I believe @johnrobinsn uploaded a PDF version of his notebook too since his notebook file was too large and GitHub wouldn’t display it. So that might be one way to go? Also, since I assume the only issue is that you can’t open the notebook from GitHub directly, given that people can still download the file and open it locally (and/or on Colab) it shouldn’t be an issue, right?
Yes I could host it on the cloud but I wished for it to be easily readable on a webpage (aka, blog-like). And yes it’s not a ton of code, it’s the image outputs that have made the file so big. Right now I’m trying to use nbdev to convert it into a GitHub Pages blogpost…I think that should be possible. If not, I’ll check out GitLFS or any other cloud storage option. Thanks for your suggestions ![]()
1 Like
A PDF version is one way to go, yep! The issue isn’t that GitHub doesn’t render the notebook; it’s that I can’t even upload the notebook to my repo, because there seems to be a 25MB upload size limit ![]() @Fahim
@Fahim
You probably don’t even need nbdev - just use quarto.
1 Like
In the video about 59:33 in we are multiplying matrices m1 and m2. m1 has the shape of 5x784, this makes sense to me because we are grabbing the first 5 images from the mnist set. What I don’t understand is why we made m2 (the weights) 784x10. Why wouldn’t we have just done 784x5 for m2?
If this was asked already or I missed it in the video, I apologize. I couldn’t find anything searching through the forums.
There are 10 possible outputs - i.e. we need 10 probabilities returned, one for each digit.
Thanks for the quick reply. I just noticed that in the video looking over it again at about 1:01:01. ![]() Thanks for your time, Jeremy.
Thanks for your time, Jeremy.
1 Like
Hi everyone - This is my first time posting. Please let me share something I have been working on.
I would appreciate any feedback:
Noise diff for classification interpretability
I was curious as to whether diffusion models could provide better human interpretable explanations for classification results than existing methods such as Gradcam or SHAP.
Using noise prediction differences similar to those in DiffEdit, we can get some interesting results.
Problem: assume I have trained a horse/zebra classifier and want to understand why a given image is being classified as a zebra (and not a horse). This method attempts to highlight important parts of the input image
Input image:

Output image:

[heatmap version, sum of noise from steps 10-20]
As expected, the stripes seem to be the most important feature for explaining the prediction.
Rat vs Mouse:
Input:

Output:

[Non-heatmap version sum of noise from steps 30-40]
Ear, nose and eyes appear to be important, the main part of the body is not.
Sports car vs taxi
Input

Output

[Heatmap version sum of noise from steps 20-30]
The spoiler on the back of the car seems to have been highlighted as important, as well as lights and possibly wheel trims.
Note the “negative” highlighted box on the top of the car. Could this be indicating that the lack of the TAXI “roof light” is a reason why the image is not a taxi?
Indeed, if we look at the comparison with the empty/unguided prompt (see 2. In Method below), this box disappears:

[Sports car vs “empty prompt”]
Method:
-
Take input image and add noise to the image according to diffusion model schedule (resulting in an array of e.g. 50 noised images)
-
For the labels to be compared, perform noise prediction on each of the noised images from 1. using the classifier labels as prompts (e.g. “zebra” and “horse” prompts). Alternatively, use the target label and the empty prompt.
-
Keep track of the noise predictions for each noise image (but do not apply the noise predictions to the images themselves as in normal diffusion process). The end result is two arrays of noise predictions for the two prompts.
-
Create the noise difference array by subtracting the noise predictions from 3. Sum the values of this array for different ranges (e.g. 0-50 or 10-20).
-
Visualise the noise differences
Still to do:
Instead of using the Stable Diffusion pretrained model, train a diffusion model on the specific dataset that the classifier was trained on. Compare results with other methods (e.g. Gradcam, SHAP).
Heavily based on the lesson 9 Stable Diffusion Deep Dive notebook
9 Likes
That’s rather weird … I mean the 25MB upload limit since there are repos with files which are several gigs in size … I have a notebook which is 32MB on a repo, like this one:

