Thanks Jeremy.
I’m getting a weird error.
from fastai.text.all import * # import the text library from fastai
dls = TextDataLoaders.from_folder( # creates a text data loader with labels coming from folder names
untar_data(URLs.IMDB), # download and decompress the imdb dataset; load into the dataloader
valid='test', # create the validation set from the 'test' folder
bs=32 # because we're getting CUDA out of memory errors, we set the batch size to 32
)
learn = text_classifier_learner( # create a text classification learner
dls, # use the dataloader specified one cell up
AWD_LSTM, # use a AWD_LTSM pre-trained model
drop_mult = 0.5, # drop_mult is a global multiplier applied to control all dropouts
metrics = accuracy # use accuracy for the metric
)
learn.fine_tune(4, 1e-2) # train the model over four epochs with a learning rate of .01)
When running this, I get an error saying the generator is empty. No validation metrics are created. What typo did I make to cause this? I’m going nuts trying to find it.
Sounds like some issue with dataloaders etc. It would be much easier to help if you also posted the error trace. Hard to guess otherwise.
Here’s some tips to help you get the help you need:
2 Likes
Sorry, @jeremy, I’ll follow these guidelines better in future.
JEREMY - sorry I tagged you in this accidentally. I didn’t mean to reply to your comment, but rather to suvash’s reply.
So, here’s where I’m at. I’m running the notebooks through Paperspace on the basic, free GPU. I can’t run the NLP example from the book as described because I get a CUDA out of memory error. I dropped the batch size down to both 32 and 16, and run into the same error shown below (along with my code). The only thing I’ve modified from the book is the batch size.
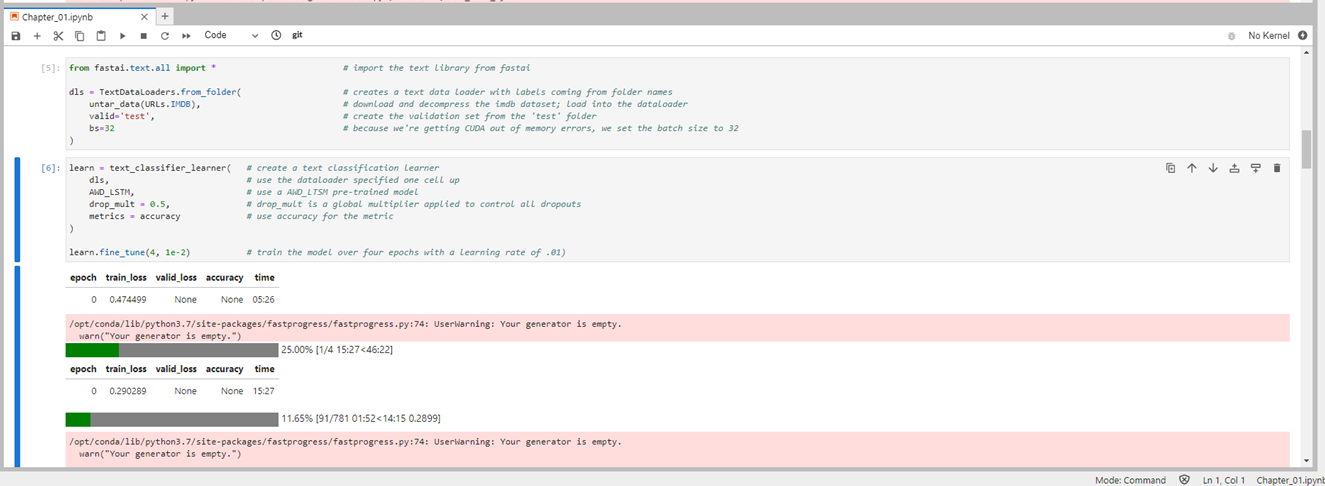
I’ve tried restarting the kernal, retyping the code, even running the code directly from the fastbook chapter 1 notebook, all to no avail. I would try it on a 16GB card but am trying to avoid the monthly charge for a Pro membership if I can avoid it. Any thoughts/hints would be greatly appreciated. If there’s more information I can include, please let me know!
Hi @knesgood , you can check to see if you’re running out of GPU Video RAM by using nvidia-smi command in a terminal on your Paperspace instance. I have a slow 1070ti with 8GB of RAM and it is able to run this example with bs=16 (anything more and it’ll run out of memory.)
In your message you say " I get a CUDA out of memory error" but the screenshot you posted has something about a generator.
I also run a paperspace image (on my local machine via Docker) and haven’t had any of these issues. You may also want to start a new instance of a paperspace machine and see if that works?
This code is simple enough that you can pop it into (with all the requisite imports of course) Kaggle or Colab and see if it works or fails there. My wild guess is that somehow, some of your imported libs might be out of date or something.
