got it! thank!
1 Like
Have a look at this topic:
what is this spec?
Here Jeremy says that we can fine-tune an already trained model, with its misclassified images and that it needs to be done for more epochs or with a higher learning rate. But what is the intuition behind the higher learning rate ?
I understand that misclassified examples are likely to be interesting but wouldn’t increasing the learning rate be harmful for a network that has already been trained ? Also, aren’t difficult examples likely to be particular cases, and retraining only on them will just overfit to those examples ?
3 Likes
Thanks for the reference. Unfortunatelly, the model does not train and it through an error when I try to train it:
learn.fit_one_cycle(1, 1e-2, moms=(0.8,0.7))
Maybe better actually is more epochs, instead of higher LR. I haven’t tried either - would be interesting to experiment.
2 Likes
One of the datasets we saw in Lesson 3 was Planet. The images in this dataset are 256x256 (called Kaggle chips) and were generated from satellite images with 6600x2200. So, one satellite image can generate several Kaggle chips.
My question: I have one (and only one) satellite image of 5500x5000 and I want to create a training with this. Is there a way I could use fastai to help me generate crops of this satellite image?
I mean, is there any transformation that crop random patches of an image?
Sorry for the late reply… spec should be: grey_im
no worries i got model to run on gray scale…
but the possible downside is m getting overiffited to Train data, diff between Tran loss and val loss is like .180 and .235
does reducing the color channels affects the ability of the model to generalize ?
with human eye it all looks clearly distinct what is object and what is background in grayscale… compared to colored image where some times both are not separable…
is this the way machine also looks ?
there was one parameter in tfms crop in old fai
that should be passed as CROP.CENTRE or CROP.RANDOM ,then it would take the sz parameter to accordingly slize the image
1 Like
How can we perform multi-label classification for text in fastai ?
I am not able to figure it out !
2 Likes
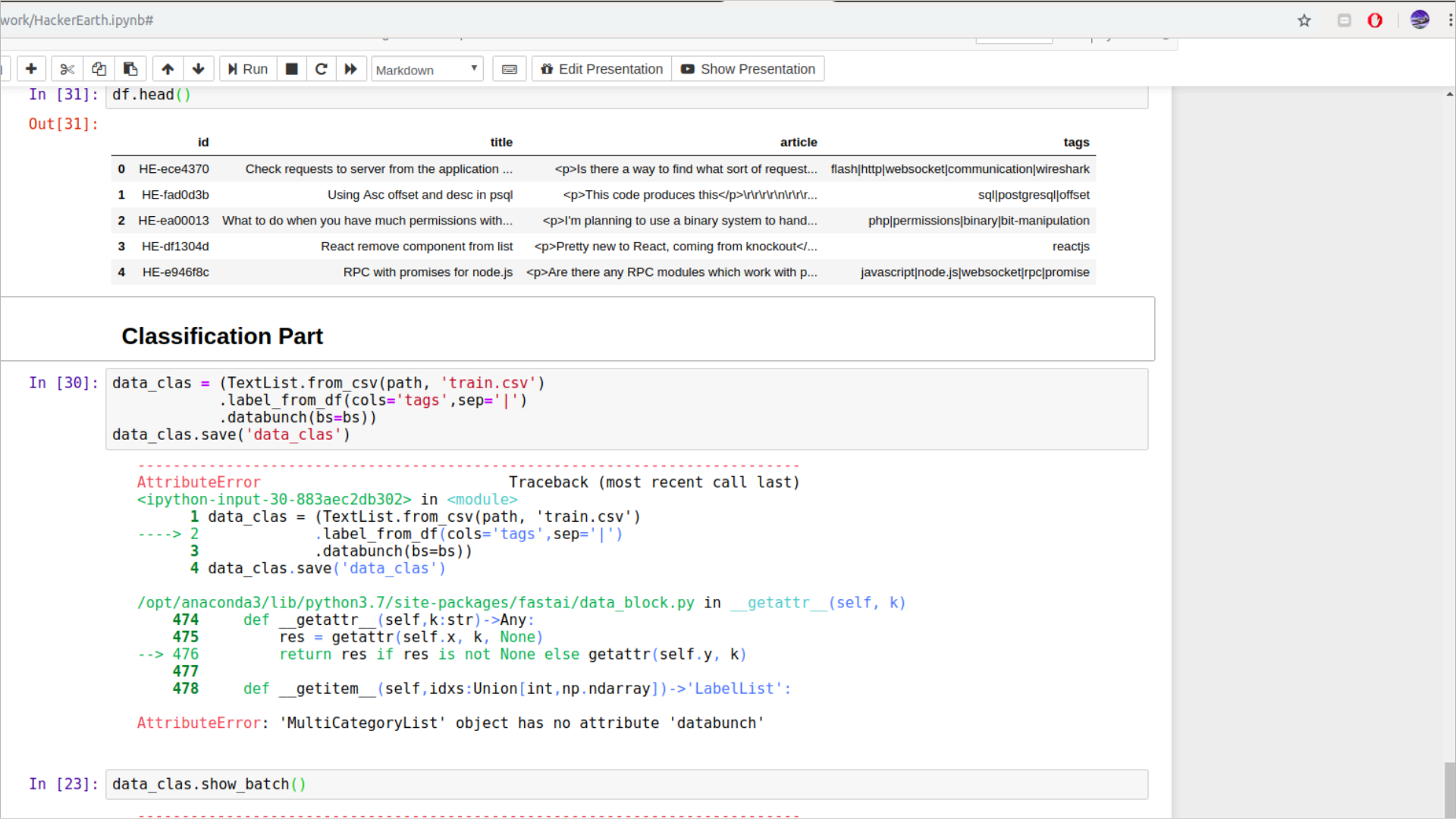
When I was making DataClasBunch from Data-Block-API, It shows Error of Multi-Label-List, Please Help me with this, why this is happening? @sgugger @jeremy
