Please don’t apologise - there are no dumb questions! Thank you very much for asking ![]()
6 Likes
I was following up with the lesson 1 notebook, and trying to use a different dataset.
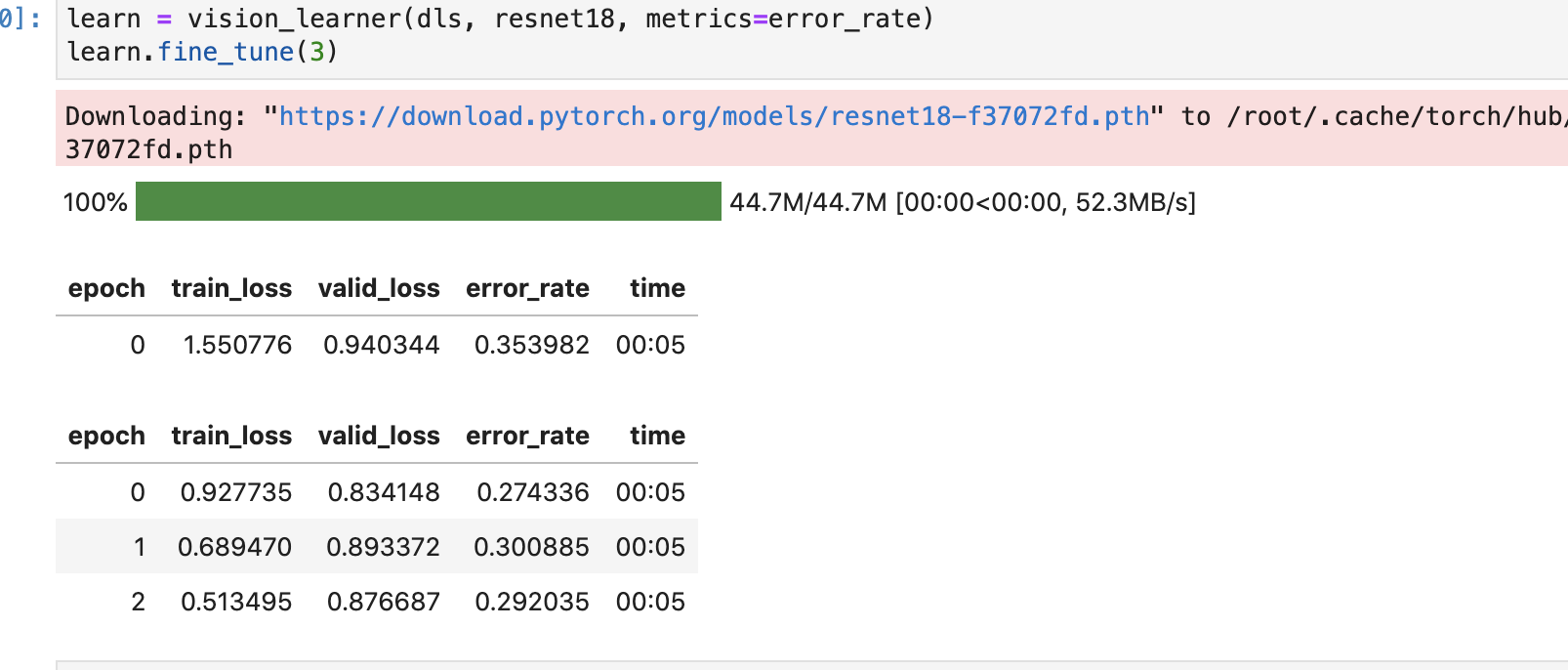
I was curious and had a couple of questions :
- The valid_loss is currently 0.8* (* signifies followed by any digits) in the model that I trained, in lesson 1 official notebooks, i saw that the valid_loss is (0.02*) after 3 epochs. The difference between both the losses seem noteworthy. Does it imply that my dataset isn’t quite good for model to train yet ? I used the exact same commands present in the lesson 1 notebook (just modified the dataset)
- I see that the loss increases at 2nd epoch, and then decreases in the 3rd epoch. Shouldn’t the loss be ideally unidirectional (i.e., decreasing after each epoch). What does this imply ?