I’m myself a beginner and what I’ve learned from various forums (not necessarily Fastai forums) is that if I don’t include all the relevant info, people will ignore my requests for help because everyone has just so much time and then they move on. So, reading Jeremy’s post about how to ask questions really helped me.
I would include things like (library versions, link to a notebook (or a gist)) etc as well so anyone who has the time to help would have as much information as possible to go on.
HTH and good luck!
1 Like
The error in your screenshot isn’t a GPU memory error. This looks like an error where there may be a problem with your PATH or, more likely, the download of your training data. Can you try making sure the data has downloaded correctly and that your files all have correct extensions?
I also noticed two issues in your screenshot. (1) you don’t have an active kernel running. (2) you seem to have only executed the prior 5 cells. If this is in the ‘clean’ notebook, you might bump into some problems if you haven’t run all the setup cells at the top of the notebook.
FWIW, I spent some time trying to recreate your error on my local GPU box equipped with a moderate RTX2080 Ti FE as well as on Paperspace. On Paperspace I ran the Chapter 1 notebooks “as is” on a free P5000 GPU with and without Jeremy’s suggested modifications. As I write, it’s happily ticking away as follows:
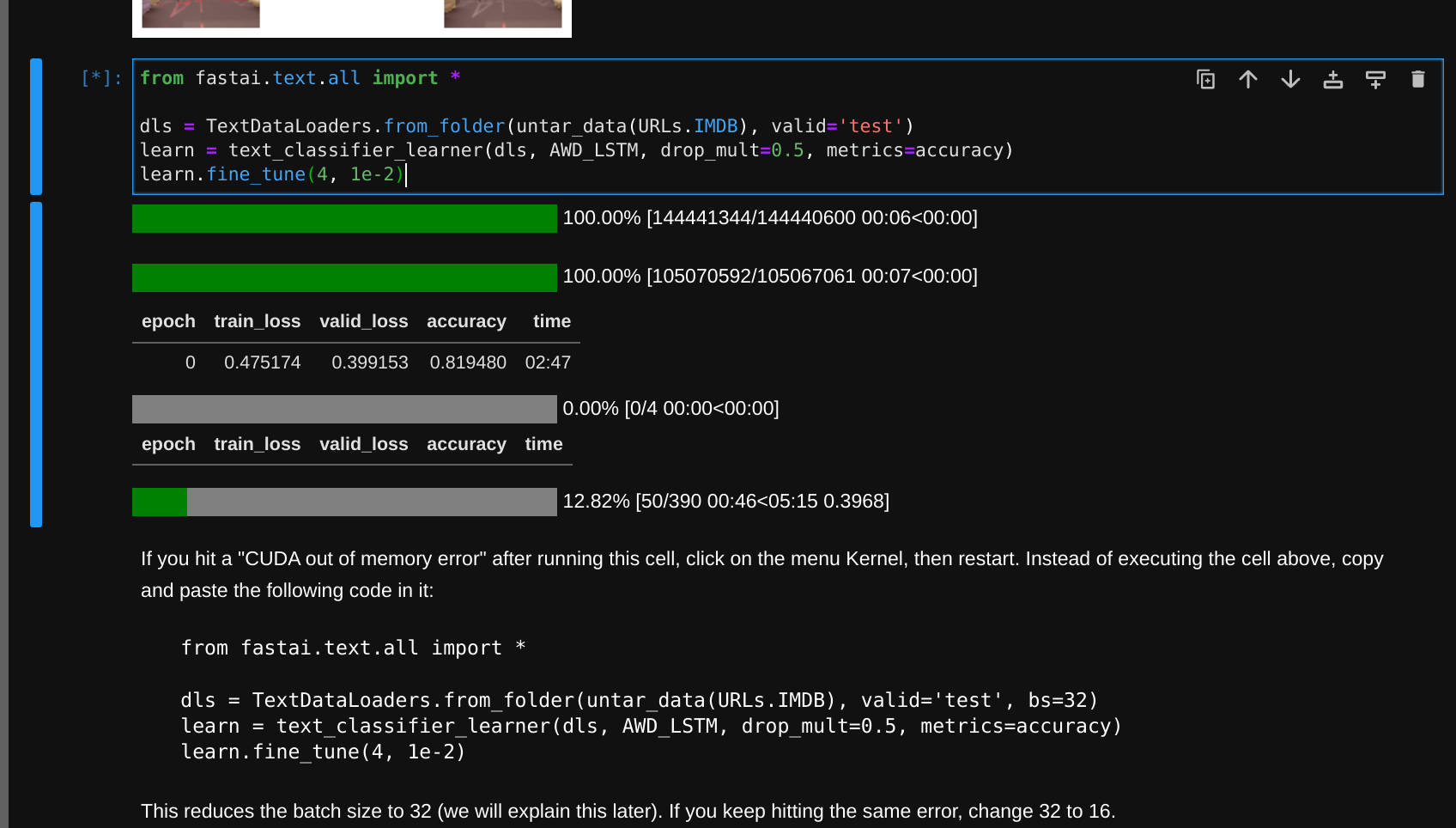
I haven’t run into your error yet (albeit with only a minimal amount of detail from your post). So, in the first instance, please try checking your data has downloaded correctly. Then try using a free P5000 GPU type on Paperspace and running the notebook from scratch using the “Run All Cells” under the “Run” menu bar item; this will at least ensure the notebook is correctly initialised.
