def accuracy(input, target):
#The input.argmax(dim=1) selects the winner class pr pixel, thereby reducing
#the input shape from (bs, classes, width, height) => (bs, width, height)
#We, therefore, have to reshape the target tensor from (bs, 1, width, height) to (bs, width, height)
sz = target.size()
target = target.reshape( (sz[0],sz[2],sz[3]) )
return (input.argmax(dim=1).flatten()==target.flatten()).float().mean()
I replaced the squeeze by reshape because it turns out that sueeze does not work if the last batch only contains one tensor, In that cases it squees out 2 dimension and not 1 ie (1,1,width,height) becomes width,height .
Getting errors while loading imdb data
While creating data_clas for imdb classifier getting this error:
data_clas = (TextFileList.from_folder(path)
#grap all the text files in path
.label_from_folder(classes=['neg','pos'])
#label them all with their folder, only keep 'neg' and 'pos'
.split_by_folder(valid='test')
#split by folder between train and validation set
.datasets()
#use `TextDataset`, the flag `is_fnames=True` indicates to read the content of the files passed
.tokenize()
#tokenize with defaults from fastai
.numericalize(vocab = data_lm.vocab)
#numericalize with the same vocabulary as our pretrained model
.databunch(TextClasDataBunch, bs=50))
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-90-5e9fe410bc17> in <module>
4 .label_from_folder(classes=['neg','pos'])
5 #label them all with their folder, only keep 'neg' and 'pos'
----> 6 .split_by_folder(valid='test')
7 #split by folder between train and validation set
8 .datasets()
~/anaconda2/envs/hindinlu/lib/python3.6/site-packages/fastai/data_block.py in datasets(self, dataset_cls, **kwargs)
231 def datasets(self, dataset_cls:type=None, **kwargs)->'SplitDatasets':
232 "Create datasets from the underlying data using `dataset_cls` and passing along the `kwargs`."
--> 233 if dataset_cls is None: dataset_cls = self.dataset_cls()
234 train = dataset_cls(*self.train.items.T, **kwargs)
235 dss = [train]
~/anaconda2/envs/hindinlu/lib/python3.6/site-packages/fastai/text/data.py in dataset_cls(self)
34
35 def dataset_cls(self):
---> 36 return FilesTextDataset if isinstance(self.train.items[0][0],Path) else TextDataset
37
38 def add_test_folder(self, test_folder:str='test', label:Any=None):
IndexError: index 0 is out of bounds for axis 0 with size 0
can any one suggest what file format or folder format should I follow?
I am trying to work on TGS salt classification problem which has 2 classes in its mask. While working on it i have noticed following things which i don’t quite understand:
lr_find(learn) gives me very different vales every time i run it
My validation error is very very high train loss= .28 but validation 4075 or so. What can cause such behavior?
I am using dice as my accuracy metric with 2 classes.
makes sense Kaspar! I guess part of the problem was I was assuming the target should just be a tensor of (width, height), but if you do mask.data.shape you get a tensor(1, width, height), so it makes sense you need to squeeze that down. thanks
This may have been discussed before…so please refresh my memory or set my understanding right.
Is there merit in converting input images to gray-scale before processing further? I thing the transforms could potentially do that but Jeremy may have shared his experience in the past that conversion to gray-scale does not help a lot.
I have trained language model by following the imdb notebook for Hindi text classification and haven’t changed any parameter. Now while loading the encoder for classification getting this error.
learn.load_encoder('fine_tuned_enc1')
learn.freeze()
RuntimeError: Error(s) in loading state_dict for MultiBatchRNNCore:
size mismatch for encoder.weight: copying a param with shape torch.Size([60002, 400]) from checkpoint, the shape in current model is torch.Size([226, 400]).
size mismatch for encoder_dp.emb.weight: copying a param with shape torch.Size([60002, 400]) from checkpoint, the shape in current model is torch.Size([226, 400]).
data = (src.datasets().transform(get_transforms(), size=128).databunch().normalize(imagenet_stats))
Error:
/opt/anaconda3/lib/python3.6/site-packages/fastai/data_block.py in datasets(self, dataset_cls, **kwargs)
232 "Create datasets from the underlying data using `dataset_cls` and passing along the `kwargs`."