I’m new to Deep Learning, and so pls excuse if my questions are too basic
1 Like
I just cloned this Kaggle notebook to my account but when I try to run the second cell in it (the one that installs the fastai package) I get the following error:
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
tensorflow-io 0.21.0 requires tensorflow-io-gcs-filesystem==0.21.0, which is not installed.
explainable-ai-sdk 1.3.2 requires xai-image-widget, which is not installed.
tensorflow 2.6.2 requires numpy~=1.19.2, but you have numpy 1.20.3 which is incompatible.
tensorflow 2.6.2 requires six~=1.15.0, but you have six 1.16.0 which is incompatible.
tensorflow 2.6.2 requires typing-extensions~=3.7.4, but you have typing-extensions 3.10.0.2 which is incompatible.
tensorflow 2.6.2 requires wrapt~=1.12.1, but you have wrapt 1.13.3 which is incompatible.
tensorflow-transform 1.5.0 requires absl-py<0.13,>=0.9, but you have absl-py 0.15.0 which is incompatible.
tensorflow-transform 1.5.0 requires numpy<1.20,>=1.16, but you have numpy 1.20.3 which is incompatible.
tensorflow-transform 1.5.0 requires pyarrow<6,>=1, but you have pyarrow 6.0.1 which is incompatible.
tensorflow-transform 1.5.0 requires tensorflow!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,<2.8,>=1.15.2, but you have tensorflow 2.6.2 which is incompatible.
tensorflow-serving-api 2.7.0 requires tensorflow<3,>=2.7.0, but you have tensorflow 2.6.2 which is incompatible.
flake8 4.0.1 requires importlib-metadata<4.3; python_version < "3.8", but you have importlib-metadata 4.11.3 which is incompatible.
apache-beam 2.34.0 requires dill<0.3.2,>=0.3.1.1, but you have dill 0.3.4 which is incompatible.
apache-beam 2.34.0 requires httplib2<0.20.0,>=0.8, but you have httplib2 0.20.2 which is incompatible.
apache-beam 2.34.0 requires pyarrow<6.0.0,>=0.15.1, but you have pyarrow 6.0.1 which is incompatible.
aioitertools 0.10.0 requires typing_extensions>=4.0; python_version < "3.10", but you have typing-extensions 3.10.0.2 which is incompatible.
aiobotocore 2.1.2 requires botocore<1.23.25,>=1.23.24, but you have botocore 1.24.20 which is incompatible.
3 Likes
You can safely ignore this error and proceed further ![]() Reference :- Is it a bird? Creating a model from your own data | Kaggle
Reference :- Is it a bird? Creating a model from your own data | Kaggle
7 Likes
Thanks! I was able to reproduce the results. However, when I tried to replace ‘bird’, ‘forest’ with ‘tiger’, ‘lion’, it doesn’t seem to work completely. For example, it correctly guesses the category but the probability is 0.0000. I’m guessing it might be related to the float formatting or rounding (the initial value is 5.174458692636108e-07) Does someone know what is wrong with it? Here’s my notebook: https://www.kaggle.com/code/knivetes/is-it-a-bird-creating-a-model-from-your-own-data
1 Like
I’m not able to view your notebook (Error 404), I think I might not have permissions to view. But if I understand correctly, The learn.predict() returns 1) the label(or category), 2) index to look from the probability tensor, 3) probabilities for all category (as a tensor) .

For E.g., in the above screenshot, the learner predicted that the person is ‘sad’ based on the 2nd index (or the 3rd position) from the probability tensor. Hope that helps!
I just set the access to public, can you see it now?
Perhaps it’s because the order of the categories in searches doesn’t matter, because they will be sorted alphabetically under the hood so the probability array will match the alphabetical order
2 Likes
doesn’t seem like there is a problem there, the model is very confident about its prediction at probability 0.000000517.
I suspect the tiger stripes help the model to be confident.
