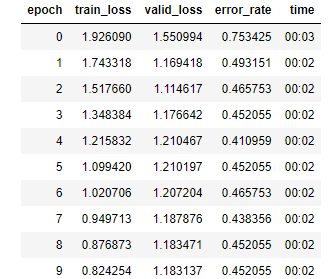
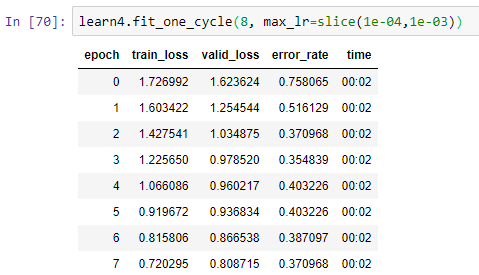
I have about 400(20% was reserved for the validation set) images in total with 4 categories. I have used both resnet 34 and resnet 50 and I keep getting the same results. The only thing that I have done at this point is create the learner, nothing else, I did not unfreeze the other layers yet. I have the data, I took a look at the pictures, and they were all fine, but this keeps happening and I have no idea why:
Then you should unfreeze the model and see what happens. I think talking about over/underfitting without unfreezing is not useful.
Think about it this way: Without unfreezing, you’re stuck with the features that the convolutional part of your network learned to extract from imagenet. A classifier that is stacked on top those featuers can only be so good. The real magic happens when you give your model the chance to adjust the features it detects.
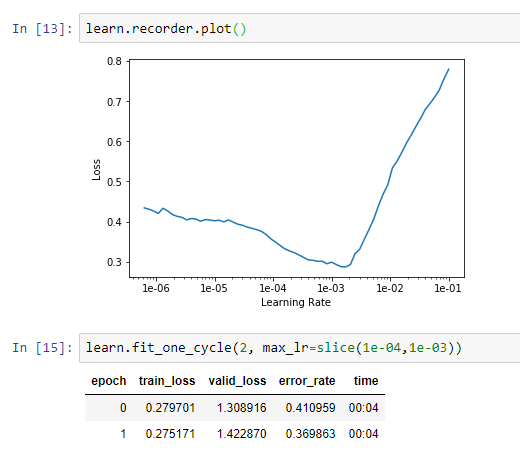
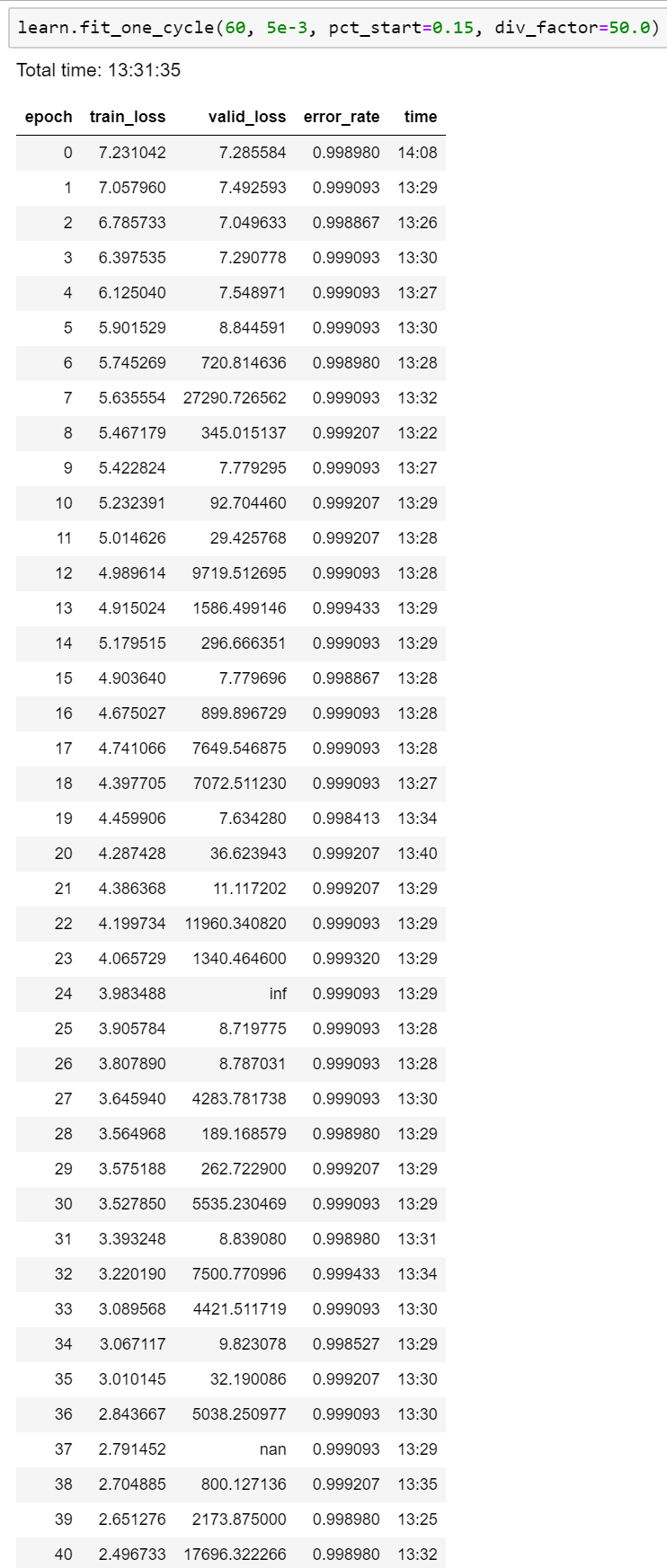
Its really not getting any better. No I tried choosing the best lr I could find and trained it over 4 epochs in total and the training los << validation loss, which according to this thread: Determining when you are overfitting, underfitting, or just right? is very bad!
