At the end of the video Jeremy suggests trying running the image classification with our own image set.
How do you go about it?
My understanding is that I need to download a bunch of images two different objects and put those in different folders, but I am not clear on the folder naming or location.
The current dataset folder structure looks like this:
ls data/dogscats/
models/
sample/
test1/
tmp/
train/
valid/
Let’s say that I want to classify bears and deer. I assume that I need to create a folder in data/bearsdeer/train/ and put a bunch of bear and deer images in that. After that put another bunch bears, deer and other images in data/bearsdeer/valid. Is that correct?
What are the other folders for and do I need to worry about those?
Let’s say I got 100 images of bears and 100 images of deer.
How many of those should I put the sample folder?
How many in the test1?
How many in the train?
How many in the valid?
Do you know of a website that I could download a larger data set of animals? I was going to download images from google image search manually. Is there a faster way?
I used the Fatkun batch download extension for chrome (suggested in this forum) and downloaded the images(*.jpg) in a SD card. What is the preferred method to split the images into the folders? I am using paperspace from a chromebook.
I found this script from part 1 v1 to create the data folders but don’t know what to do with it: Kaggle Questions
Could someone help me understand how I get the images I download to be available within Paperspace? The folder structure for separating the images makes sense to me, but I’m not sure how to get the images from my laptop to the Paperspace instance.
So, for example, I used the Image Downloader Chrome extension to grab several basketball and soccer photos from Google images. That process saved them to my Downloads folder on my laptop. What command within terminal on Paperspace do I use to grab the dataset from those folders?
If I’m supposed to do it entirely through Paperspace terminal, I’m not sure how to grab several images at once without using a browser. Any tips?
where the xxx.xxx.xxx.xx is the Paperspace IP address.
The bracket notation {1…10} lets me transfer all of the files inside the cricket folder at once, where each file ends in the numbers 1 through 10, e.g. cricket1.jpeg.
This thread helped a lot!
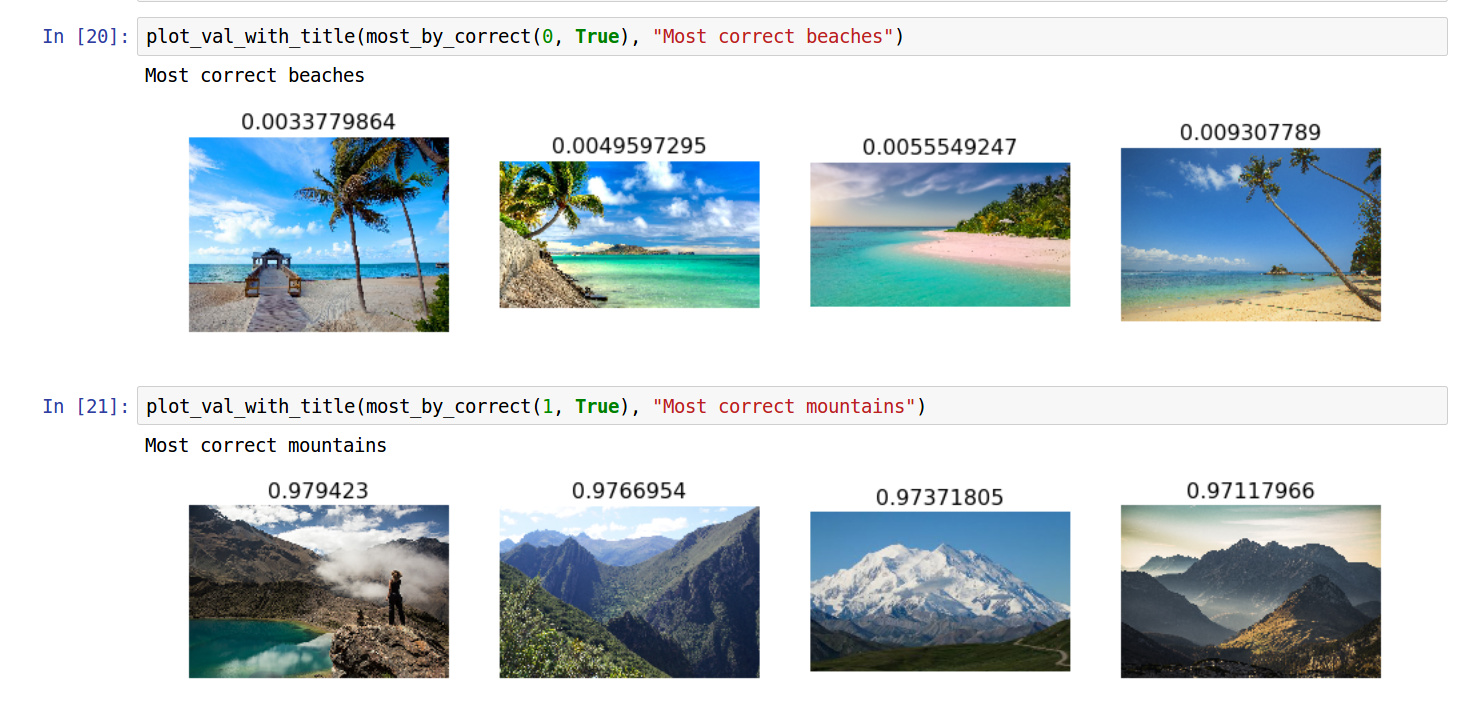
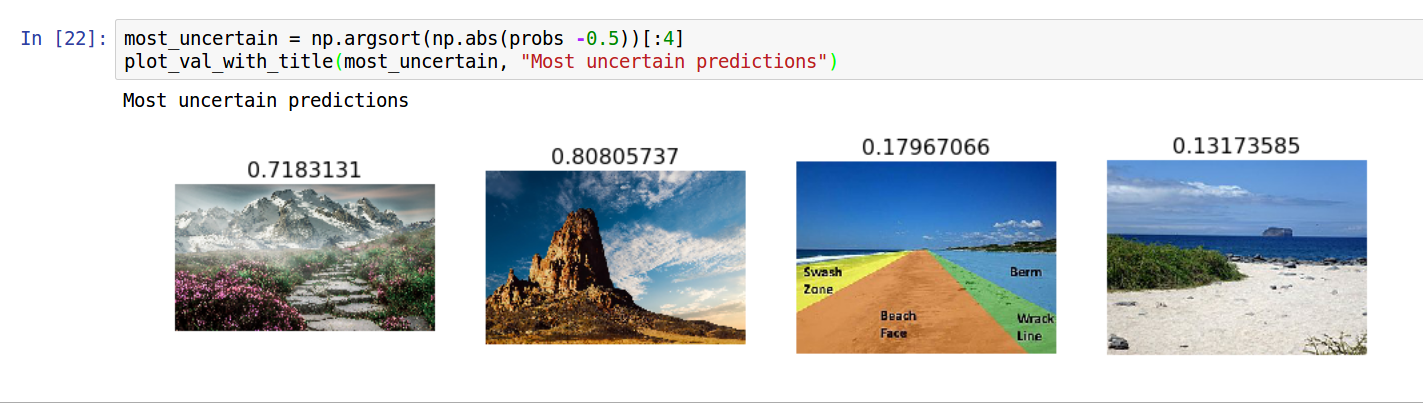
I tried to classify images of beaches and mountains. Created a small dataset of about 80 images in my own system and used scp to transfer the whole folder at once to Paperspace machine.
