def fine_tune(self:Learner, epochs, base_lr=2e-3, freeze_epochs=1, lr_mult=100,
pct_start=0.3, div=5.0, **kwargs):
"Fine tune with `Learner.freeze` for `freeze_epochs`, then with `Learner.unfreeze` for `epochs`, using discriminative LR."
self.freeze()
self.fit_one_cycle(freeze_epochs, slice(base_lr), pct_start=0.99, **kwargs)
base_lr /= 2
self.unfreeze()
self.fit_one_cycle(epochs, slice(base_lr/lr_mult, base_lr), pct_start=pct_start, div=div, **kwargs)
You can see it runs fit_one_cycle() twice, the first time frozen, defaulting 1-time, and the second time unfrozen, requiring you to specify the number-of-times.
Freeze locks all weights except the last layer, which you just replaced with your categories.
[Side note: Jeremy requests he not be @notified unless something is wrong with the server - otherwise imagine the stream of notifications interupting him from the many people doing this popular course.]
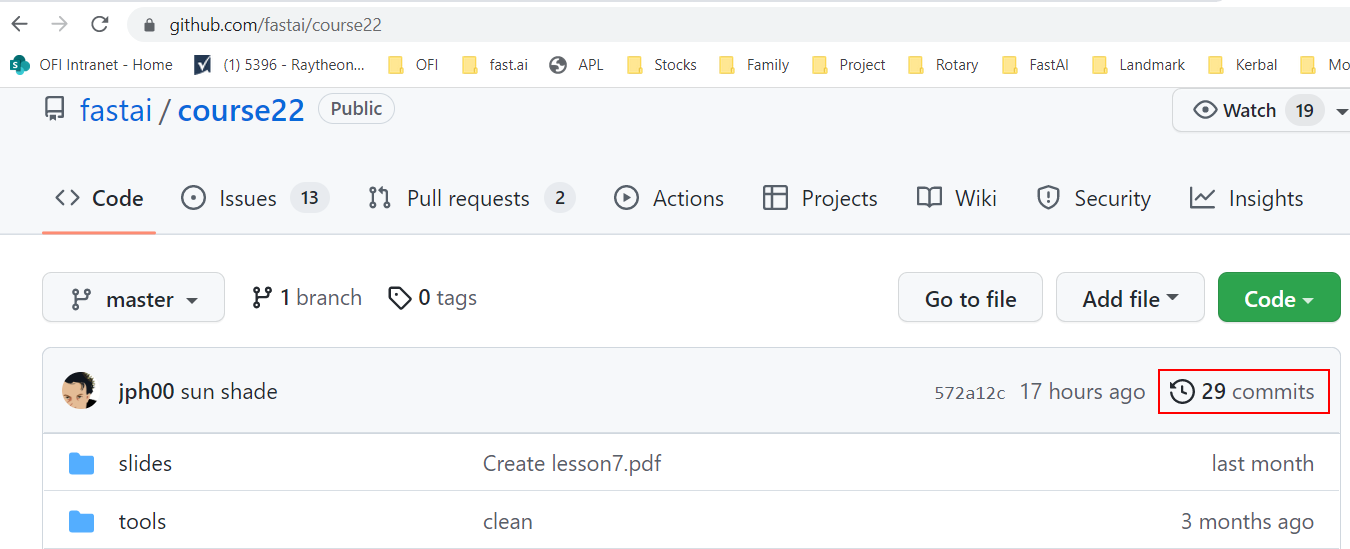
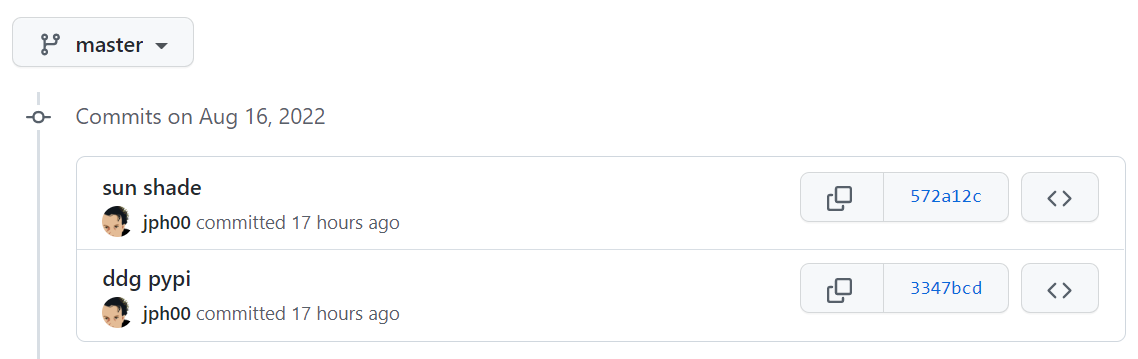
I also was curious also what the code change was, so I went looking to answer this myself, using Github’s facility to show recent commits - from a repo, click Insights > Networks as shown below.