Without knowing your dataset I can’t really say much. But generally speaking, training for only 2 epochs on the unfrozen model may not be enough. So try increasing the amount of epochs to 15 and see how it reacts.
Can you share your dataset? I might be able to help better if I know what we’re dealing with.
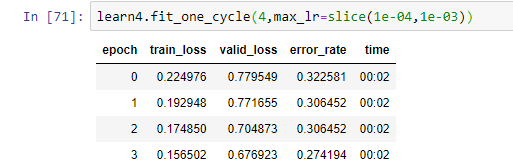
EDIT: I didn’t see it on the first read, but your error rate is decreasing by quite a bit when you trained the unfrozen model. So training for more epochs seems to be the best thing to do
Unfortunately, the error rate is still quite high.
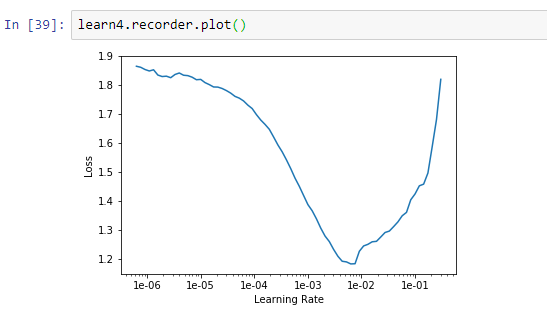
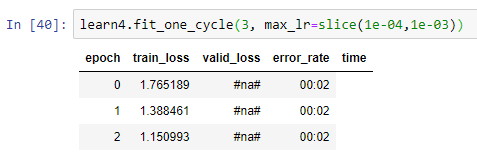
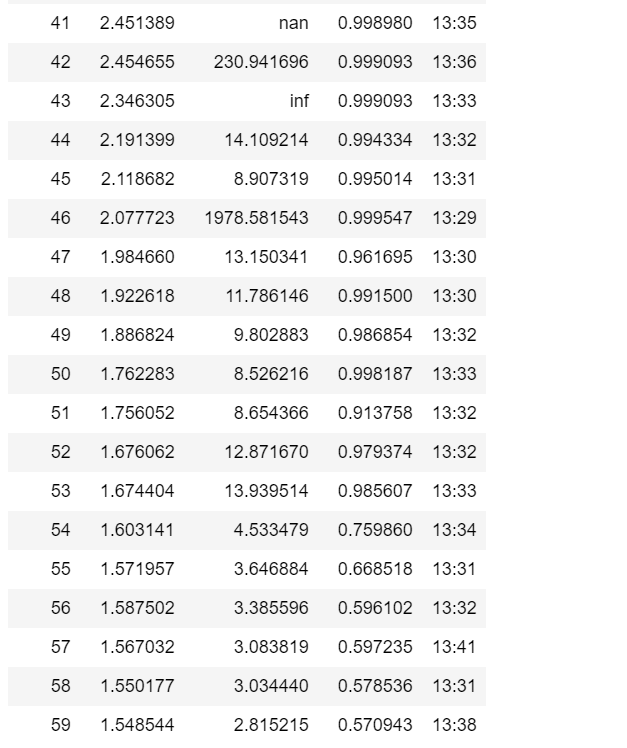
I tried training it a second time and got this:
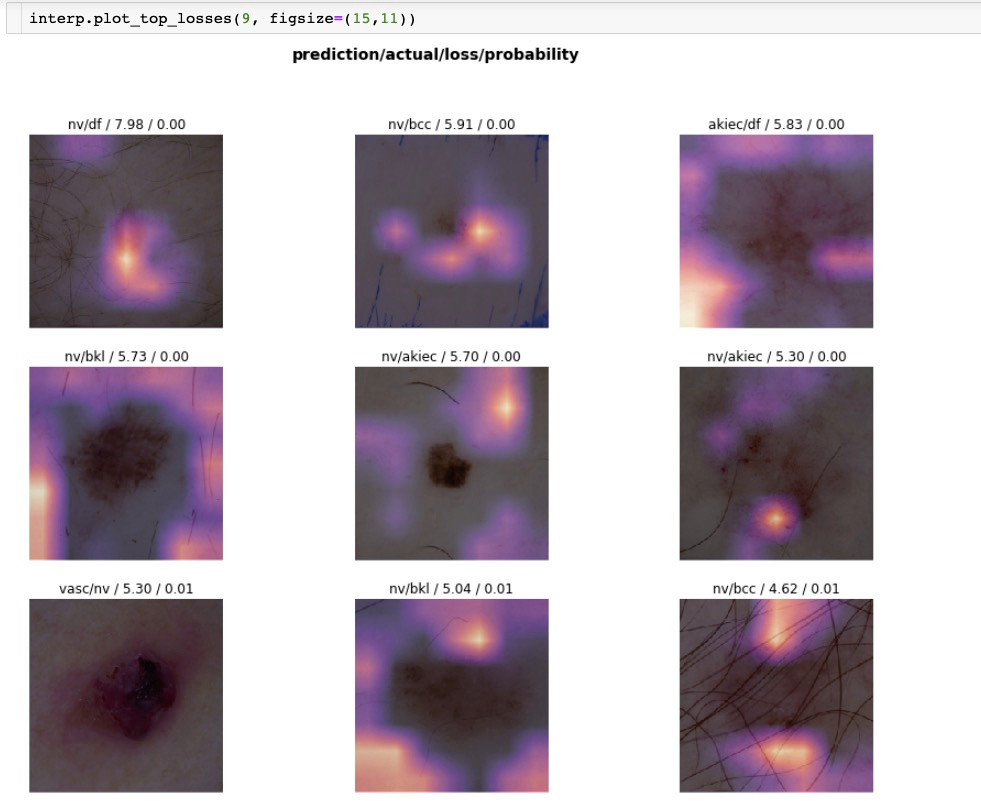
I can’t get it to go below 27%. I guess this is because 3 of the 4 classes share very similar characteristics and the photos don’t really help in bringing out the differences. Unfortunately these were the best photos I could find in google. Im not really sure what else I could do.
Hey @mduboc,
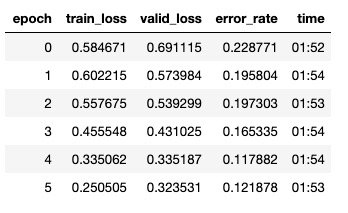
You are not overfitting the data because as you can see the test and the validation error are decreasing overall with your train dataset.
Overfitting is when the error on train dataset decreases while error on CV data and test data increases.
So, there is no overfitting in your data. But your model is finding it difficult to learn features of the data, so in other words Underfitting.
What is the data about?
If there are some really high level features there then the model might be having problem generalizing the features.
Regards,
Jayam
I think you should try to fix this before trying anything “fancy” with your model
Without a good dataset your model have no way to understand the differences between your classes.
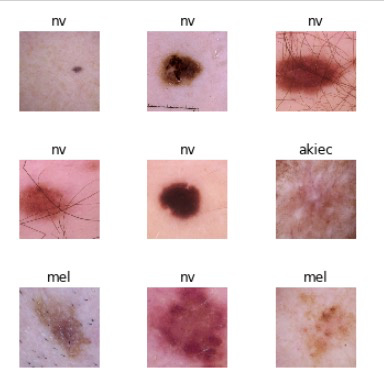
