nevermind. it seems to work now. thank you all the same!
While running this code chunk:
data = (src.transform(tfms, size=256)
.databunch().normalize(imagenet_stats))
learn.data = data
data.train_ds[0][0].shape
learn.freeze()
learn.lr_find()
learn.recorder.plot()
This is where we resize the images to 256 to improve the f-score - but I’m running into CUDA Out of memory issues, despite restarting the kernel. I am also just loading the saved weights from the previous run, and thus not re-running any model. I’m using GCP Compute instance for training my models. Does anyone have a workaround for this?
1 Like
Try to reduce the batch size inside of the databunch method. That worked for me (e.g. bs=32)
I must be doing something wrong - even after decreasing the batch-size to 4, I’m still getting the out of memory error. There must be something that I’m missing.
Edit: My bad - I was adding that parameter to .transform() instead of .databunch(). It’s working now. Thanks, @jm0077
1 Like
Trying to conduct some experiments using unet from fastai library but couldnt get it work with some high resolution images…using batch size=1 as each image resolution is 8k*5k.
For some reason, batch size =1 isnt working for any dataset even for camvid.
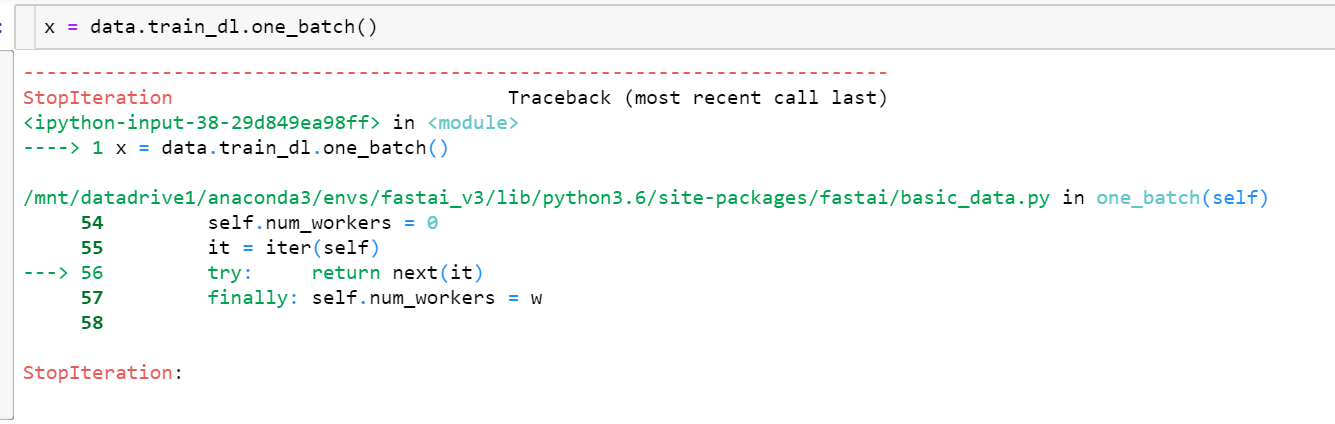
Error when trying to access one batch of data
Error with lr_find

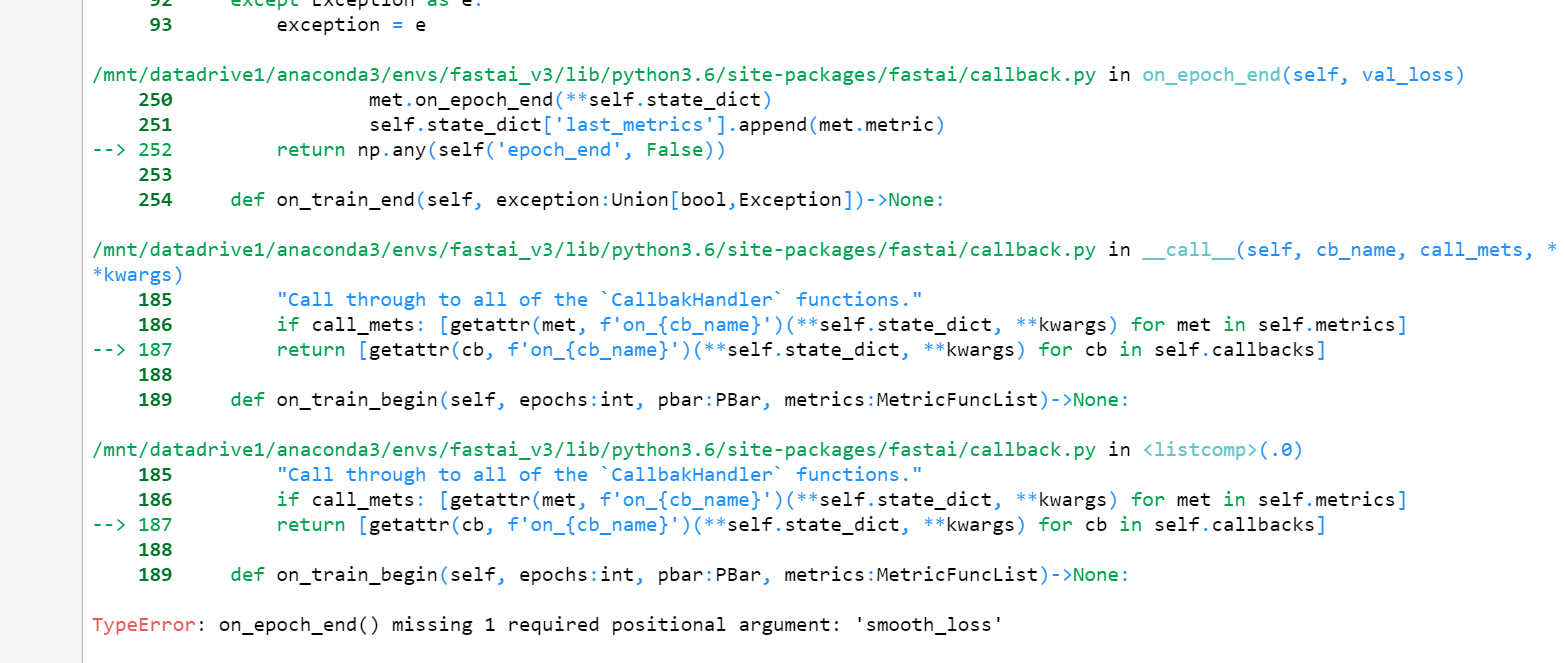
Error with fit_once_cycle
I am building language model for hindi but not able to load data . Every time kernel restarts. I have 32 gb ram and my data is of 10gb.
getting problem here:
data_lm = (TextFileList.from_folder(path)
#grab all the text files in path
.label_const(0)
#label them all wiht 0s (the targets aren't positive vs negative review here)
.split_by_folder(valid='test')
#split by folder between train and validation set
.datasets()
#use `TextDataset`, the flag `is_fnames=True` indicates to read the content of the files passed
.tokenize()