I had to check a few fastai repos, and then in “course22” I found two recent commits shown below boxed in red under the number 16…
Hey everyone, I have trained my model in fastai using the MIDOG 2021 dataset, and my object detection model is working great, I have a minor issue while inferencing the model on totally new two images which are aperio images of .scn format and having aperio imagescope created annotation in XML format.
The thing is I trained my model using the fastai input pipeline based on the tutorial notebook provided by the MIDOG challenge team on their website: Google Colab
The notebook is based on the object detection library of fastai by Christian marshal: GitHub - ChristianMarzahl/ObjectDetection: Some experiments with object detection in PyTorch
The input pipeline is as follows it takes the bunch of .tiff images and the annotations in MS COCO .json format and then creates the imagedatabunch object of fastai. Now how should I use my new data which consists of only one .scn image and the respective . XML file of the same, which has annotations in the ellipse box (top left corner and top bottom corner coordinates) to be used for inference, and testing of my trained model. Any resource, code snippet, notebook, etc which might be able to help to do this would be really helpful.
Thanking you all in advance,
Harshit
Hey everyone. I just started the fast.ai today and I am very eager to continue with all the interesting material and with a level that is general enough for us in the IT.
While watching the Lesson 1 video, Tabular Data is discussed among other, things. However, I couldn’t find something relevant in the notebook of lesson 1. Same goes for collaborative filtering. Am I missing something? What is the case with those two subjects?
@ypanagis You can find tutorials for simple implementations of tabular training and collaborative filtering on FastAI’s docs website (as well as several other tutorials ranging from beginner level to advanced):
I believe the lessons may not correspond to the notes you’re looking at exactly.
Tabular training deals with data that can be expressed in tabular format, basically excel/spreadsheets (think labeled columns, rows of data). The tutorial teaches you how to access and manipulate the data to be used in training a model.
Collaborative filtering is responsible for what you see in a recommendation system, like when netflix or youtube recommends you a show or a video, that’s utilizing collaborative filtering (and other bits and bobs). Collaborative filtering uses similarities between items (take shows, for example), and similarities between users, and uses that data to do stuff.
For example, if you really like show A, and show B is similar to show A, then the system might recommend you show B. Alternatively, if you and your friend have very similar interests, and your friend has watched show C, then the system might recommend you show C.
The collaborative filtering tutorial goes over loading a movie database, and using that database to extrapolate similarities, the backbone of any recommendation system.
@DylanWu thank you for the pointers. Yes there probably is a small discrepancy between the video and the notebook I was looking at. Fastbook, Chapter 1, does have however the material on both tabular data and collaborative filtering, and many others, so I can go with that.
Okay, but where can I find help regarding the object detection fastai library?
I tried other topics for deep learning with computer vision but those topics were active years ago, so no one ever replies there.
Please share any active forum where Computer vision problems are still discussed.
Thanks,
Harshit
Hi there! I started tracking my mouse movements and created a crude dataset on my state of mind based on my mouse scrolls - Normal/Browsing, Rest(watching Netflix or listening to Spotify), Stressed(Unable to solve some problem, can’t find what I was looking for etc).
Based on this data, I created a small classifier.
If you keep going in the course you will get to tabular examples. Otherwise you can check out the book which has a chapter on tabular data at book.fast.ai .
I have not done much with object detection myself, but you may want to check out IceVision. They support fast.ai I believe and are dedicated to object detection https://airctic.com/
If you can find a pre-trained model that was trained on the images you’re trying to segment then you can just run inference on your images and just clean up the results. AWS Ground Truth has model assisted labelling to help make the process faster, but it’s not free unless you have AWS credits and is probably non-trivial to get set up initially unless you’re pretty comfortable in AWS SageMaker. There may be other similar tools but I have not run across any personally. What types of images/classes are you trying to label?
It is probably the most stupid question ever asked about lesson 1, but in the Google Colab notebook, section “Deep Learning is for Everyone”, the cell has two left brackets followed by myths followed by two right brackets in it, which is rendered as “<>” on my computer (I tried Firefox and Chrome to the same effect), and the table, which is referred to, looks as a raw ASCII string (probably because of the asciidoc syntax.
I looked up the markdown syntax, and couldn’t find any description of this <<>> syntax (or the [[]] syntax used after the asciidox syntax for that matter…).
Obviously, this is just cosmetics, but I am trying to understand.
Note: this problem occurs elsewhere too, for instance in the Neural Networks: A Brief History section where a reference to the neuron figure below (which unfortunately doesn’t render well in dark mode) read <> when the source shows two left brackets followed by the word neuron followed by two right brackets.
Hi folks, read Ch 1 of the book and watched the first video of the course. Had a question about the fine_tune API of cnn_learner. Does the API figure out the shape of the head based on the labels of the data block? So for example if there are 5 distinct labels in the training dataset does it just appends a Linear Layer with that many output parameters and input params being the number of output of the original model that is being fine tuned?
These notebooks were made directly into the fastai book. There is some ‘odd’ looking formatting artifacts in the book notebooks that are just there to display things in a certain way in the book.