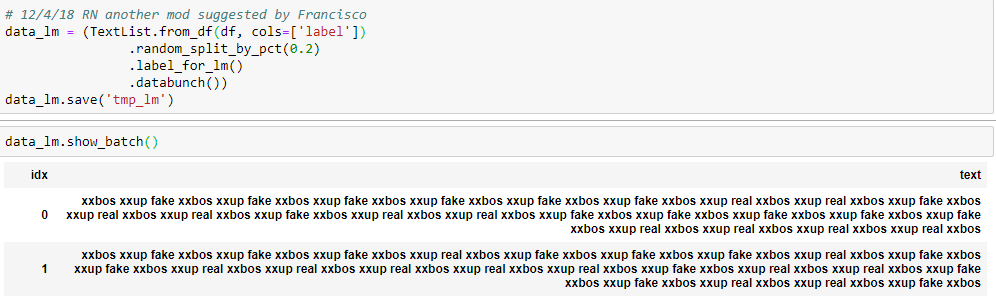
If I go back to
data_lm = (TextList.from_df(df, cols=['text','label'])
.random_split_by_pct(0.2)
.label_for_lm()
.databunch())
or
data_lm = (TextList.from_df(df, cols=[0,1])
it works properly again.
I’m running on a Gradient P6000 today, so it does appear that part of this problem is the platform! Last night on the GPU+
cols=['text','label']
didn’t work. Also see what wyquek and I compared above:
…so again it appears that the platform (meaning Gradient) is at least part of the problem.
I don’t really know why the problem arises. TextList calls .from_df from the parent class ItemList which in turn calls .iloc with the column numbers. I don’t know where it is failing.