I don’t know why you’re having issues with a 25MB upload, but possibly something to try (if this is the initial commit/push) would be to start with a small file and then replace that with the 25MB+ file and see if that works?
1 Like
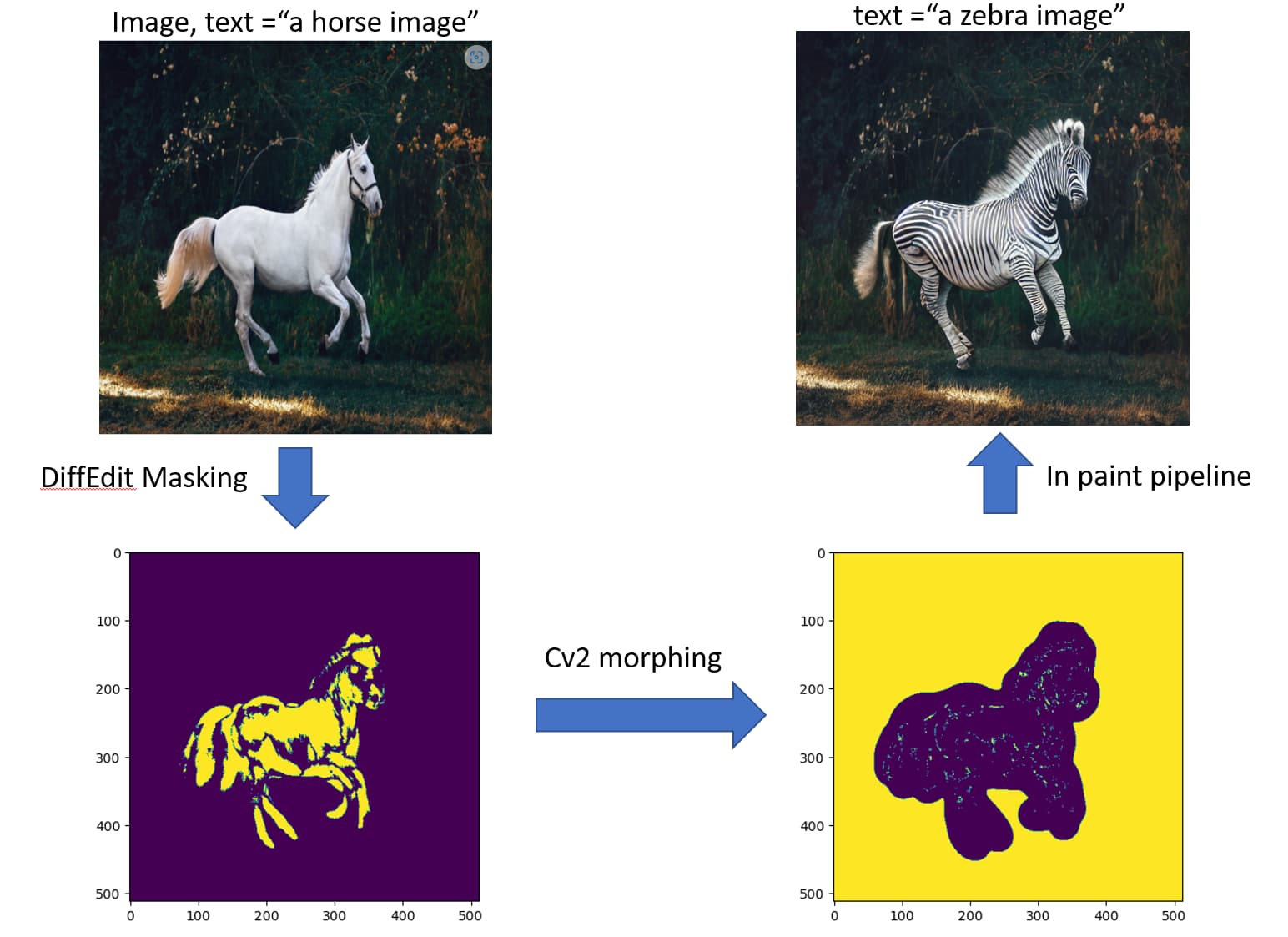
@charlie, the results you shared on implementing DiffEdit paper on twitter are amazing. I would love to see what your masks looked like and how you achieved that.
I stuck to using the LMSDiscreteScheduler and only things introduced in the lesson 9 deep dive notebook. I am having the most trouble getting the mask to be good. In all my masks there are patches missing. I am going to try some other tricks mentioned here by others too. I am already using some of them.

