So I tried classifying beaches and mountains with a very small dataset (on the lines of what Nikhil B did here Cricket or baseball? Lesson 1 with small datasets)
-
I used https://github.com/hardikvasa/google-images-download to download 40 images each of Beaches and Mountains. Used about 30% images of these for the validation set.
-
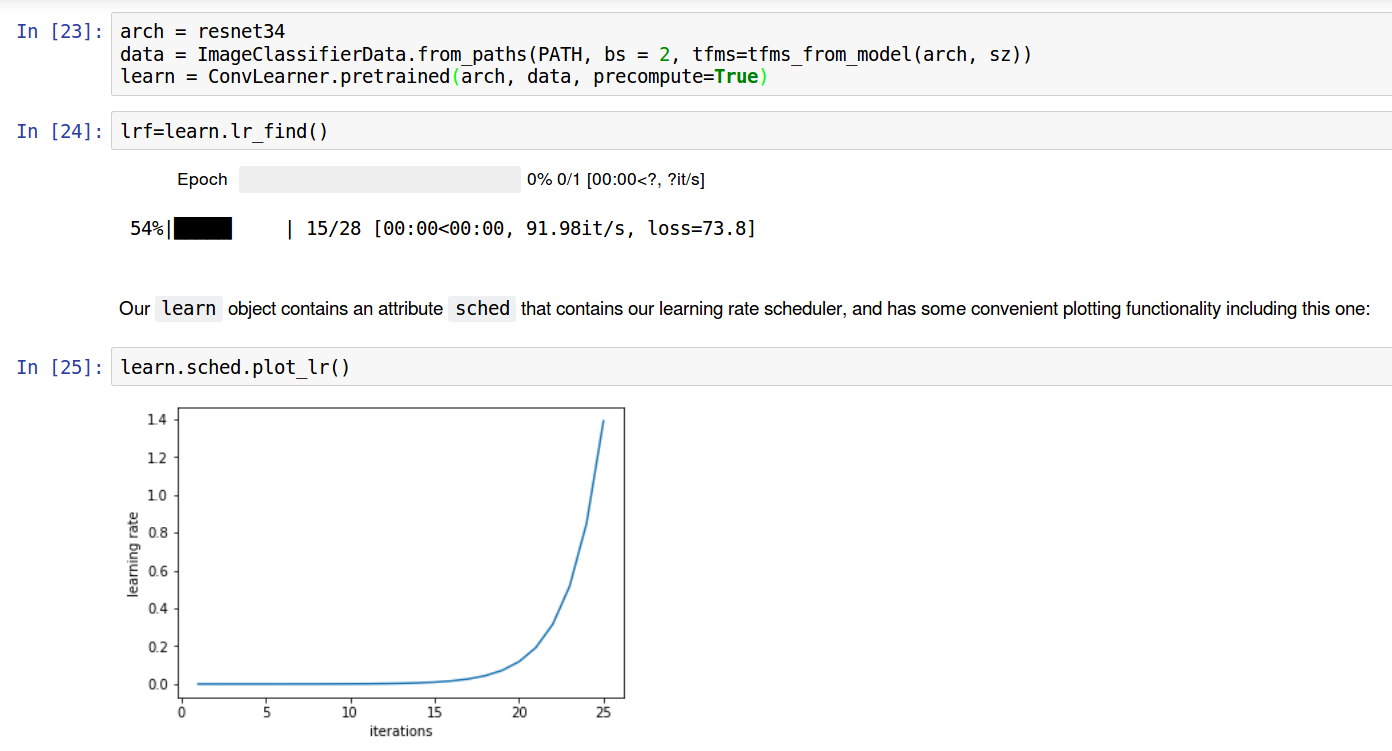
Tried using LR finder with a reduced batch size (of 2) to find optimal learning rate, but since the number of images is very less, didn’t get decent plot. So with hit and trial, settled on 0.01 as the learning rate.
-
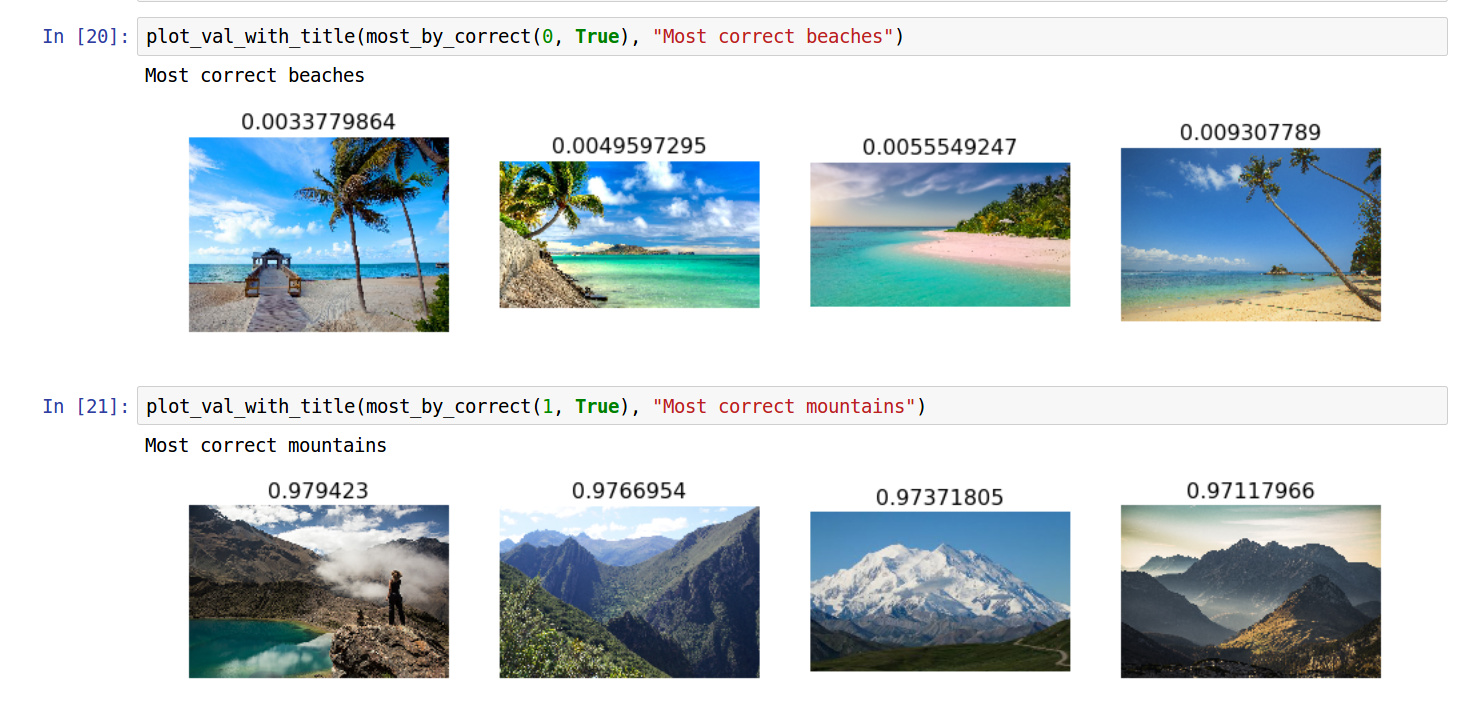
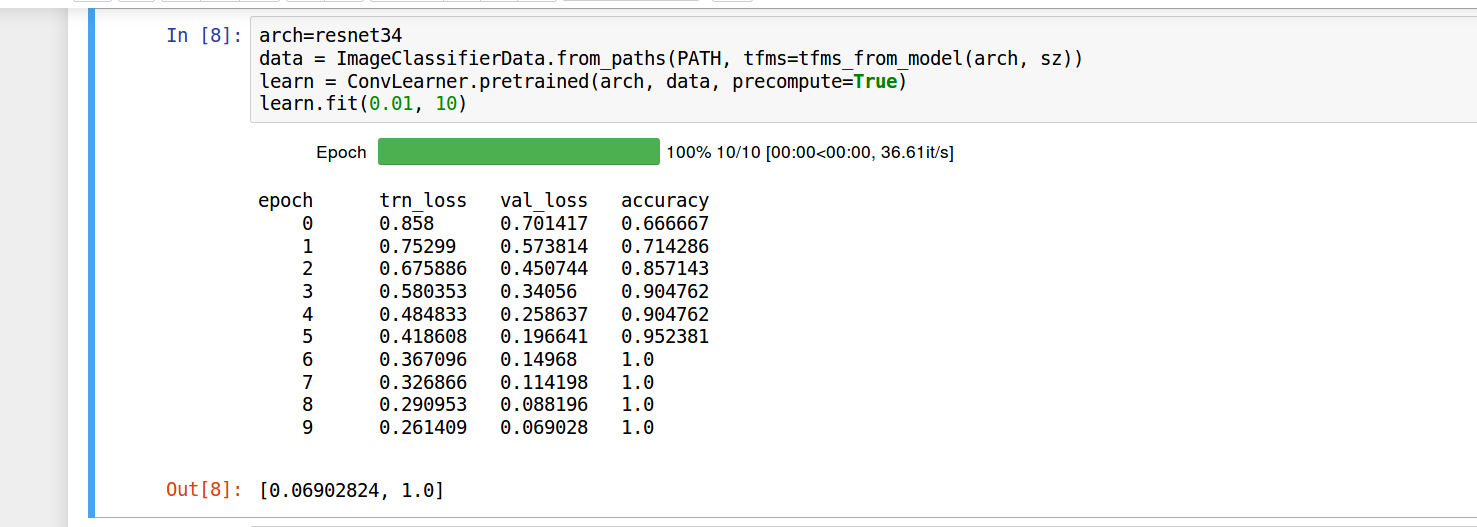
I got 100% accuracy pretty quick. Probably because the first 40 images of either category downloaded from Google Search are pretty recognizable, and binary classification in such a scenario would not be too difficult.
-
One thing I could not understand was that the training loss was higher than the