Your validation loss is still getting lower, so your model is still getting better at extrapolating. The model was able to learn more specifics on the training data and do better there, which is normal because all information relevant for the training data will not be relevant for the validation set. If your validation performance would start getting worse then you have overfitting because then it is learning information that is so specific it can no longer generalize (see it as memorizing the data it has seen). In this case, you seem to be fine, but keep an eye out if you continue.
1 Like
Could anyone please tell if these results are overfitting or underfitting?
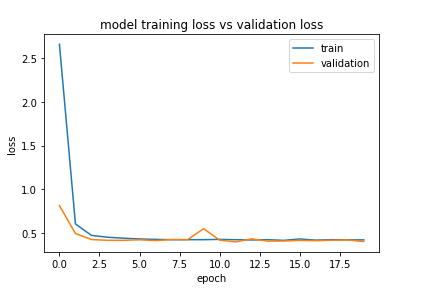
Hello, I’m a beginner here, and I also got similar results. Can anybody tell me if this is good results or not? Thank you.
I would suggest to stop the training at epoch 10, since afterwards no improvement is obtained. Moreover, both train and validation do have a likewise pattern, so no need to train further.
What to do next?
Either stop training at epoch 10 (epoch 20 is pretty much the same) or add some more data to improve generalisation.
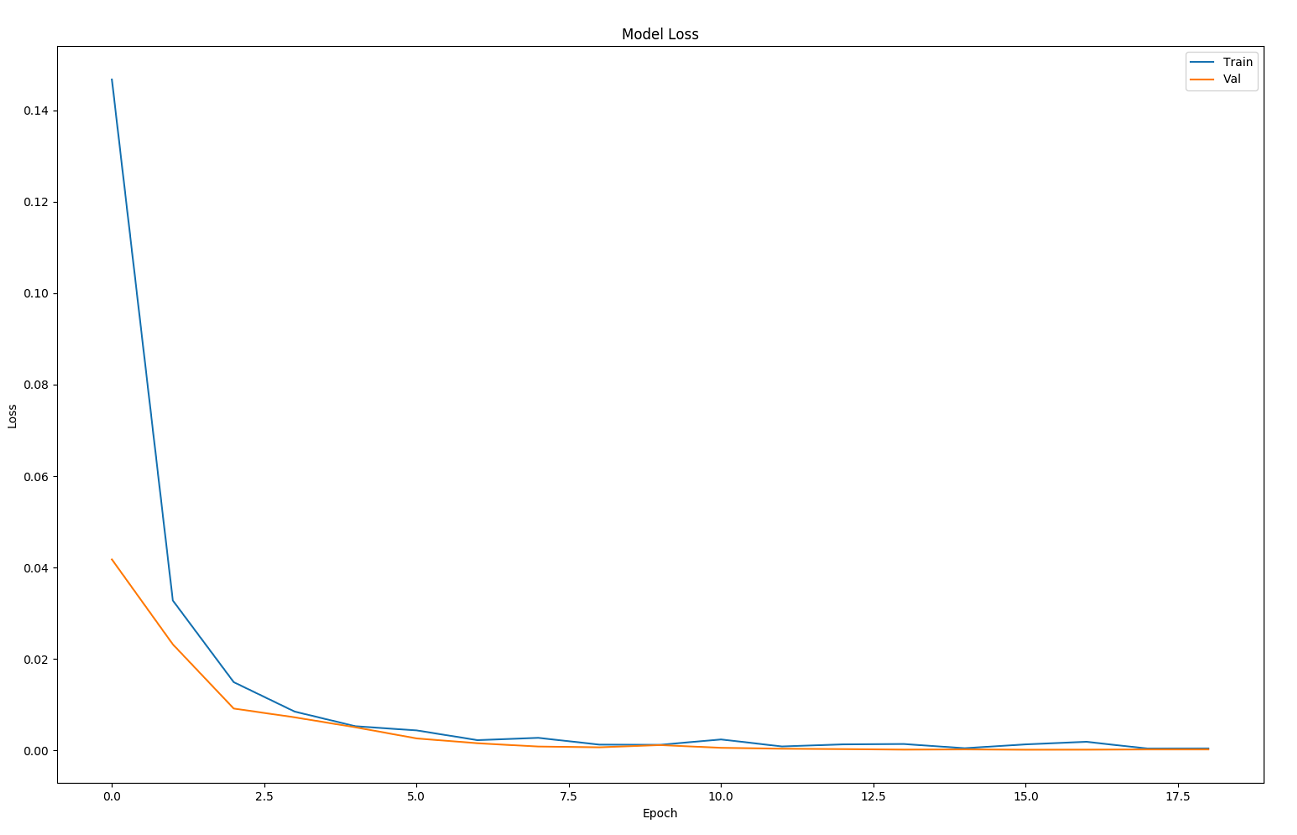
Hi, please can anyone help me understand this figure?