No I just didn’t know that the second value returned from the model is the index into probabilities array. It works fine now
2 Likes
I’ve just finished the course run through USQ, so not an expert, but may be able to provide some minor insight…
Some pre-trained networks may be better suited than others to match your dataset. You can see Jeremy uses two different pre-trained nets here…
Also, perhaps your dataset images are “more similar” that the ones used in the Lesson 1 notebook, so it takes longer to train. Although the default learning rate is generally good, and Jeremy says he doesn’t personally use lr_find() much any more, it may be a useful experience to play with lr_find().
In any case, at this stage of your DL journey, don’t worry so much about the absolute accuracy, but learning the techniques that will improve it. i.e. you could be more accurate simply using a “larger” pre-trained net, but not learn much yourself from doing just that. So wait until you get to the end of the course and maybe you can get the same dataset down to 0.05 error rate, and go back to the start to evaluate starting with different pre-trained networks.
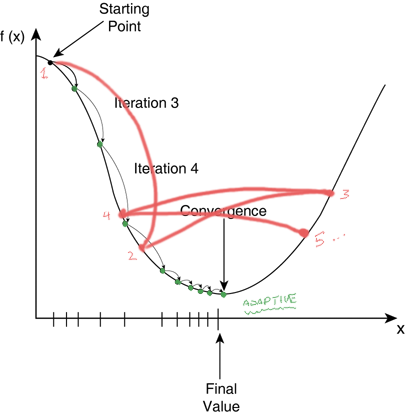
Pay less attention to valid_loss, which is is for internal use by the algorithm,
and more to error_rate, which is for human consumption.
Don’t worry if there is a bit of early or occasional rise in either. That is maybe just bouncing across either side of the “optimisation valley”. See below the error at point 3 is more than point 2…
2 Likes
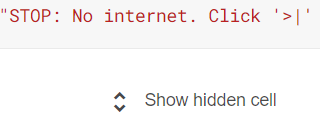
If you go to that link (i.e. the original notebook) and click on “Show hidden cell” you will see the same error. You can ignore it.
.
1 Like
Hello!
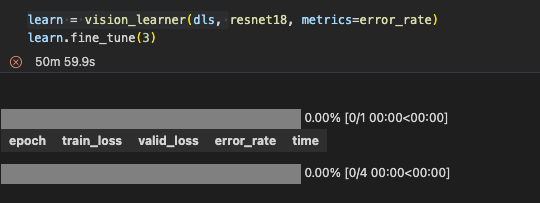
I’m having an issue whenever I try to fine-tune my model. I had it running for over 50 minutes, but it still said 0% progress done.
By the way, the error is due to a keyboard interruption, not to any part of the code itself
3 Likes
Welcome Swaraag,
I’d love to help but that presents only a pinhole view of issue.
To help characterise the problem further, can you share:
- Which service / environment you are working in. Have you tried several different ones?
- The web searches you’ve done, and what you found and tried, and results.
- A link to a notebook showing the whole of the code.
1 Like
Sorry about that.
-
I’m using Visual Studio Code. I haven’t tried another one, but I know that some time ago, in a different project, fast ai was running properly instead VSC. But I’m not sure if it’s service-based.
-
I’ve looked at the documentation. And I’ve also tried different dataloaders (normal DataBlock, and ImageDataLoader) to see if that would fix anything. It’s not specifically the ‘fine_tune’ line. I’m also having the same issue when running learn.lr_find()
-
Is there a way to share the notebook when it’s from VSC? When trying to upload here, it doesn’t allow me to drop the ipynb file.
Thanks!
1 Like
Is there a way to share the notebook when it’s from VSC? When trying to upload here, it doesn’t allow me to drop the ipynb file
I usually use https://gist.github.com/ to share errors or things to debug.
To upload a jupyter notebook in gist.github.com:
- Drag and drop your notebook file
- Name the gist filename with filextension
.ipynb
3 Likes
Cool, thanks!
Btw, update: It seems to be working in Google Colaboratory. Or at least, the green bar is actually moving. I’m currently running the lr_find line, and although very slowly, it’s running there.
I do wonder though, why it doesn’t work on Visual Studio Code. Is there a certain setting I changed? Or something else?
1 Like
Here is the Gist
Are you running it locally? Make sure your notebooks are using the GPU, this sounds like you’re running against the CPU only.
2 Likes