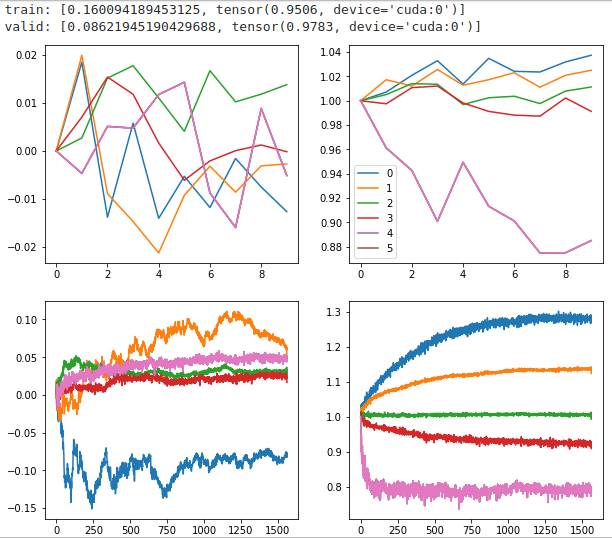
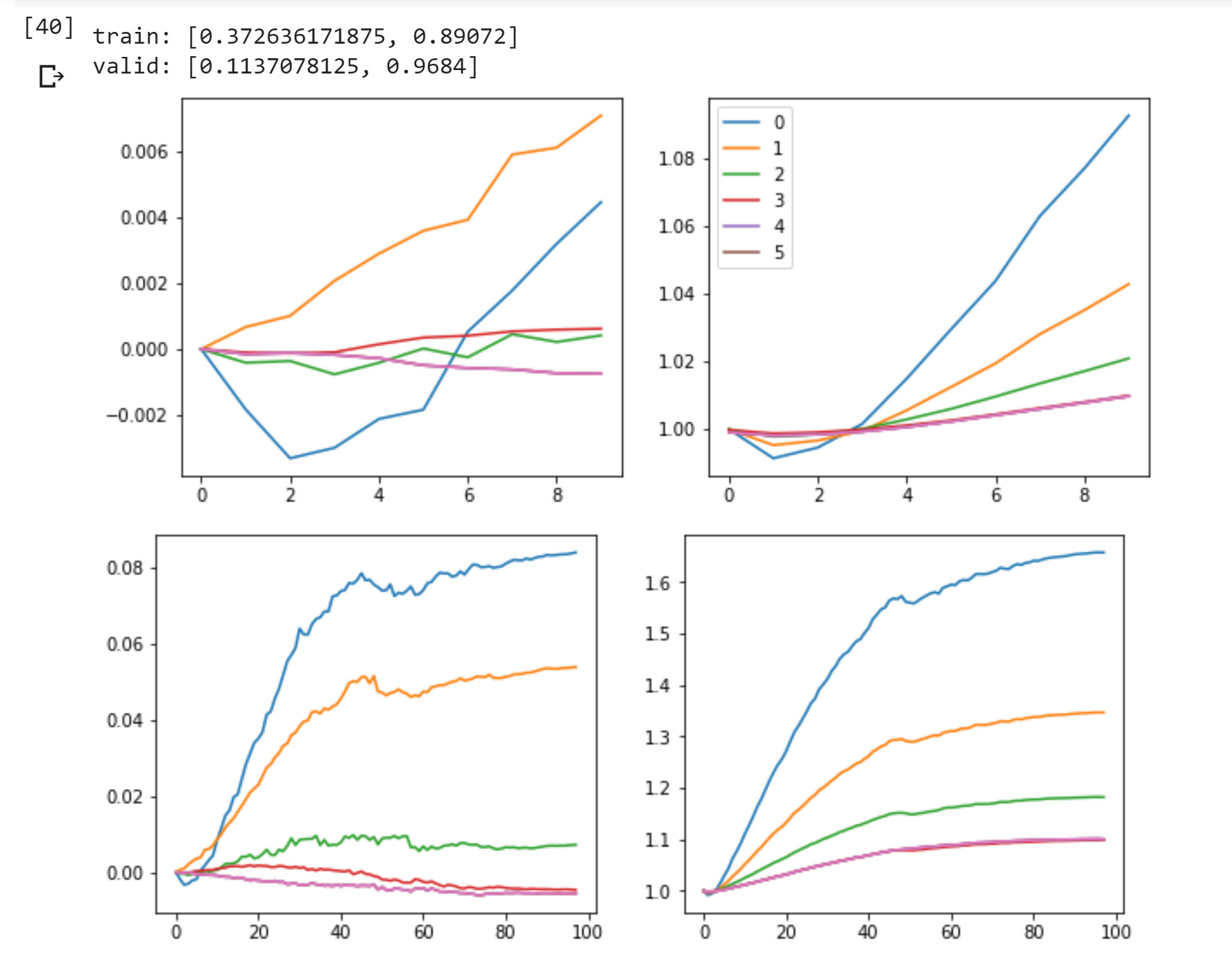
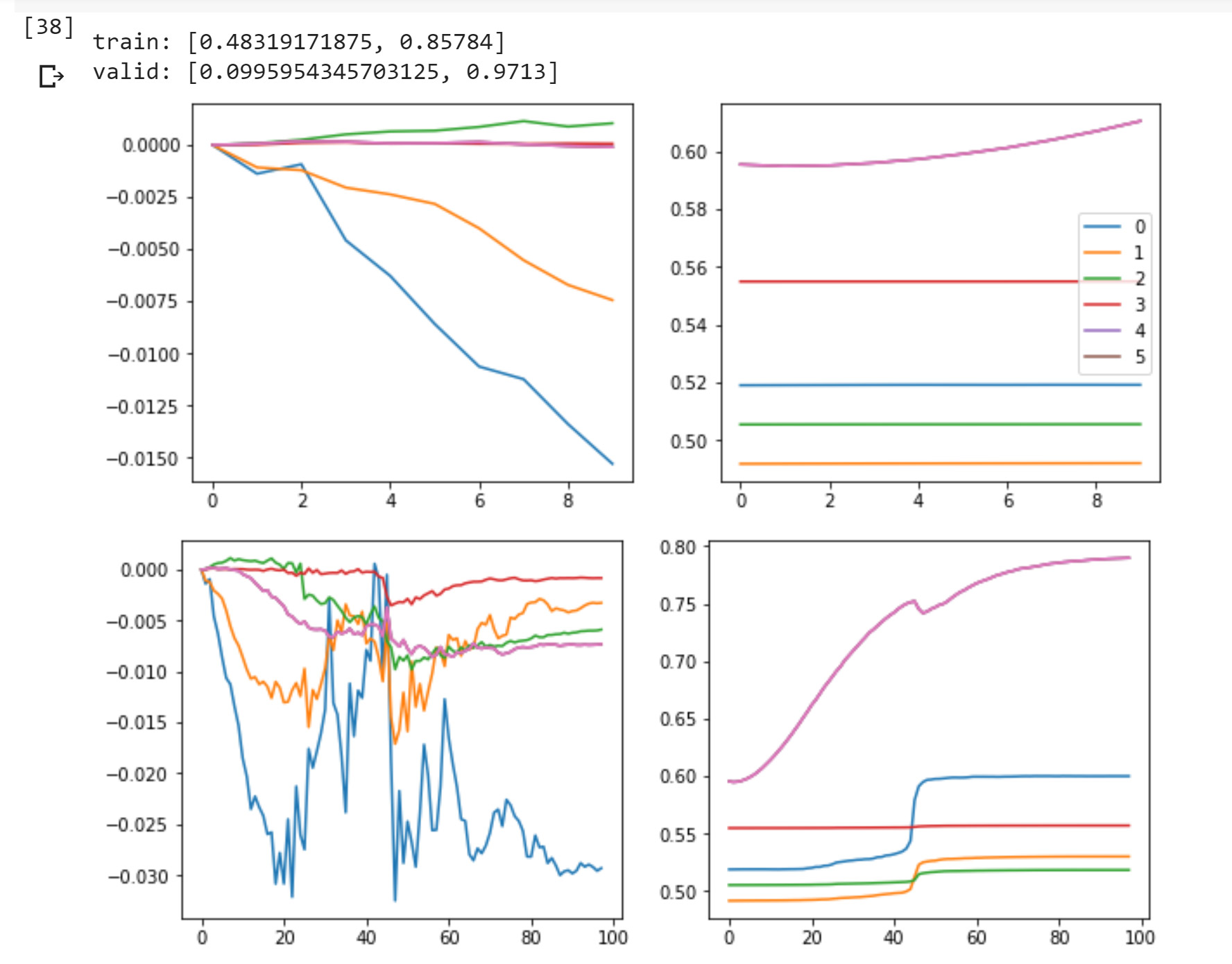
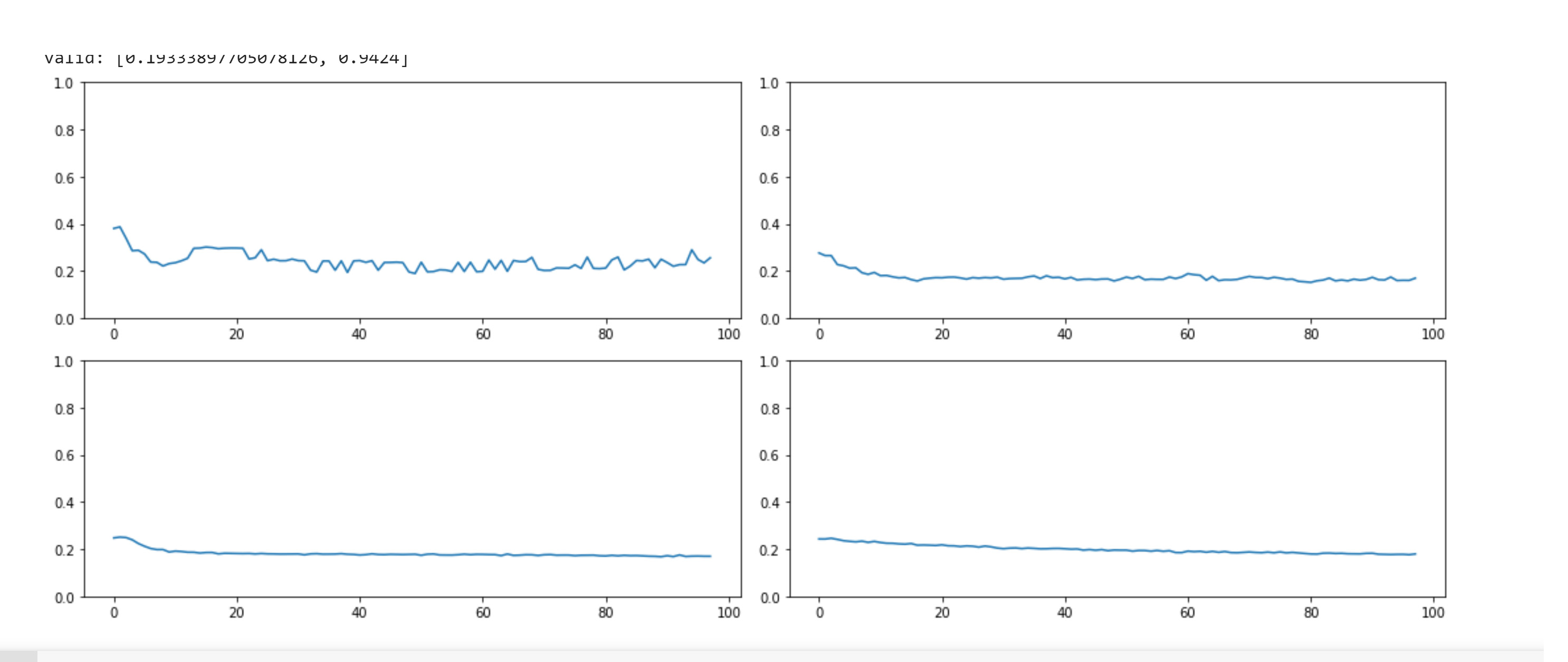
So I was revisiting lesson 10 and had the same thought. We have this awesome GeneralRelu, why don’t we just learn all the parameters instead of predefining them. So i searched around to see if anyone on here had done it and i couldn’t find anything.
So I went ahead and implemented “LearnedRelu” which was super easy (assuming i did it right):
class LearnedRelu(nn.Module):
def __init__(self, leak=0.1, sub=0.25, maxv=100):
super().__init__()
self.leak = nn.Parameter(torch.ones(1)*leak)
self.sub = nn.Parameter(torch.zeros(1)+sub)
self.maxv = nn.Parameter(torch.ones(1)*maxv)
def forward(self, x):
x = F.leaky_relu(x,self.leak.item())
x.sub_(self.sub)
x.clamp_max_(self.maxv.item())
return x
So far it seems to work great. I started a separate thread on the topic with a gist of my work so far here: https://forums.fast.ai/t/learning-generalrelu-params-here-is-learnedrelu/44599