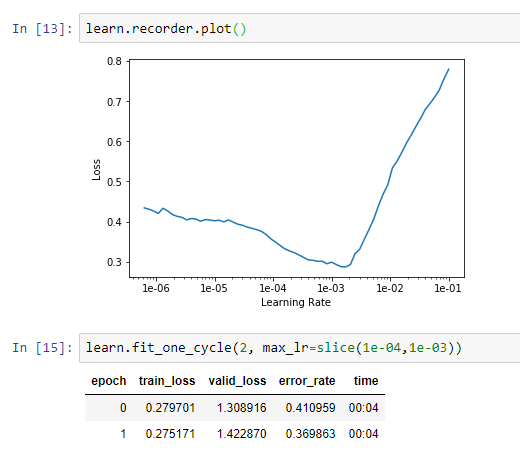
Its really not getting any better. No I tried choosing the best lr I could find and trained it over 4 epochs in total and the training los << validation loss, which according to this thread: Determining when you are overfitting, underfitting, or just right? is very bad!
This is what I am getting: