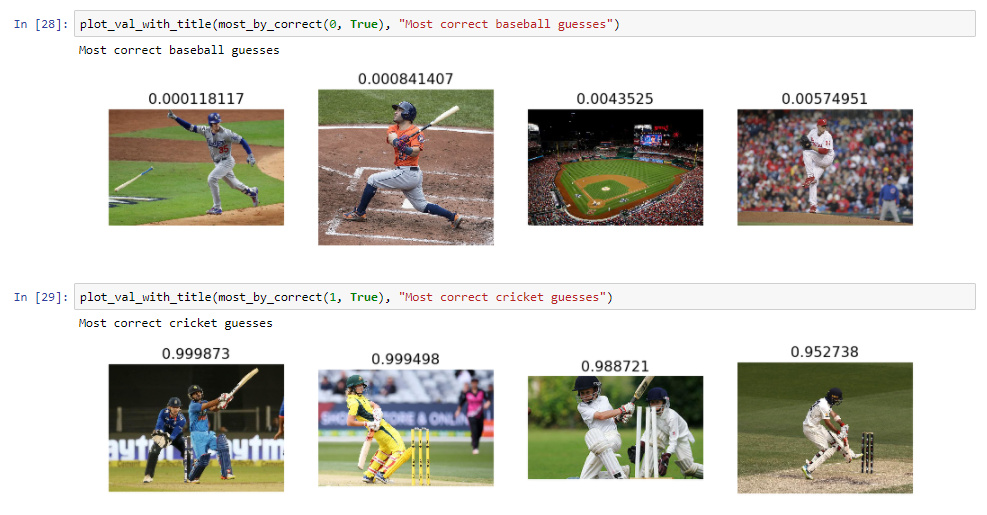
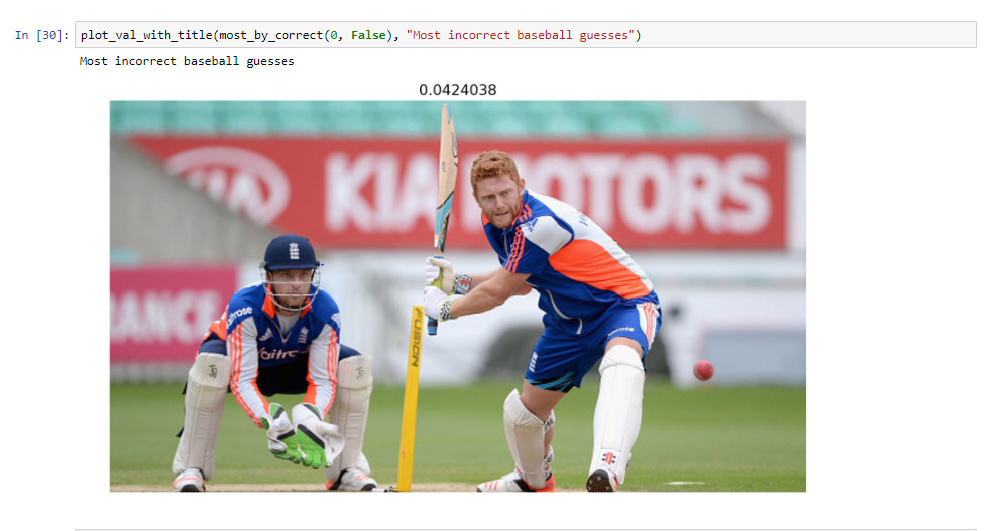
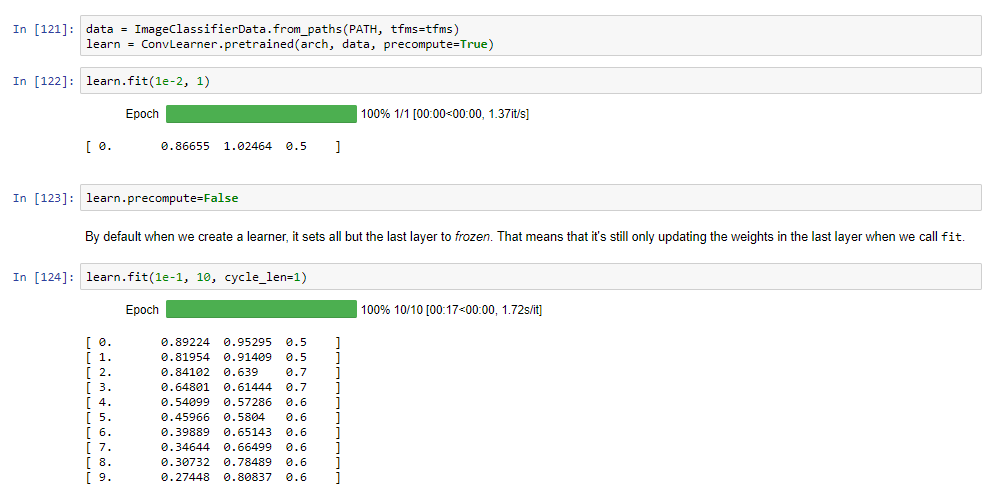
I wanted to explore building a custom classifier using lesson 1 as the template. Cricket and baseball are two sports with similar ‘features’ so I tried to distinguish between them. I was able to get reasonable accuracy (90%) with 15 training images. I followed these steps:
Google Image search for ‘cricket’ and ‘baseball’
Download 20 images of cricket/baseball each.
Use 15 of these for training and 5 for test (valid dir) and run the lesson1 python notebook.
After playing around with the model I saw that a learning rate of 0.1 gave good results. I got an accuracy of 90%, classifying 9/10 images correctly. Since the number of training images is tiny, I did not really use the lr_find() tool to find the optimal learning rate.
Also, I noticed that unfreezing/data augmentation did not have a much better effect on performance. My guess is the number of images was too small for the initial layers to generalize from and it would be better off to take advantage of the pre-trained weights from the resnet model as much as possible.
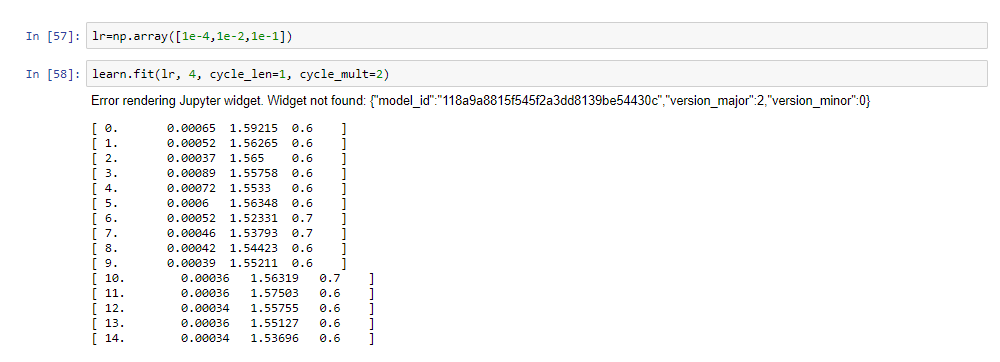
The one image incorrectly classified is shown below. It was possible to get 100% accuracy once in a blue moon, by running the model several times and varying hyperparameters. I’m not sure if 100% accuracy means much though since the number of test images is so low. Going ahead I’d like to try this with a larger number of valid images to see how the model generalizes.
Suggestions/corrections/other ideas are welcome. Some future directions I can think of are
Automate downloading of images, so that one can build better and more custom classifiers using the lesson1 template. PS: figure out how to deal with image copyright issues?
Identify techniques/practices that work better for small datasets. Apply them to domains where collecting data is hard/expensive (bio-medical images, industrial settings)
Try out some fun examples: Ship vs Submarine? Is the human wearing glasses or not?
This is very cool! I do think that data augmentation should help here. Have you tried data augmentation without unfreezing? If so, and it’s not helping, I’d be interested to see an example of that in your notebook.
I think this would make for an awesome blog post, BTW…
@jeremy I did notice that data augmentation without unfreezing performed better on average, compared to with unfreezing. I think I got 100% accuracy in one run, but it was not as frequent. I’ll try this with more epochs/ lr values.
