I keep getting the error ImageFileList not defined. Even though I have imported the vision module using from fastai.vision import *.
I am trying to run the camvid notebook
I keep getting the error ImageFileList not defined. Even though I have imported the vision module using from fastai.vision import *.
I am trying to run the camvid notebook
Which version are you running? I think you need at least 1.0.21.
How do I update it? I am running the notebook on AWS
you are right. my version is fastai==1.0.15. How do I update it?
I am no running on AWS, but according to this post conda update -c fastai fastai should work.
I did conda update --all and hoped it would work. Apologize for such a newb question.
This is true but the difference is small; would not be enough to explain significant differences between validation and training losses, specially if you do several epochs.
Btw, on the camvid notebook, most of the time I get good results matching those from the class, but every now and then, I get into a weird accuracy zone that looks like this:
Simply rerunning the cells gets back into the proper 80-90% accuracy zone from the first pass, but occasionally will once again lead to these low accuracies…anyone have a similar experience, and if so, any explanation? Does the learning rate somehow nondeterministically enter a strange zone on the loss function map that it can’t get out of?
Im facing the same issue but all the time. I couldn’t get good accuracies anytime at all!!
@apalepu23 which platform r u using to run?
ahh good to know I’m not alone! I’m using the standard fastai-suggested GCP setup. Hope that helps
Thanks, that fixed the same problem, on Gradient. Although now I have a new one!
TypeError: ufunc ‘add’ did not contain a loop with signature matching types dtype(’<U32’) dtype(’<U32’) dtype(’<U32’)
https://forums.fast.ai/t/general-course-chat/24987/225?u=raghavab1992.
Let me know if reboot fixes the issue for u as well
Lauren - I was doing the sam e thing and hit the same roadblock! I solved it by changing the data object. try this
data = (ImageFileList.from_folder(path, extensions='.jpg')
.random_split_by_pct()
.label_from_df(labels, label_cls=FloatList)
)
I added in the label_cls=FloatList which tells fastai that it is a floats dataset and not a Classification one. Hope this helps!
Hello, I was running the NB for regression problem (head-pose) without any change made from my side and I got the following error when the data object is created:
data = (ImageItemList.from_folder(path)
.split_by_valid_func(lambda o: o.parent.name=='13')
.label_from_func(get_ctr, label_cls=PointsItemList)
.transform(get_transforms(), tfm_y=True, size=(120,160))
.databunch().normalize(imagenet_stats)
)
ValueError: only one element tensors can be converted to Python scalars
Someone knows what should I update? btw my fastai version is ‘1.0.27’
Facing the same issue
Can someone help out
It used to work fine until I pulled and conda installed the new updates (fastai version 1.0.27)
Working on Google Cloud if its any help
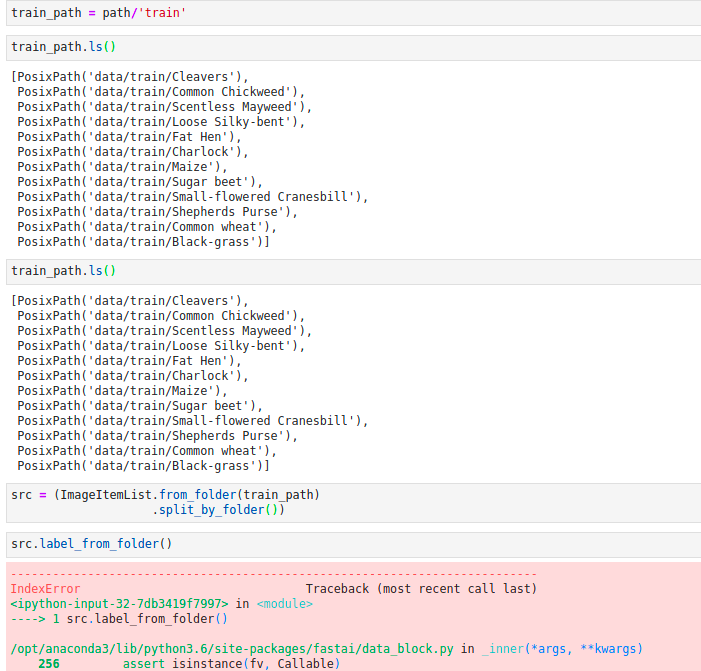
when i call src.label_from_folder() it gives me an IndexError: index 0 is out of bounds for axis 0 with size 0.
hey, Sam, could you elaborate a bit more on how to solve this?
thank you!
hi Karan,
I hope your issue has been resolved. I have an issue above this issue you have in the data_lm part.  Could you share your nb how you get pass this? I think it has to do with my untar_url on IMDB. i have the following 3 files instead of what Jeremy has in his output. So i dont have a train or test folder for running “data_lm = (TextList.from_folder…”
Could you share your nb how you get pass this? I think it has to do with my untar_url on IMDB. i have the following 3 files instead of what Jeremy has in his output. So i dont have a train or test folder for running “data_lm = (TextList.from_folder…”
Thank you so much!
[PosixPath(’/home/nbuser/courses/fast-ai/course-v3/nbs/data/imdb/classes.txt’),
PosixPath(’/home/nbuser/courses/fast-ai/course-v3/nbs/data/imdb/train.csv’),
PosixPath(’/home/nbuser/courses/fast-ai/course-v3/nbs/data/imdb/test.csv’)]
data_lm = (TextList.from_folder(path)
#Inputs: all the text files in path
.filter_by_folder(include=[‘train’, ‘test’])
#We may have other temp folders that contain text files so we only keep what’s in train and test
.random_split_by_pct(0.1)
#We randomly split and keep 10% (10,000 reviews) for validation
.label_for_lm()
#We want to do a language model so we label accordingly
.databunch(bs=bs))
data_lm.save(‘tmp_lm’)
@angelinayy, It was not for you and me to solve. The URL for IMDB used to point to a tgz file which contained only 3 txet files. The current URL (https://s3.amazonaws.com/fast-ai-nlp/imdb.tgz) has the right tgz file. If you click on the URL link and open the tgz file you will find that it contains directories like train, test etc.
So the issue is resolved now.
thanks!