Did you successfully do the lesson 3 in multi-gpu? There seems an error with that multi-gpu. I dont know if it comes from the model or what.
No, I also had issues there. Seems like some parts of the fast.ai library are not easily parallelizable.
I’m having some dificulties locating the file name of my predictions.
I’ve worked with the CamVid notebook and preformed a complete learning process and extracted the prediction as well.
unfortunately, when I saved the segmentation predictions to my pc they didn’t match to the original files.
Can it by that I’ve shuffeld my item list and that what caused the missmatch?
Any advice will be appreciated.
Can anyone elaborate on the accuracy_thresh?
I don’t understand why, but I just accept that accuracy_thresh is used when we need to get a prediction when we have multiple labels.
Does that mean that we have a tensor of these labels probability? For instance if we have 4 labels it would be something like [0.59, 0.67, 0.21, 0.89] and then we need to get a binary tensor outcome so we pass this tensor to a threshold function. So it will trigger the label if it’s above particular threshold? For instance if the threshold is 0.5 we will get [1,1,0,1]? And if so, is there a way to see these probabilities? And what’s a rule to choose a proper threshold? Why do we use 0.2 with the planet dataset?
Hey outfuture.
I think you are correct. The accuracy_thresh is used when there is a possibility of 1 or more labels. We choose the accuracy thresh to determine at what threshold do we consider a particular label to be present. Jeremy hasn’t mentioned much with regards to how to decide on the number, I imagine that might come in part 2.
You can run a prediction against a single image and return the outputs. See below where the image is a satellite image.
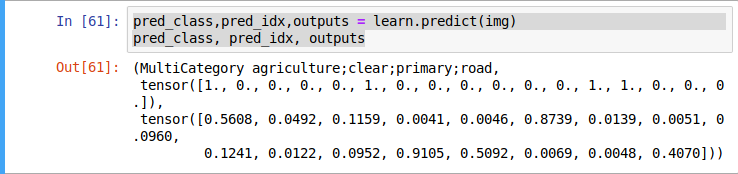
1 Like
Hey jolyon, sorry no one responded for a while.
I responded to another similar comment recently, looking at that might help.
The main difference in this particular model is that the prediction can have multiple labels.
In the cat vs dog models there is only one possible output and so what we do is take the argmax(max number of the 2 predctions) to categorise cat or dog.
In this case, however, we have 17 possible labels and the output can be any multiple of labels between 0 and 17. Because there are multiple options, argmax is not going to work here. What we do instead is provide a threshold to tell the model at what level of prediction do we want it to add each label.
So in this case anything where the model outputs above 0.2 is considered a positive label.
As you can see in this printout of a prediction on one image the accuracy_thresh has turned the second tensor in the list into the first tensor by giving all those predictions above 0.2 a 1 and all those below 0.2 a 0.
In the lectures Jeremy advises that the best way to work this out is to experiment and try different thresholds and use your accuracy measures to determine the best score.
Hope that helps.
1 Like
EDIT: Solution here
Hi,
While working on lesson3-planet notebook, when I try to create a ImageList with the code
src = (ImageList.from_csv(path, 'train_v2.csv', folder='train-jpg', suffix='.jpg')
.split_by_rand_pct(0.2)
.label_from_df(label_delim=' '))
There was an error saying: ImageList has no split_by_rand_pct attribute, so I have to change that into .random_split_by_pct.
But in the docs, I could only find split_by_rand_pct, not sure why this is the case. I have fastai ver 1.0.46.

This is an open source project trying to create custom line-segmentation model since Google-OCR isn’t doing great with line-segmentation on this kinda of wooden printed documents.
Here I thinking to use UNet architecture in fastai to segment out the individual line by predicting the line boundary given that red lines are the mask, which would label of this image. So is the UNet architecture suitable for this problem, if not is there alternative solution to this problem.
Any help would be highly appreciated 
I only reached lesson 3 and while reading the documentation I wandered if it is possible to add values to multilabel categories.
Let’s say I have 10 classes, and I can assign any of the classes to the image. But I can also assign value of 1-10 on strength of the value.
The desired output would be percentage or the value of each class in the image.
Is this possible ?
Hi Everyone (again),
I am trying to make sense of the output data that I get from multilabel segmentation. I asked a question before but I just realised it was a stupid question that shows that I do not fully understand how to do what I want to do.
I am editing the post not to waste everybody’s time, but I will still try to ask a (hopefully less stupid) question.
Basically I am trying to run the code from lesson 3 with my own dataset. That part actually seems to be going fine but I am having trouble with “result interpretation”.