#tokenize with defaults from fastai
.numericalize()
#numericalize with defaults from fastai
.databunch(TextLMDataBunch))
#use a TextLMDataBunch
---------------------------------------------------------------------------
MemoryError Traceback (most recent call last)
<ipython-input-6-be9b2c40e9af> in <module>
3 .label_const(0)
4 #label them all wiht 0s (the targets aren't positive vs negative review here)
----> 5 .split_by_folder(valid='test')
6 #split by folder between train and validation set
7 .datasets()
~/anaconda2/envs/hindinlu/lib/python3.6/site-packages/fastai/data_block.py in datasets(self, dataset_cls, **kwargs)
232 "Create datasets from the underlying data using `dataset_cls` and passing along the `kwargs`."
233 if dataset_cls is None: dataset_cls = self.dataset_cls()
--> 234 train = dataset_cls(*self.train.items.T, **kwargs)
235 dss = [train]
236 dss += [train.new(*o.items.T, **kwargs) for o in self.lists[1:]]
~/anaconda2/envs/hindinlu/lib/python3.6/site-packages/fastai/text/data.py in __init__(self, fns, labels, classes, mark_fields, encode_classes)
199 for f in fns:
200 with open(f,'r') as f: texts.append(''.join(f.readlines()))
--> 201 super().__init__(texts, labels, classes, mark_fields, encode_classes)
202
203 class LanguageModelLoader():
~/anaconda2/envs/hindinlu/lib/python3.6/site-packages/fastai/text/data.py in __init__(self, texts, labels, classes, mark_fields, encode_classes)
129 def __init__(self, texts:Collection[str], labels:Collection[Any]=None, classes:Collection[Any]=None,
130 mark_fields:bool=True, encode_classes:bool=True):
--> 131 texts = _join_texts(np.array(texts), mark_fields)
132 super().__init__(texts, labels, classes, encode_classes)
133
MemoryError:
I have divided my text file into small subsets but still same problem. I have monitored memory usage of my system also and its getting upto 95% then gets crash.
How you people load huge data?
@sgugger @radek
how to set the batchsize while using DataBlock API?