Let me know how you get on!
1 Like
Thank you both! I’m still getting into the swing of things and will keep trying. Thanks for your patience with my post - you’re all teaching me what to include (especially Jeremy). I’ll come back after I’ve monkeyed around with it for a while.
1 Like
No need to apologise - just trying to help you get help! ![]()
4 Likes
I figured it out. Somehow the initial download of the dataset didn’t have the test folder. I deleted both the imdb and imdb_tok folders and re-ran the script. No errors. Lesson learned - check your downloads. ![]()
4 Likes
Hi there,
I’m using the first lesson to see if I can train AI to differentiate between a sardine and codfish, all runs perfect on the Jupiter notebook, but once I create a standalone python file, I get this error:
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/pjfonseca/python/is_sardine.py", line 39, in <module>
resize_images(path/o, max_size=400, dest=path/o)
File "/home/pjfonseca/.local/lib/python3.10/site-packages/fastai/vision/utils.py", line 105, in resize_images
parallel(resize_image, files, src=path, n_workers=max_workers, max_size=max_size, dest=dest, n_channels=n_channels, ext=ext,
File "/home/pjfonseca/.local/lib/python3.10/site-packages/fastcore/parallel.py", line 110, in parallel
return L(r)
File "/home/pjfonseca/.local/lib/python3.10/site-packages/fastcore/foundation.py", line 97, in __call__
return super().__call__(x, *args, **kwargs)
File "/home/pjfonseca/.local/lib/python3.10/site-packages/fastcore/foundation.py", line 105, in __init__
items = listify(items, *rest, use_list=use_list, match=match)
File "/home/pjfonseca/.local/lib/python3.10/site-packages/fastcore/basics.py", line 61, in listify
elif is_iter(o): res = list(o)
File "/usr/lib64/python3.10/concurrent/futures/process.py", line 570, in _chain_from_iterable_of_lists
for element in iterable:
File "/usr/lib64/python3.10/concurrent/futures/_base.py", line 609, in result_iterator
yield fs.pop().result()
File "/usr/lib64/python3.10/concurrent/futures/_base.py", line 439, in result
return self.__get_result()
File "/usr/lib64/python3.10/concurrent/futures/_base.py", line 391, in __get_result
raise self._exception
shutil.SameFileError: Path('sardine_or_not/sardines/104deea5-c161-4d02-803a-2f0e8b2e4a4a.jpg') and Path('sardine_or_not/sardines/104deea5-c161-4d02-803a-2f0e8b2e4a4a.jpg') are the same file
Since I’m not a python expert but do have some coding skills, it seems to me that the resized file should have a different naming to avoid conflicts? What am I doing wrong? Sorry if this is a dumb question.
Loved the first lesson and jumping into lesson 2 in a few.
1 Like
It looks like the exception is thrown by shutil and is complaining something about same file.
@PJFonseca welcome to the fastai community ![]() . Can you provide the code, so we too can try reproducing the same issue?
. Can you provide the code, so we too can try reproducing the same issue?
1 Like
I’m facing the same issue - Same File Path Error while Resizing images - lesson 1 (I didn’t find this question is previously asked, hence just created the question on the forum ).
