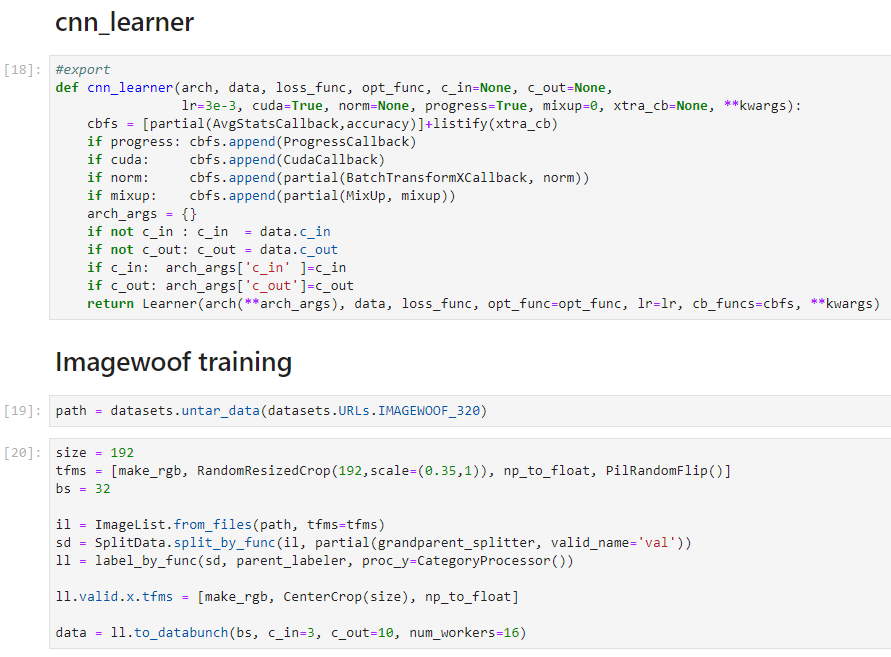
So going back to lesson 10 and studying the concept of batchnorm and learnable parameters gave me an idea. Thanks to the more general and abstract representation of GeneralRelu, it becomes clear that we should just learn the parameters of GeneralRelu since this will let them vary throughout the phases of training and also to vary by layer. On my own i have no intuition for how leaky or how much shift should be added to the relu on the first layer versus the relu in the middle versus a relu at the end, but the NN probably knows. So why don’t we just start with some sensible general parameters and let the model adjust as needed?
That’s what i did here:
Disclaimer This code didn’t work as anticipated. The new relu parameters weren’t training becuase i had to call .item() on them to get the associatged functions to work.
class LearnedRelu(nn.Module):
def __init__(self, leak=0.1, sub=0.25, maxv=100):
super().__init__()
self.leak = nn.Parameter(torch.ones(1)*leak)
self.sub = nn.Parameter(torch.zeros(1)+sub)
self.maxv = nn.Parameter(torch.ones(1)*maxv)
def forward(self, x):
x = F.leaky_relu(x,self.leak.item())
x.sub_(self.sub)
x.clamp_max_(self.maxv.item())
return x
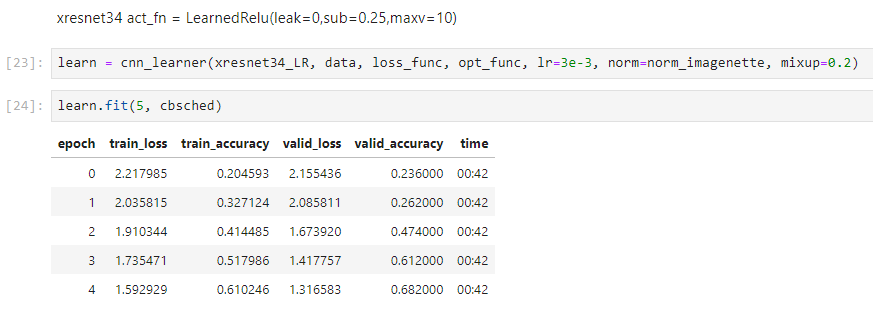
In my initial experiments it’s worked great so far. The telemetry is much smoother and the model achieves higher val accuracy more quickly on mnist than with predefined relu.
The mnist task seems too easy though so I’m going to apply this to Imagenette next and then to image woof to see if we can start to see the impact more clearly.
For now here is a gist of my work as applied to the 07_batchnorm notebook:
I think a logical next step is to convert this to a running average of the learned parameters. But for now i’m focusing on this version. Another idea is to freeze the learning of the RELU parameters after, for example, half the epochs have been completed, so that the network has a chance to find good relu parameters but then also has the benefit of stability after “good” relu parameters have been learned.