I am trrying to use it in .databunch(bs =32) but
still the data batch is 64(it might be default, I guess) and throwing mre memory error
data = (ImageItemList.from_csv(planet, 'labels.csv', folder='train', suffix='.jpg')
#Where to find the data? -> in planet 'train' folder
.random_split_by_pct()
#How to split in train/valid? -> randomly with the default 20% in valid
.label_from_df(sep=' ')
#How to label? -> use the csv file
.transform(planet_tfms, size=128)
#Data augmentation? -> use tfms with a size of 128
.databunch())AFAIK bs should go in databunch. Have you tried removing the empty space? I mean use .databunch(bs=32) instead of .databunch(bs =32). I’m not sure what’s the impact of that.
whitespace in python function argument lists (and the language in general) does not matter. well, apart from the indent in loops/ if clauses etc. of course
1 Like
Is there a y_range argument or anything similar for the text_classifier_learner to limit the output of a regression?
1 Like
Is there anyway i can track errors from validation set and further finetune my model? Otherwise can i split my training data into training,test and validation set. Then do the model testing with this new set of test data created from training data and collect all the mis-classification ones and run the model only through the wrong ones?
I guess this is what was also discussed during lesson-3.
Thanks
Amit
I am also not sure what action we should take from the output of following top x mis-classifications one?
interp = ClassificationInterpretation.from_learner(cn_152)
interp.plot_top_losses(20, figsize=(12,10))?
Can someone tell me what’s wrong with this? I get
TypeError: must be str, not int
from
.label_from_df(cols='label')
I get the same error if I use (cols=3), which works in the IMDB nb.
data = (TextList.from_csv(path, 'fake_or_real_news.csv', col='text')
.random_split_by_pct(0.2)
.label_from_df(cols='label')
.databunch())
TypeError Traceback (most recent call last)
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in na_op(x, y)
1011 try:
-> 1012 result = expressions.evaluate(op, str_rep, x, y, **eval_kwargs)
1013 except TypeError:
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/computation/expressions.py in evaluate(op, op_str, a, b, use_numexpr, **eval_kwargs)
204 if use_numexpr:
--> 205 return _evaluate(op, op_str, a, b, **eval_kwargs)
206 return _evaluate_standard(op, op_str, a, b)
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/computation/expressions.py in _evaluate_numexpr(op, op_str, a, b, truediv, reversed, **eval_kwargs)
119 if result is None:
--> 120 result = _evaluate_standard(op, op_str, a, b)
121
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/computation/expressions.py in _evaluate_standard(op, op_str, a, b, **eval_kwargs)
64 with np.errstate(all='ignore'):
---> 65 return op(a, b)
66
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in radd(left, right)
112 def radd(left, right):
--> 113 return right + left
114
TypeError: must be str, not int
During handling of the above exception, another exception occurred:
TypeError Traceback (most recent call last)
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in safe_na_op(lvalues, rvalues)
1032 with np.errstate(all='ignore'):
-> 1033 return na_op(lvalues, rvalues)
1034 except Exception:
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in na_op(x, y)
1022 mask = notna(x)
-> 1023 result[mask] = op(x[mask], y)
1024
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in radd(left, right)
112 def radd(left, right):
--> 113 return right + left
114
TypeError: must be str, not int
During handling of the above exception, another exception occurred:
TypeError Traceback (most recent call last)
<ipython-input-62-09c1b499b3ab> in <module>
1 data = (TextList.from_csv(path, 'fake_or_real_news.csv', col='text')
2 .random_split_by_pct(0.2)
----> 3 .label_from_df(cols='label')
4 .databunch())
/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/data_block.py in _inner(*args, **kwargs)
316 self.valid = fv(*args, **kwargs)
317 self.__class__ = LabelLists
--> 318 self.process()
319 return self
320 return _inner
/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/data_block.py in process(self)
360 def process(self):
361 xp,yp = self.get_processors()
--> 362 for i,ds in enumerate(self.lists): ds.process(xp, yp, filter_missing_y=i==0)
363 return self
364
