append_stats is implemented twice: the 1st time it is given an index i so that it knows which list in the list-of-lists it appends to; the 2nd time it is given a hook so that it knows to store data inside that hook instance.
m.register_forward_hook is a Pytorch functionality attached to any instance on nn.Module m, and allows u to define a hook to module by passing it any function, with one catch: the function has to have 3 and only 3 args, (mod,inp,outp)
Jeremy/Sylvain’s workaround is to “preload” the function to be passed with other args beyond those 3 so that by the time it is passed to the pytorch, it (the function) has access to all the (directions, access, references) it need to write the data, (here stats) wherever it needs to.
thats where partial comes in, it preloads the function with index in the 1st implementation of append_stats; it preloads the hook instance itself that is created with that function, in the 2nd final implementation.
so when u call the constructor of Hook with a function f that we know takes 4 args, its gonna preload it with the first arg (the instance itself) which is the destination of all the writing append_stat is going to do, and be “disguised” as a 3 args-function for Pytorch
I am attaching a link to my UBER-annotated version of the notebook where I comment any line of code that does sth significant. Very verbose, but thats how I helped myself understand what is going on, while watching video the 2nd time and running the code.
Thank for the quick and detailed answer.
The part that confused me was that I thought the register_forward_hook is a function that require three parameters, but I now understand from your answer that it require a function that has three parameters.
This way the implementation totally makes sense.
Thanks again.
The Input Size = 28x28, Kernel/Filter = 5 , Padding = 2, Dilation = 1 (default) and Stride = 2 and the Output (in commend I presume) is indicated as 14
Based on the formula from Pytorch documentation, the output height(or) width should be
Output(h) = [{28 + 2 x 2 - 1 x (5 -1) -1}/2]+1
ie., = [ (28+ 4 - 4 -1)/2]+1
= 14.5
How did Jeremy infer as 14 there? Can anyone help me understand?
Could you explain a little more. I see that he took the softmax. next when he said binomial(ie sigmoid which is softmax with 2 classes) . AM i missing something here?
In the entropy_examples.xlsx Excel spreadsheet, Jeremy compared the Softmax method with the Binary classifier for each class approach. Note that the Binary classifier for each class approach was mislabeled as binomial in that spreadsheet.
In my Lesson 10a presentation, I discuss softmax and the entropy_examples.xlsx spreadsheet.
@charming This bit of code seems superfluous, since as far as I can tell, it always returns False. Even if it didn’t always return False, it seems unnecessary to sort (and therefore to use x._order). Can you (or someone) provide a simple practical example where _order is used and why it’s necessary?
Nope – you’re misinterpreting your results. Your model is broken. It’s returning a loss function of None, and and accuracy of less than 10%, which is essentially a random guess.
This is what i understood:
First Multiclass vs Multilabel:
Multiclass classification means a classification task with more than two classes; e.g., classify a set of images of fruits which may be oranges, apples, or pears. Multiclass classification makes the assumption that each sample is assigned to one and only one label: a fruit can be either an apple or a pear but not both at the same time.
Multilabel classification assigns to each sample a set of target labels. This can be thought as predicting properties of a data-point that are not mutually exclusive, such as topics that are relevant for a document. A text might be about any of religion, politics, finance or education at the same time or none of these.(https://scikit-learn.org/stable/modules/multiclass.html)
So MNIST is Multiclass and Planets dataset is Multilabel.
Categorical Cross entropy loss - softmax + NLL, for multiclass problems
Binary cross entropy loss - sigmoid + binary log likelihood, for multilabel problems
Softmax tends to push one value higher than the others. So this is suited for Multiclass problems. As you want to predict a single class.
In Jeremy’s example we had img1,img2 with the following labels - cat, dog, plane, fish, building. This means that your training your model to predict wether the image has a combination of cat, dog, plane, fish, building. So if you use softmax now you are only going to push one of those labels. When in reality your image could have had a dog and a cat. So if you use sigmoid for each of these 5 labels and set a certain threshold value you can find out which of these labels existed in the image.
Softmax is great when you have exactly one (no more than one and definitely at least one) of the classes.
softmax is a good idea for language modeling where we want to know what’s the next word. it’s definitely one word and not more than one word.
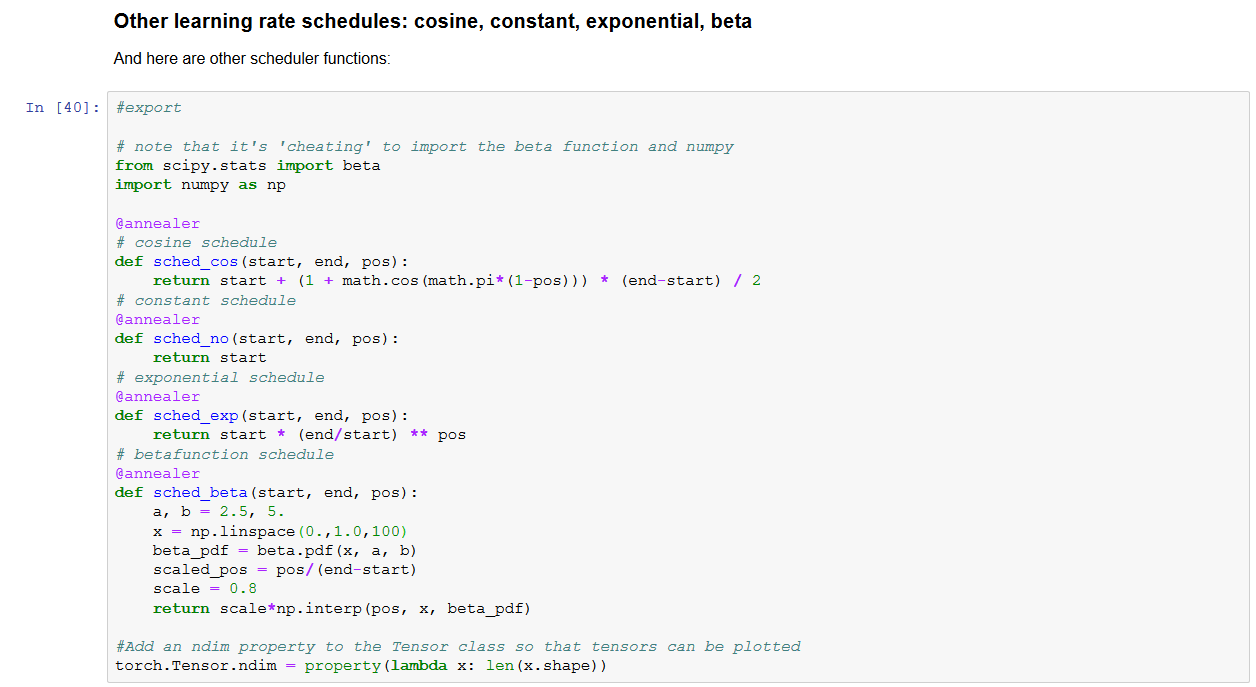
The TWiML Deep learning From the Foundations Study Group repo now has an updated version of 05_anneal_jcat.ipynb that adds a beta learning schedule.
The beta probability distribution function (pdf) is defined on the interval [0,1], and has a varying shape that is controlled by its two input parameters a and b.
When a and b are both greater than 1, the beta pdf is positive and convex on the interval [0, 1] with zeros only at the endpoints, allowing the construction of an infinite variety of smoothly continuous learning rate schedules that start and end with a learning rate near zero.
See the purple curve in the plot below.
You can adjust the shape of the beta pdf schedule by varying the values of the parameters a and b.