Hello, I’m trying to segment aerial images, and sometimes due to the weather conditions the “temperature” of images may vary so some of images are more blueish, and some are more yellowish.
Does anyone knows if there is a “vision.transform” operation to vary color aspect of the image to make my model more robust to the color changes?
I was thinking of imgaug library but I don’t know how to put it in Data Block API in the best way…
Thanks in advance!
hey, what dataset is this and what are you trying to predict?
Hi, could anyone give more explanation on how to choose the threshold for f_score, fbeta, and how does accuracy_thresh work? I’m kind of confusing how the accuracy_thresh computes…
3 Likes
has anyone seen any datasets for domain specific law, like compliance, etc…?
In one of the earlier lectures, Jeremy mentioned that the goal of setting a slice for max_lr in fit_one_cycle is so that when we’re training unfrozen model, the earlier weights will be trained with a smaller lr compared to the weights towards the latter end of the model.
In this lecture however, it’s shown that the lr starts from a low lr to the highest lr then it goes down again, which also make sense. If I understood it correctly, the graph is learning rate vs epoch. Does it mean that the learning rate is constant for all weights? Is this only for frozen model?
If it’s unfrozen model, does is still go through the learning rate cycle of low > high > low?
The graph you’re referring to is indeed the plot of the learning rate vs. training iteration (each successive minibatch in each successive epoch over the entire call to fit_one_cycle). You may find it helpful to refer back to the discussion of Leslie Smith’s “One Cycle Policy” in Lesson 1 (references below).
When the model is unfrozen, each layer in the network will have a similar shaped curve, albeit shifted upward as you get closer to the output layer on the absolute LR scale, in accordance with the LRs specified in slice.
1 Like
Thank you. This helps.
So if my understanding is correct, the lr slice is min and max of the overall learning rate. It’s just that when the layers are unfrozen, it will also increase (on top of thr cyclical lr) the lr as it gets closer to the output layer.
1 Like
Did you successfully do the lesson 3 in multi-gpu? There seems an error with that multi-gpu. I dont know if it comes from the model or what.