1 Like
Sure, here you have it
from fastcore.all import *
from fastai.vision.all import *
from fastdownload import download_url
import time
def search_images(term, max_images=200):
url = 'https://duckduckgo.com/'
res = urlread(url,data={'q':term})
searchObj = re.search(r'vqd=([\d-]+)\&', res)
requestUrl = url + 'i.js'
params = dict(l='us-en', o='json', q=term, vqd=searchObj.group(1), f=',,,', p='1', v7exp='a')
urls,data = set(),{'next':1}
while len(urls)<max_images and 'next' in data:
data = urljson(requestUrl,data=params)
urls.update(L(data['results']).itemgot('image'))
requestUrl = url + data['next']
time.sleep(0.2)
return L(urls)[:max_images]
urls = search_images('photos of sardines', max_images=1)
urls[0]
dest = 'sardines.jpg'
download_url(urls[0], dest, show_progress=False)
im = Image.open(dest)
im.to_thumb(256,256)
download_url(search_images('photos of cod fish', max_images=1)[0], 'codfish.jpg', show_progress=False)
Image.open('codfish.jpg').to_thumb(256,256)
searches = 'codfish','sardines'
path = Path('sardine_or_not')
for o in searches:
dest = (path/o)
dest.mkdir(exist_ok=True, parents=True)
download_images(dest, urls=search_images(f'photos of {o}'))
resize_images(path/o, max_size=400, dest=path/o)
failed = verify_images(get_image_files(path))
failed.map(Path.unlink)
len(failed)
dls = DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=42),
get_y=parent_label,
item_tfms=[Resize(100, method='squish')]
).dataloaders(path)
dls.show_batch(max_n=6)
learn = vision_learner(dls, resnet18, metrics=error_rate)
learn.fine_tune(3)
is_sardine,_,probs = learn.predict(PILImage.create('codfish.jpg'))
print(f"This is a: {is_sardine}.")
print(f"Probability it's a sardine: {probs[0]:.4f}")
1 Like
Try deleting all subfolders under /sardine_or_not and see if you can run the code again
edit: you actually don’t need to run the following code in this cell again
searches = 'forest','bird'
path = Path('bird_or_not')
for o in searches:
dest = (path/o)
dest.mkdir(exist_ok=True, parents=True)
download_images(dest, urls=search_images(f'{o} photo'))
resize_images(path/o, max_size=400, dest=path/o)
since all the images had been already downloaded the previous time you ran the code. So if you run it twice there will be an error message.
But if you really want to run this cell and repeat the download process again for some reason, you may need to delete those previously downloaded images manually or by adding shutil.rmtree which will remove all files and folder at /bird_or_not
searches = 'forest','bird'
path = Path('bird_or_not')
import shutil
shutil.rmtree(path)
for o in searches:
dest = (path/o)
dest.mkdir(exist_ok=True, parents=True)
download_images(dest, urls=search_images(f'{o} photo'))
resize_images(path/o, max_size=400, dest=path/o)
Try and see if it works.
3 Likes
Looking at your code it looks like the way you have used resize_images method looks kind of wrong to me, as you are resizing to same folder. In Jeremy’s notebook in Paddy competition, I have seen him resizing like the below code:
trn_path = Path('sml')
resize_images(path/'train_images', dest=trn_path, max_size=256, recurse=True)
I have tweaked the code similarly and it’s running as expected when I tried running it as a python script.
from fastcore.all import *
from fastai.vision.all import *
from fastdownload import download_url
import time
def search_images(term, max_images=200):
url = "https://duckduckgo.com/"
res = urlread(url, data={"q": term})
searchObj = re.search(r"vqd=([\d-]+)\&", res)
requestUrl = url + "i.js"
params = dict(
l="us-en", o="json", q=term, vqd=searchObj.group(1), f=",,,", p="1", v7exp="a"
)
urls, data = set(), {"next": 1}
while len(urls) < max_images and "next" in data:
data = urljson(requestUrl, data=params)
urls.update(L(data["results"]).itemgot("image"))
requestUrl = url + data["next"]
time.sleep(0.2)
return L(urls)[:max_images]
urls = search_images("photos of sardines", max_images=1)
urls[0]
dest = "sardines.jpg"
download_url(urls[0], dest, show_progress=False)
im = Image.open(dest)
im.to_thumb(256, 256)
download_url(
search_images("photos of cod fish", max_images=1)[0],
"codfish.jpg",
show_progress=False,
)
searches = "codfish", "sardines"
path = Path("sardine_or_not")
resize_path = Path("resized")
# print searches
for o in searches:
dest = path / o
dest.mkdir(exist_ok=True, parents=True)
download_images(dest, urls=search_images(f"photos of {o}"))
resize_images(path / o, max_size=400, dest=resize_path / o)
failed = verify_images(get_image_files(path))
failed.map(Path.unlink)
len(failed)
dls = DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=42),
get_y=parent_label,
item_tfms=[Resize(100, method="squish")],
).dataloaders(path)
dls.show_batch(max_n=6)
learn = vision_learner(dls, resnet18, metrics=error_rate)
learn.fine_tune(1)
2 Likes
Looking into Is it a bird? Creating a model from your own data | Kaggle and comparing, “your” version is better understable and I can see why the error.
Thank you so much for the help, not knowing python makes me do this dumb questions, sorry.
2 Likes
There is no dumb questions ![]() .
.
5 Likes