As mentioned by Reshama, I created a separate folder called Project in the home directory of Paperspace, and that is where I’ll be doing all my experiments. So ‘/home/paperspace/projects/beachesmountains’ would be the PATH in lesson1.ipynb notebook.
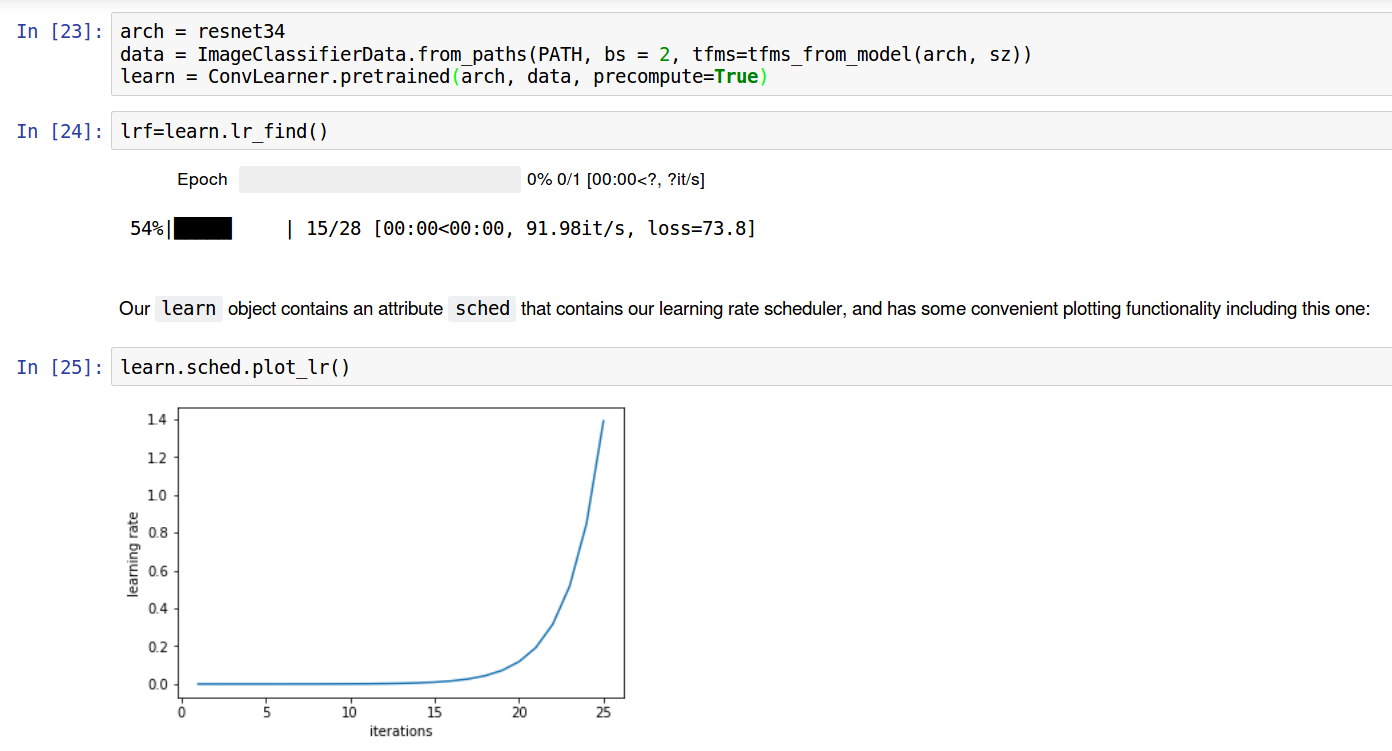
Tried using LR finder with a reduced batch size (of 2) to find optimal learning rate, but since the number of images is very less, didn’t get decent plot. So with hit and trial, settled on 0.01 as the learning rate.
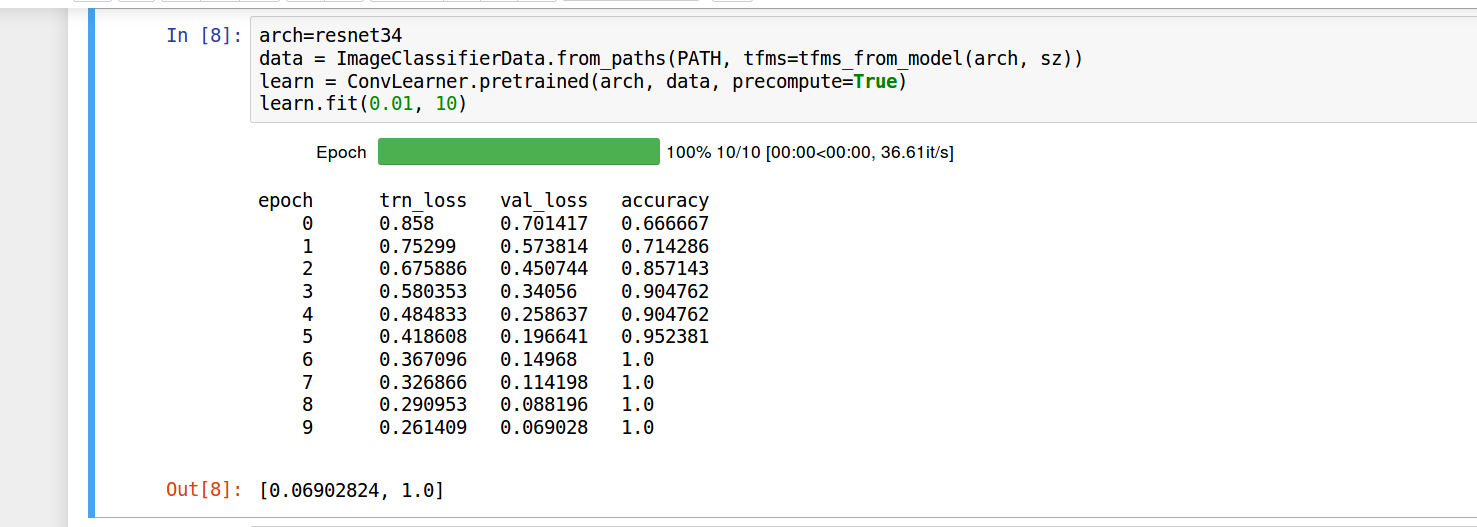
I got 100% accuracy pretty quick. Probably because the first 40 images of either category downloaded from Google Search are pretty recognizable, and binary classification in such a scenario would not be too difficult.
One thing I could not understand was that the training loss was higher than the validation loss. However both of them kept decreasing even after a number of epochs (after 100% accuracy), indicating that the model was becoming surer of its predictions.
Great results!
Looks like you got 100% accuracy even though the training loss is relatively high (which usually means underfitting data), and you got these pretty quick. Maybe next you could try something more difficult (rivers vs oceans?), so then you’ll have to adjust learning rate, augmentation etc.
By the way someone else wrote a utility to download many google images here, I haven’t got to trying it yet.