233 if dataset_cls is None: dataset_cls = self.dataset_cls()
--> 234 train = dataset_cls(*self.train.items.T, **kwargs)
235 dss = [train]
236 dss += [train.new(*o.items.T, **kwargs) for o in self.lists[1:]]
TypeError: __init__() missing 2 required positional arguments: 'x' and 'y'
I am not smart enough to keep track of the tensors’ dimensions and ranks on the fly . So, when something is not working, I start by checking tensors’ shapes.
In this particular case, it seems that the open_mask function converters the mask in a regular 3-channel image (rank-3 tensor), but since the mask is 1-channel, the batch shape is [bs, 1, h, w]. If you are using the standard fastai pipeline, you don’t have to worry about it, since its loss functions flatten the preds and target tensors. However, when defining customs metrics, a good practice should be checking tensors’ shapes.
Hello,
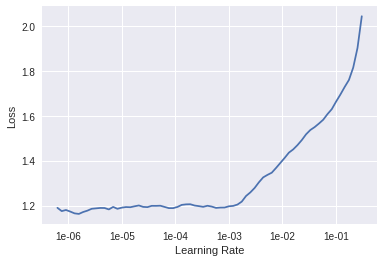
I was wondering what this type of graph means since it seems to have a pretty flat slot in the beginning which seems to be a problem for finding a learning rate accurately. I’m using a dataset comparing images of different types of architecture towers:
According to some of the images there is maybe a classification issue due to the similarity of towers between like an office tower or a residential. Perhaps I have to do better seperation between the images. I was just wondering if there’s a better way to approach this since I’m getting this for training:
Jeremy mentioned this type of graph in the lecture, and you can see an example in the planets notebook. He suggested you find the point where it starts rising and then divide that learning rate by 10, so in your case I’d try 1e-4.
error rate is going down, and val loss is still above train loss, which mean that you are still underfitting. There’s no reason to stop at 4 epochs. You should increase the number of epochs until you find that error rate plateaus or starts to go up, and train loss is lower than val loss.
I may be misunderstanding your question, but only the filenames in the ImageFileList that match an entry in labels.csv will be kept (from the docs: “Note: This method will only keep the filenames that are both present in the csv file and in self.items.”)
@safekidda there is an ML course as well from fastai which covered random forest in detail…was inquiring if there is gonna be a part 2 for ML course covering other ML algos (like we have now for DL) when Jeremy suggested looking into ML course during lesson 3
Ah right, fair enough. I suspect they’ll do the deep learning part 2 (v3) next. So, if they do, I think it’ll be a way off.
As an aside, I think near enough everything is better in deep learning these days. The only example I’ve seen (first hand) where non DL models were better was a tiny, very sparse tabular dataset. Even then it’s a pain compared to deep learning because the data prep is much more onerous and less forgiving. Much easier to just stick all your continuous variables as-is and your categorical variables though embeddings in a DL model.
/usr/local/lib/python3.6/dist-packages/fastai/vision/data.py in __getitem__(self, idx)
237 x,y = self.ds[idx]
238 x = apply_tfms(self.tfms, x, **self.kwargs)
--> 239 if self.tfm_y: y = apply_tfms(self.tfms, y, **self.y_kwargs)
240 return x, y
241
/usr/local/lib/python3.6/dist-packages/fastai/vision/image.py in apply_tfms(tfms, x, do_resolve, xtra, size, mult, resize_method, padding_mode, **kwargs)
578 tfms = sorted(listify(tfms), key=lambda o: o.tfm.order)
579 if do_resolve: _resolve_tfms(tfms)
--> 580 x = x.clone()
581 x.set_sample(padding_mode=padding_mode, **kwargs)
582 if size is not None:
AttributeError: 'int' object has no attribute 'clone'
Did anyone try to predict a single image for segmentation?
where do we get lesson 4 youtube link to the live stream? Cant find it on the forum, I am subscribed to the class for lesson 1,2 received emails from Jeremy. Cannot seem to find an announcement in this forum, can someone point me into the right direction please?