/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/data_block.py in process(self, xp, yp, filter_missing_y)
428 filt = array([o is None for o in self.y])
429 if filt.sum()>0: self.x,self.y = self.x[~filt],self.y[~filt]
--> 430 self.x.process(xp)
431 return self
432
/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/data_block.py in process(self, processor)
58 if processor is not None: self.processor = processor
59 self.processor = listify(self.processor)
---> 60 for p in self.processor: p.process(self)
61 return self
62
/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/text/data.py in process(self, ds)
275 def process_one(self, item): return self.tokenizer._process_all_1([item])[0]
276 def process(self, ds):
--> 277 ds.items = _join_texts(ds.items, self.mark_fields)
278 tokens = []
279 for i in progress_bar(range(0,len(ds),self.chunksize), leave=False):
/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/text/data.py in _join_texts(texts, mark_fields)
334 if is1d(texts): texts = texts[:,None]
335 df = pd.DataFrame({i:texts[:,i] for i in range(texts.shape[1])})
--> 336 text_col = f'{BOS} {FLD} {1} ' + df[0] if mark_fields else f'{BOS} ' + df[0]
337 for i in range(1,len(df.columns)):
338 text_col += (f' {FLD} {i+1} ' if mark_fields else ' ') + df[i]
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in wrapper(left, right)
1067 rvalues = rvalues.values
1068
-> 1069 result = safe_na_op(lvalues, rvalues)
1070 return construct_result(left, result,
1071 index=left.index, name=res_name, dtype=None)
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in safe_na_op(lvalues, rvalues)
1035 if is_object_dtype(lvalues):
1036 return libalgos.arrmap_object(lvalues,
-> 1037 lambda x: op(x, rvalues))
1038 raise
1039
pandas/_libs/algos_common_helper.pxi in pandas._libs.algos.arrmap_object()
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in <lambda>(x)
1035 if is_object_dtype(lvalues):
1036 return libalgos.arrmap_object(lvalues,
-> 1037 lambda x: op(x, rvalues))
1038 raise
1039
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in radd(left, right)
111
112 def radd(left, right):
--> 113 return right + left
114
115
TypeError: must be str, not intDoes your csv file have a first row that labels the columns as ‘text’ and ‘label’ ? Check once.
I am guessing because if result is None:
1 Like
Yes, first row has those labels.
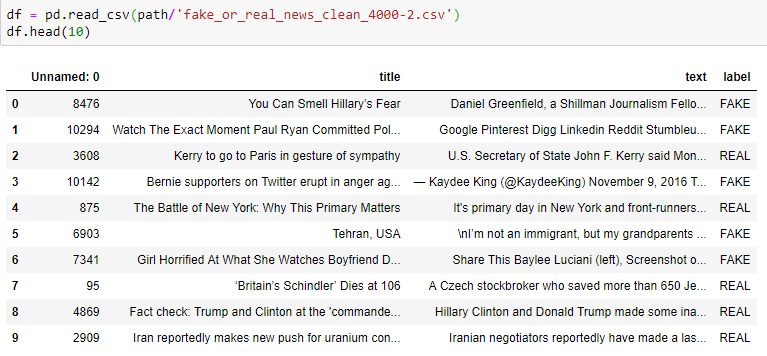
My data looks like this:
I don’t see why that would be a problem but am not sure.
I thought this could be a data problem of some sort since the exact same syntax works fine on the IMDB data, so I cleaned up a subset of the data (it looked like the csv file had some problems) but still get similar errors.
With the cleaned-up data, I get the same error (TypeError: must be str, not int) but now apparently from the next line (.label_from_df):
data = (TextList.from_csv(path, 'fake_or_real_news_clean_4000-2.csv', col='text')
.random_split_by_pct(0.2)
.label_from_df(cols=3)
.databunch())
TypeError Traceback (most recent call last)
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in na_op(x, y)
1011 try:
-> 1012 result = expressions.evaluate(op, str_rep, x, y, **eval_kwargs)
1013 except TypeError:
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/computation/expressions.py in evaluate(op, op_str, a, b, use_numexpr, **eval_kwargs)
204 if use_numexpr:
--> 205 return _evaluate(op, op_str, a, b, **eval_kwargs)
206 return _evaluate_standard(op, op_str, a, b)
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/computation/expressions.py in _evaluate_numexpr(op, op_str, a, b, truediv, reversed, **eval_kwargs)
119 if result is None:
--> 120 result = _evaluate_standard(op, op_str, a, b)
121
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/computation/expressions.py in _evaluate_standard(op, op_str, a, b, **eval_kwargs)
64 with np.errstate(all='ignore'):
---> 65 return op(a, b)
66
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in radd(left, right)
112 def radd(left, right):
--> 113 return right + left
114
TypeError: must be str, not int
During handling of the above exception, another exception occurred:
TypeError Traceback (most recent call last)
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in safe_na_op(lvalues, rvalues)
1032 with np.errstate(all='ignore'):
-> 1033 return na_op(lvalues, rvalues)
1034 except Exception:
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in na_op(x, y)
