Ok so your underlying question. How to interpret << >>
Not an expert but my assumptions have been
Typically validation loss should be similar to but slightly higher than training loss. As long as validation loss is lower than or even equal to training loss one should keep doing more training.
If training loss is reducing without increase in validation loss then again keep doing more training
If validation loss starts increasing then it is time to stop
If overall accuracy still not acceptable then review mistakes model is making and think of what can one change:
More data? More / different data augmentations? Generative data?
Funnily enough, some over-fitting is nearly always a good thing. All that matters in the end is: is the validation loss as low as you can get it (and/or the val accuracy as high)? This often occurs when the training loss is quite a bit lower.
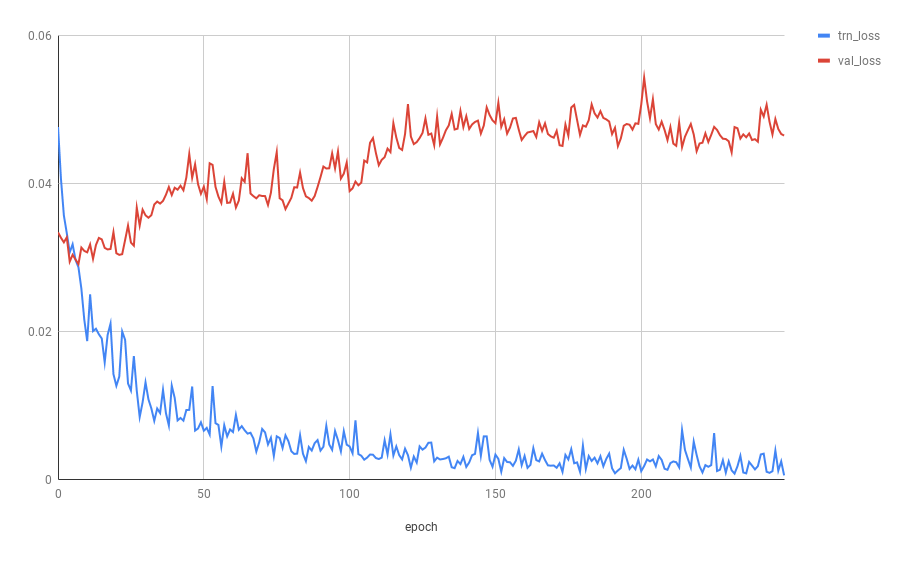
The difference between training and validation loss is the scale of 1/100 (around 0.01 - training 0.03 and validation 0.02). Is this like a metric that we should aim for when training different datasets?
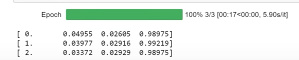
For example when I trained baseball and cricket bats,
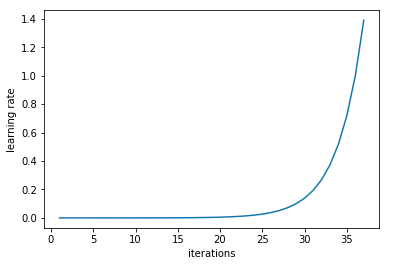
the learning rate graph seems to match
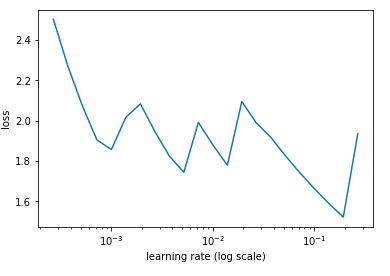
the loss function looks different
Should I try to get a graph similar to the one mentioned in the lecture?
I have a question about the underfitting case where training loss > validation loss. I have seen this happen many times when training models but I don’t understand how this could happen. Why would the model ever perform better on the validation set than on the training set?
@raspstephan are you referring to seeing that while using the fast.ai lib? If I’m remembering right, that funny effect happens because of dropout: the training score is computed with dropout (which knocks out a bunch of the network, thereby weakening it), while the validation score is not (I suppose since it’s supposed to mimic how you’d perform on real test data, where we typically turn off dropout). Jeremy covers this oddity in lecture (assuming I’m not mis-remembering), I’ll try to find a link.
If you try training for more epochs, you’ll notice that we start to overfit, which means that our model is learning to recognize the specific images in the training set, rather than generalizing such that we also get good results on the validation set.
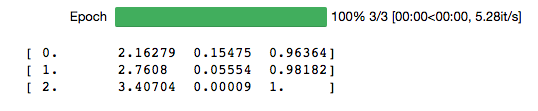
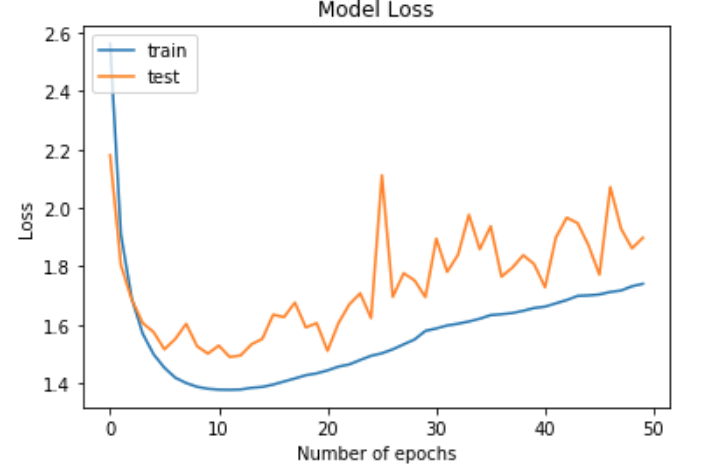
So, I took the 3 lines of code and ran for 50 epochs and got the following:
Is overfitting different than overtraining? With overfitting, the training error keeps going down while the test error goes up. In my situation they both are increasing?!
I came up with a idea for an algorithm that can identify whether a model us overfitting, underfitting or is trained good enough using the loss values without visualizing them. Can someone contribute some interesting losses values they’ve encountered (preferably as a pickle object) with a small description so that I can test it out?