The following code runs without problems:
from fastai.vision import *
path = Config.data_path()/'/MYPATH/'
path.mkdir(parents=True, exist_ok=True)
df = pd.read_csv(path/'MYCSVFILE.csv')
df.head()
tfms = get_transforms(flip_vert=True, max_lighting=0.1, max_zoom=1.05, max_warp=0.)
np.random.seed(42)
src = (ImageList.from_csv(path, 'MYCSVFILE.csv', folder='FOLDERCONTAININGIMAGES', suffix='.jpg')
.split_by_rand_pct(0.2)
.label_from_df(label_delim=' '))
data = (src.transform(tfms, size=128)
.databunch().normalize(imagenet_stats))
arch = models.resnet50
acc_02 = partial(accuracy_thresh, thresh=0.2)
f_score = partial(fbeta, thresh=0.2)
learn = cnn_learner(data, arch, metrics=[acc_02, f_score])
learn.lr_find()
lr = 0.01
learn.fit_one_cycle(5, slice(lr))
So, basically I am able to get my images (and I can see them with data.show_batch), create a databunch, donwload resnet50 with the imagenet weights, define accuracy and fscore partials and train the network with learn.lr_find(). This goes well (I can see a nice-looking plot with learn.recorder.plot().
Then I can change the learning rate and fit_one_cycle to obtain metric values (both for the acc_02 and f_score around 0.94 which actually sounds pretty amazing for the problem.
However, when I try to see a little more I get lost, I was asking about how to plot a confusion matrix… until I realized that that does not make much sense (every image has several labels, that is kind of the point). I would probably like to print the probabilities for every image in the validation set along with the correct labels. Of course if there is any way to visualize that I would also be most interesting in knowing that (and if not I will try to figure it out myself from the “raw” data.
Thanks for reading.
During lesson 3 you take a network trained at one resolution, then train it some more with higher resolution data. I’m confused about this. how is the image mapped to the same neural network. I thought the structure of the network was intimately connected with the resolution so when you increase the resolution you effectively change the dimensions of your first network layer… Is the data being magically modified to fit the network still, or is the network applied over any resolution and not directly connected to the training data due the the structure of resnet34? Thanks!
1 Like
There are adaptive pooling layers.
I had the same doubt. Try printing out learner.summary() after changing image resolutions and then observe pooling layers close to the output layer.
More details could be found about adaptive pooling classes at
https://pytorch.org/docs/stable/nn.html#torch.nn.AdaptiveAvgPool2d
scroll up for Adaptive Max Pool.
1 Like
So it was mentioned in the videos that the type of metric chosen while creating a learner could be anything. However if I use error_rate instead of fscore and acc, my fitting process throws an error. This has never happened previously. Kindly help me out.
This is the error
[RuntimeError: Expected object of scalar type Long but got scalar type Float ]
I am wondering why it’s necessary to pass vocab when we’re creating a classifier but not when we are fine-tuning the model?
Should not all the vocabularies be the same as the one that the initial model was created on?
1 Like
Hello everyone,
i’m having some troubles with unpacking:
! 7za -bd -y -so x {path}/train-jpg.tar.7z | tar xf - -C {path}
I’m using Gradient P5000 (as recommended) when i run this code the Kernel is busy forever (al least 30 minutes so far), the folder “train-jpg” is unaccessable, the whole paperspace crushes. Any suggestions?
Thanx,
Max
So if I understand correctly this adaptive layer just maps input to the next fixed size layer. In lesson @jeremy says that smaller images work faster than big ones. But I don’t understand how it is possible if both small and big images are “adapted” and all the following computations are performed using those new fixed size input
Thank you
1 Like
These adaptive layers are close to the output layer, so most of the computation is already done before activations reach them.

Hi everyone,
I have been stuck for the past day on unzipping the lesson 3 kaggle competitions downloads.
! kaggle competitions download -c planet-understanding-the-amazon-from-space -f test-jpg-additional.tar.7z -p {path}
I used the code supplied by fast ai :
! 7za -bd -y -so x {path}/train-jpg.tar.7z | tar xf - -C {path.as_posix()}
but get this in return.
Processing archive: C:\Users\john_doe.fastai\data\planet\train-jpg.tar.7z
Error: Can not open file as archive
I get a return message. Please I need some help in this basic stuff. I search the forum but couldn’t find an explanation for my problem
In lesson 3 where we build a language model for the imdb reviews, Is there a way to get the word embedding of each item in data_lm.vocab.itos after the language model has trained on AWD_LSTM?
In lesson 3 camvid, I am stuck in CAMVID download.
If I follow the url https://s3.amazonaws.com/fast-ai-imagelocal/camvid, I have an error message saying
<Error>
<script/>
<Code>NoSuchKey</Code>
<Message>The specified key does not exist.</Message>
<Key>camvid</Key>
<RequestId>EC57D45E44C3B178</RequestId>
<HostId>
66YsPiHYx6EKhCe0Cyhd322WPrBS43ThhGSoEOg2rVIMogDwHBBGtWSUfzNkpO7Z7o/gIt8LhLI=
</HostId>
</Error>
Do you have any idea why?
Answer: ok the real url is https://s3.amazonaws.com/fast-ai-imagelocal/camvid.tgz
I guess my real question is how to setup a proxy server to use
- untar_data
- download_data
- download_url
Looking at sources for download_url, there is a creation of Session (requests.Session()) and my understanding is that I should insert proxy setup after that? Don’t want to modify fastai code though…