validation loss. However both of them kept decreasing even after a number of epochs (after 100% accuracy), indicating that the model was becoming surer of its predictions.
-
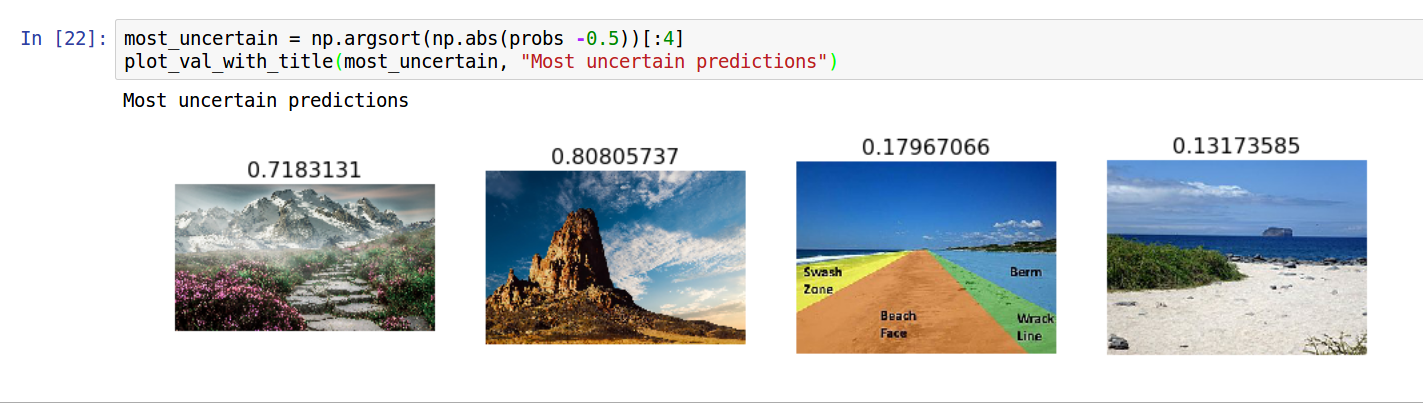
Most uncertain predictions too are separated enough.
-
Data Augmentation and Differential Learning Rates after unfreezing the model did not have significant impact here.