1022 mask = notna(x)
-> 1023 result[mask] = op(x[mask], y)
1024
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in radd(left, right)
112 def radd(left, right):
--> 113 return right + left
114
TypeError: must be str, not int
During handling of the above exception, another exception occurred:
TypeError Traceback (most recent call last)
<ipython-input-36-5c6735438b12> in <module>
1 data = (TextList.from_csv(path, 'fake_or_real_news_clean_4000-2.csv', col='text')
2 .random_split_by_pct(0.2)
----> 3 .label_from_df(cols=3)
4 .databunch())
/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/data_block.py in _inner(*args, **kwargs)
316 self.valid = fv(*args, **kwargs)
317 self.__class__ = LabelLists
--> 318 self.process()
319 return self
320 return _inner
/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/data_block.py in process(self)
360 def process(self):
361 xp,yp = self.get_processors()
--> 362 for i,ds in enumerate(self.lists): ds.process(xp, yp, filter_missing_y=i==0)
363 return self
364
/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/data_block.py in process(self, xp, yp, filter_missing_y)
428 filt = array([o is None for o in self.y])
429 if filt.sum()>0: self.x,self.y = self.x[~filt],self.y[~filt]
--> 430 self.x.process(xp)
431 return self
432
/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/data_block.py in process(self, processor)
58 if processor is not None: self.processor = processor
59 self.processor = listify(self.processor)
---> 60 for p in self.processor: p.process(self)
61 return self
62
/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/text/data.py in process(self, ds)
275 def process_one(self, item): return self.tokenizer._process_all_1([item])[0]
276 def process(self, ds):
--> 277 ds.items = _join_texts(ds.items, self.mark_fields)
278 tokens = []
279 for i in progress_bar(range(0,len(ds),self.chunksize), leave=False):
/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/text/data.py in _join_texts(texts, mark_fields)
334 if is1d(texts): texts = texts[:,None]
335 df = pd.DataFrame({i:texts[:,i] for i in range(texts.shape[1])})
--> 336 text_col = f'{BOS} {FLD} {1} ' + df[0] if mark_fields else f'{BOS} ' + df[0]
337 for i in range(1,len(df.columns)):
338 text_col += (f' {FLD} {i+1} ' if mark_fields else ' ') + df[i]
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in wrapper(left, right)
1067 rvalues = rvalues.values
1068
-> 1069 result = safe_na_op(lvalues, rvalues)
1070 return construct_result(left, result,
1071 index=left.index, name=res_name, dtype=None)
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in safe_na_op(lvalues, rvalues)
1035 if is_object_dtype(lvalues):
1036 return libalgos.arrmap_object(lvalues,
-> 1037 lambda x: op(x, rvalues))
1038 raise
1039
pandas/_libs/algos_common_helper.pxi in pandas._libs.algos.arrmap_object()
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in <lambda>(x)
1035 if is_object_dtype(lvalues):
1036 return libalgos.arrmap_object(lvalues,
-> 1037 lambda x: op(x, rvalues))
1038 raise
1039
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in radd(left, right)
111
112 def radd(left, right):
--> 113 return right + left
114
115
TypeError: must be str, not intAlso if I try .label_for_lm with the cleaned-up data:
data_lm = (TextList.from_csv(path, 'fake_or_real_news_clean_4000-2.csv', col='text')
.random_split_by_pct(0.2)
#We randomly split and keep 10% for validation
.label_for_lm()
#We want to do a language model so we label accordingly
.databunch())
data_lm.save('tmp_lm')
Then I once again get the error at the previous line (.random_split_by_pct):
During handling of the above exception, another exception occurred:
<ipython-input-34-6e7bbfaafc36> in <module>
1 data_lm = (TextList.from_csv(path, 'fake_or_real_news_clean_4000-2.csv', col='text')
----> 2 .random_split_by_pct(0.2)
3 #We randomly split and keep 10% for validation
4 .label_for_lm()
5 #We want to do a language model so we label accordinglyI don’t really know how to read the exception traceback, so I don’t understand what’s going on.
@lesscomfortable - Any chance you could take a look at this? Am I missing something obvious?
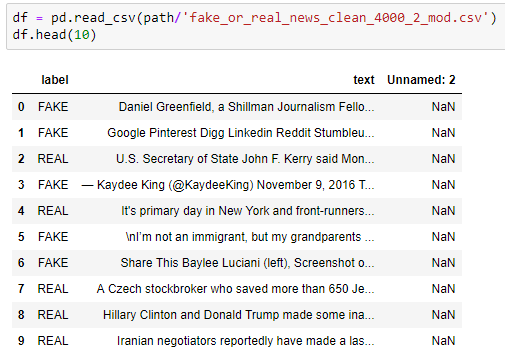
Now I got this to work by changing the cleaned-up data file - removing 2 columns and moving the label col to pos 0:
but I have no idea why that fixed the problem! Help! 