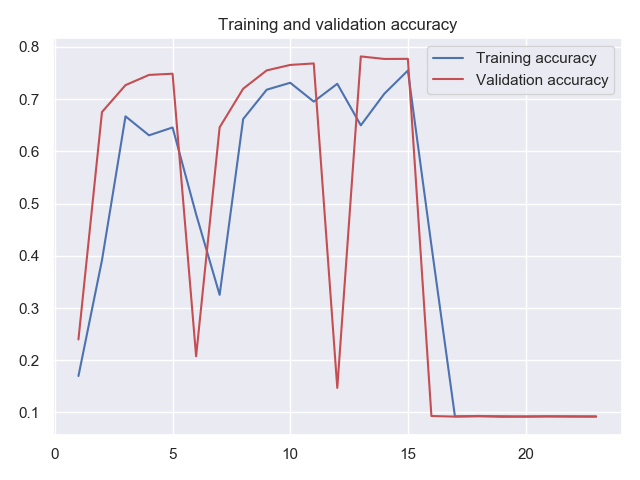
 I am woking on Fashion MNIST Dataset using CNN .after 50 epochs i get this result
I am woking on Fashion MNIST Dataset using CNN .after 50 epochs i get this result
am i overfitting or should i increase no. of epoch more.
Training Accuracy =94% ,Validation Accuracy=91%
Training Loss=0.12 ,Validation Loss=0.245
Wow! Awesome resource!
I believe you are overfitting. A good place to stop training would at 10-15 epochs.
Where do you find train_losses and validation_losses?
- Underfitting – Validation and training error high
- Overfitting – Validation error is high, training error low
- Good fit – Validation error low, slightly higher than the training error
- Unknown fit - Validation error low, training error ‘high’
its a good fit because train loss is equal to val loss @lakshmi2005 @benynugraha
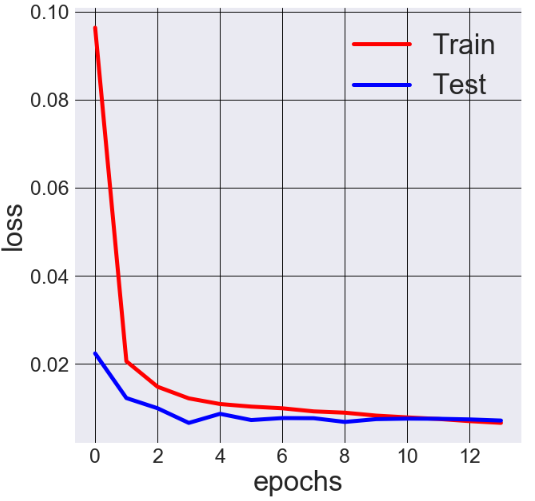
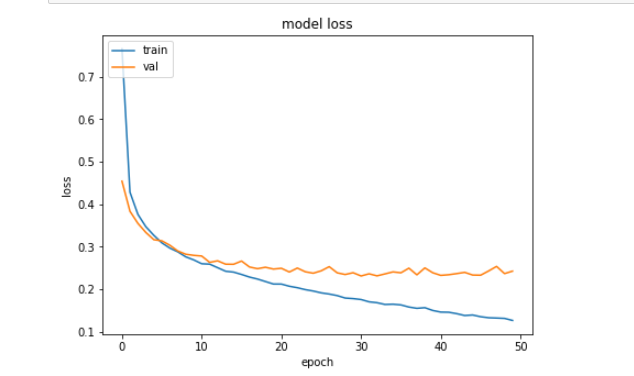
Can someone tell me how to interpret this plot. i wasn’t sure if this is a good fit because the val_loss (test=validation) is smaller than the loss(train).
I got this result with a dropout rate of 0.5, and a learning_rate of 0.001 in an lstm network
1 Like
You should stop it when training it at 10 epos. Do you see the red line is below the blue line? It means your machine is getting good at recognizing trained data but getting worst on unseen data.
1 Like
Hi, what about this result?