The model is supposed to distnguish between different types of Peruvian ceviches. The problem with this is that most of the time, the ceviches will have mainly white fish because of the fact that fish is a core ingredient and when you “cook” the fish in lime, the acidity makes it turn white, despite what fish it is. This makes the different types of ceviche look the same at first glance. One of the categories involves a ceviche which has squid and octopus, but since fish is still the recurring ingredient,(and because the other ingredients still look white) the model has trouble differentiating it from from the other types(minus one).
The model is supposed to distnguish between different types of Peruvian ceviches. The problem with this is that most of the time, the ceviches will have mainly white fish because of the fact that fish is a core ingredient and when you “cook” the fish in lime, the acidity makes it turn white, despite what fish it is. This makes the different types of ceviche look the same at first glance. One of the categories involves a ceviche which has squid and octopus, but since fish is still the recurring ingredient,(and because the other ingredients still look white) the model has trouble differentiating it from from the other types(minus one). Admittedly, even I have some trouble differentiating some of them if I can’t see the labels…
Hey @mduboc,
In this case I belive it would be difficult to have the Resnet train well on this problem.
Generally having reached human level standard is considered very good achevment for DL models. While they have sometimes exceeded human level recognition it might be difficult to do with only few added layers to ResNet.
If you have been doing deeplearning for a while, then you might consider training a new model or adding more layers in ResNet50.
If you are just starting out DL, then it might be better to work on a simpler problem now, and get back to this problem later on.