I did read up on small datasets and I wanted to explore all the affine transforms in the fastai lib, hope to get to it. Thanks, I’ll get to making this a blog
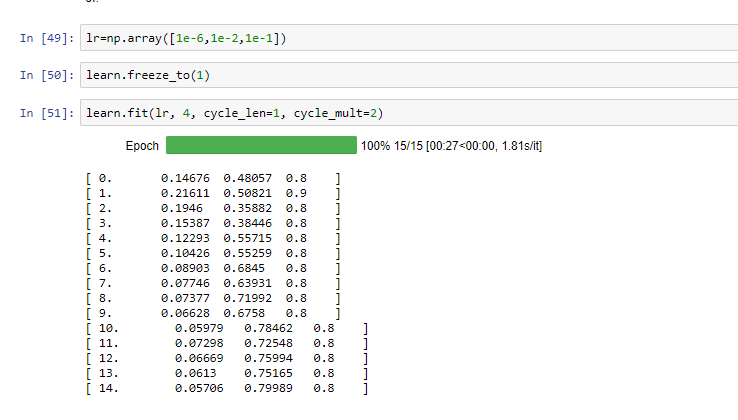
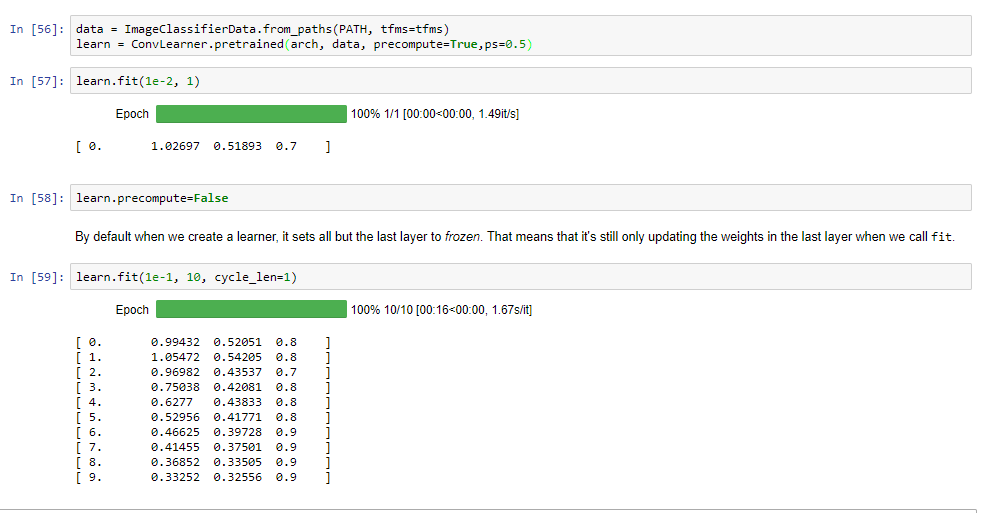
You could also try learn.freeze_to(1), and lrs=[1e-6,1e-4,1e-1] (or similar). i.e. try leaving just the first layer group frozen, and use a really small learning rate for the 2nd layer group. Also, you could try changing dropout rate by passing ps=0.5 (or something higher) to the learn constructor. We’ll be learning about that in the next week or two.
When I used dropout and learn.freeze_to(1) , I noticed that lowering the learning rate [last layer back to 1e-2] got better accuracy. I’m trying to figure out why, since I’ve read elsewhere that dropout usually uses higher learning rates?
Note that the default is not “no dropout”, but is 0.25 for first FC layer, and 0.5 for second layer. By setting ps=0.5 you’re using 0.5 for both FC layers.
Good stuff. I didn’t see this post before trying the same image groups myself, baseball and cricket bats. I work in sports, and thought it would be an interesting idea. I got the same initial results as you did. I am going to play around with some of the ideas jeremy and others commented on. Still a bit in shock that I was able to do this; it was a struggle to learn the basics but after a couple of repetitions, it feels normal. It’s a testament to how great the learning method in the course is!