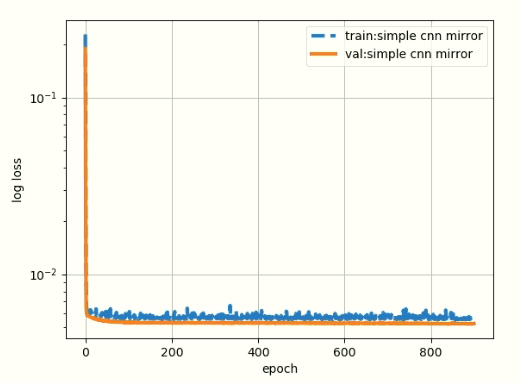
here is figure zoom from 1 to 100 epochs:
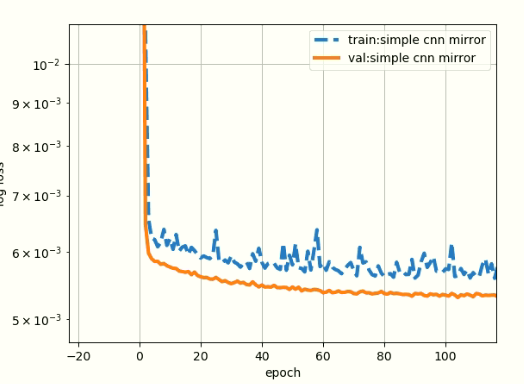
This thread has been very informative - thanks all!
Based on this information on cross-validation, I am randomly generating hyperparameters to find the best combination of params for my model. For comparing models, is it better to pick the model with the lowest loss? Or better to find a model where the loss and val_loss converge.
For example,
Case 1: Best loss is 0.15 (with the best val_loss being 0.27)
or
Case 2: Best loss is 0.18 and best val_loss is 0.185 (ie they converge)
Which case would be preferred?
Thanks!
I’m going to say you are underfitting
You’re training loss is always worse than your validation loss, and even though it’s bumpy, it trends proportionally higher than the validation loss throughout almost all of the training.
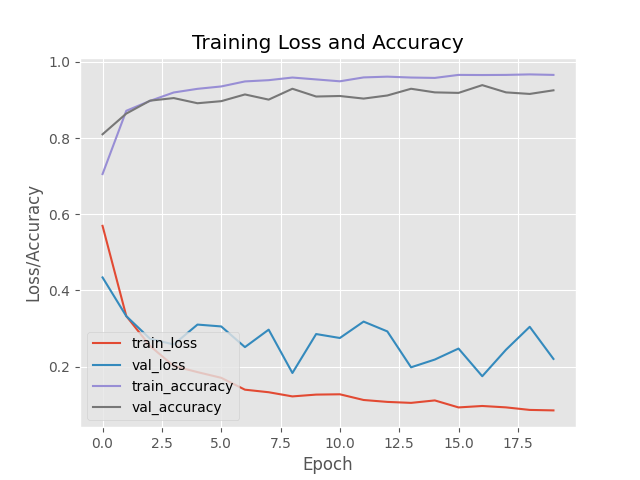
Hello. Can you please tell me if my model is overfitting?
Hey everybody, my validation loss has been consistently lower then my training loss no matter what parameters I change. Because of this, I first thought that the model did not know how to fit, but after doing some inference it turns out it works really well. Although it works as planned, I’m still really curious about what this loss function graph means. Do any of you know what is happening when my model is training, and most importantly what I subsequently can do to improve it?
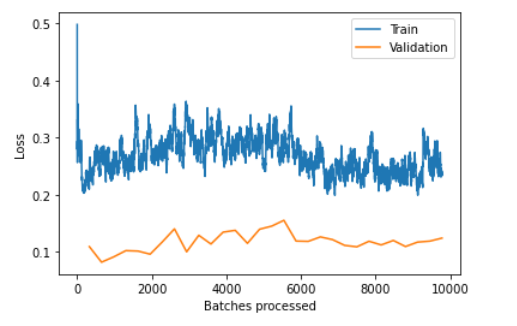
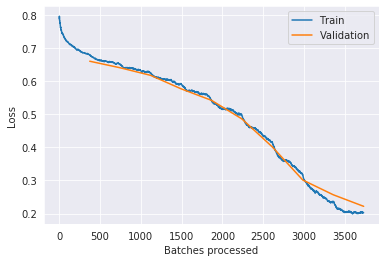
@wgpubs , others … is this underfitting or a good fit ?  thanks much
thanks much