Here is another example to show that my masks are not great:

3 Likes
I managed to get the masks to be slightly better using some of the methods here but then they became a bit too broad/not so well defined. Jeremy suggested that OpenCV might be the way to go and I noticed that a few others had used OpenCV too. Possibly some research in that direction might help? That’s what I intend to do today if I can find the time …
1 Like
Yea I saw what you had did. It’s cool!
I was gonna give it a try.
I actually already tried some of the tricks others have mentioned as well (such as the max of the two differences). I’m using that trick. I just thought there would be a way to do it without cv2 etc. The authors of the paper made it sound like a simple normalized difference but maybe some details were left out.
1 Like
Authors are using 64x64 images, so not sure if it works on higher resolution images. Also, they are not using VAE in b/w for encoding / decoding which in my theory is making our masking a little more problematic. Besides, author says that mask bigger than the object is usually a good idea which we can achieve through cv2 library. In the updated notebook I shared, I am also using the max of two differences tricks, results are definitely improved over the first version.
2 Likes
I noticed that you are using latents = scheduler.step(noise_pred, t, latents).pred_original_sample where I am using prev_sample. I looked this up a little bit, but the explanation doesn’t quite make sense to me. Here is what the docstrin for the DDIMSchedulerOutput says:
Output class for the scheduler’s step function output.
Args:
prev_sample (torch.FloatTensor of shape (batch_size, num_channels, height, width) for images):
Computed sample (x_{t-1}) of previous timestep. prev_sample should be used as next model input in the denoising loop.
pred_original_sample (torch.FloatTensor of shape (batch_size, num_channels, height, width) for images):
The predicted denoised sample (x_{0}) based on the model output from the current timestep.
pred_original_sample can be used to preview progress or for guidance.
1 Like
For the mask, can’t you to try to do some blurring and clipping to get a finer mask. Anyway, gonna try that later.
Thanks for the notebook & ideas.
2 Likes
Stability AI released a new set of fine-tuned VAE decoders . The results look interesting, especially for human faces.
3 Likes
Hi @jeremy! Thanks for the suggestion. Actually, I’d set up a basic blog months back, using this post of yours. When I saw your reply suggesting Quarto I was in the middle of using the post “Blogging with Jupyter Notebooks”, so I decided to see it through to the end before checking Quarto. It’s been 9 hours since I pushed the .md file to my blog repo and the post still hasn’t shown up on the site, so investigating a bit, I just discovered that fastpages is now deprecated and that Quarto is the way to go:
From Quarto FAQs:

Would you then say that this Quarto tutorial is the most -up-to-date doc to refer to for putting up a blog using notebooks?
(Sorry about the long post! Just wanted to document the process, for anyone who might be trying to do the same. Thanks for your time ![]() )
)
Interesting. Yes, it is my first commit/push to my repo, so I’ll try your suggestion and see if that works! ![]()
I am having an issue with loading the CLIPTextModel. Specifically I am loading the model using the command:
text_encoder = CLIPTextModel.from_pretrained(“openai/clip-vit-large-patch14”)
I then get a very large warning message starting with: “Some weights of the model checkpoint at openai/clip-vit-large-patch14 were not used when initializing CLIPTextModel: [‘vision_model.encoder.layers.8.layer_norm2.weight’, ‘vision_model.encoder.layers.6.self_attn.out_proj.bias’, ‘vision_model.encoder.layers.19.layer_norm2.weight’, ‘vision_model.encoder.layers.19.layer_norm1.bias’, ‘vision_model.encoder.layers.22.self_attn.out_proj.bias’, ‘vision_model.encoder.layers.5.layer_norm2.bias’, ‘vision_model.encoder.layers.11.self_attn.out_proj.bias’,”
Does anybody else get this, I didn’t see it on Jeremy or Johno’s notebooks. I have transformers version 4.23.1 installed and am running on the great Jarvislabs servers. Is this something that can be ignored?