Yes, it automatically creates an appropriately sized head based on the number of classes. It’s a bit more than a single linear layer, but you’re generally on the right track.
2 Likes
I am guessing depending on the parent model that is being fine-tuned there is more than a single Linear layer being inserted. Probably should look into the source ![]()
1 Like
Annotation of PV modules in a collection of PV arrays. This enables automatic counting of a PV module installed at a particular site.
@medoab Are you trying to label orthomosaic tiles/photos that were stitched from drone photos, raw drone photos, satellite images, or something else? Is the dataset you have public? I’m actually working on something very similar! I’m using tiles from orthomosaic photo captured from a drone. I built a labeler on top of a mapping engine (ipyleaflet) to do the labeling in Jupyter notebooks. I’m hoping to eventually publish it once I clean it up. I also have a model I trained model that detects posts, torque tubes and panels on solar fields.
Labeling

Predictions

I’m just using this as an example for the labeling. The model was not trained on this particular ortho photo.
5 Likes
At the point where we from fastai.vision.all import * (here in his notebook), running that import crashes my Jupyter kernel for some reason. I noticed that it gets fixed when I move that import statement above the fastcore.all import line: from fastcore.all import *. So when it’s imported before fastcore.all, it works, but when imported after fastcore.all, it breaks.
Has anyone else encountered this or knows what’s wrong? Since I did get a work around (moving the import), it’s not a super big deal, but would be nice to know what’s going on.
Error logs if helpful (they weren’t to me):
error 14:13:11.745: Raw kernel process exited code: undefined
error 14:13:11.746: Error in waiting for cell to complete [Error: Canceled future for execute_request message before replies were done
at t.KernelShellFutureHandler.dispose (/out/extension.node.js:2:32353)
at /out/extension.node.js:2:51405
at Map.forEach (<anonymous>)
at y._clearKernelState (/out/extension.node.js:2:51390)
at y.dispose (/out/extension.node.js:2:44872)
at /out/extension.node.js:2:2320921
at t.swallowExceptions (/out/extension.node.js:7:118974)
at dispose (/out/extension.node.js:2:2320899)
at t.RawSession.dispose (/out/extension.node.js:2:2325836)
at processTicksAndRejections (node:internal/process/task_queues:96:5)]
warn 14:13:11.747: Cell completed with errors {
message: 'Canceled future for execute_request message before replies were done'
}
This did run fine in Kaggle, but when I ran it on my computer (2019 Intel Mac), that’s when I had this problem.
thanks for the reply.
I intend to use the dataset provided in this link:
Aside from creating the boundary around the whole PV array collection, I intend to make additional boundary for each PV module.
Is it a gorillaCreating a model from your own data | Kaggle
Based on learning from Lesson 1, I build a quick and easy model to distinguish between chimpanz and gorillas, as I myself constantly have trouble differentiating them. It worked pretty well with close to 100% accuracy! ![]()
1 Like
I got the dataset downloaded. Unfortunately it does not appear that these are contiguous map image tiles so I’m not sure that my labeler would work very well. If I come up with something I’ll let you know. Please keep me posted on your progress. I think this is a cool project!
So… after watching the first lesson and tinkering around with the code, I now understand what’s going on. I modified the notebook “Is it a bird?” and changed all the instances of “bird” to “parrot” and that of “forest” to “eagle”… but when I ran the code, I got completely opposite results:
is_parrot,_,probs = learn.predict(PILImage.create('parrot.jpg'))
print(f"is_parrot: {is_parrot}")
print(f"This is a: {is_parrot}.")
print(f"Probability it's an parrot: {probs[0]:.4f}")
After running the code, it gives 0.0000 probability. However, when I change all the instances of “parrot” to eagle (including the file name and therefore the picture that I want to predict), I get 0.9994.
I’m confused… How do I know which picture will give higher probability and which one will give lower probability? I was expecting higher probability because the original code gave higher prob for “bird” and I didn’t change anything else.
Also, where does it specify the number of iteration for the for loop? I think it downloads around 100 images for each thing (parrot and eagle — idk what to call them), but I don’t see any number at all. Maybe I’m missing something… Can anyone guide me please?
Thanks!
Without seeing your whole code, I will have to generalise.
Adapting this example to people’s own is a frequent question.
I was mislead by the is_parrot variable name, since its not a boolen, but rather a string matching the inference image. Is that part working correct?
If the string prediction is correct, but the probablities are reversed, try using this code instead…
prediction, prediction_index, probs = learn.predict(PILImage.create('parrot.jpg'))
print(f"This is a: {prediction}.")
print(f"Probability it's a {prediction}: {probs[prediction_index]:.4f}")
2 Likes
Thanksss ![]() It worked!
It worked!
I have a few other questions, if you don’t mind:
learn.predict(PILImage.create('eagle.jpg'))
The above line returns a tuple:
('eagle', TensorBase(0), TensorBase([9.9989e-01, 1.0755e-04]))
The first value is the name of the thing that I trained the model on, where does it get that name from? Does it get it from the name of the folder it created?
Also, why does it download more or less 100 images of each bird? The loop only iterates over two values 'eagle', 'parrot' yet it downloads so many images. Can you tell me why it does that?
Here’s the loop:
searches = 'eagle','parrot'
path = Path('parrot_or_not')
from time import sleep
for o in searches:
dest = (path/o)
dest.mkdir(exist_ok=True, parents=True)
download_images(dest, urls=search_images(f'{o} photo'))
sleep(10) # Pause between searches to avoid over-loading server
download_images(dest, urls=search_images(f'{o} flying photo'))
sleep(10)
download_images(dest, urls=search_images(f'{o} in sun photo'))
sleep(10)
resize_images(path/o, max_size=400, dest=path/o)
Also, when I turn on my laptop and come back to the code (I’m running it on my laptop and not on any of the cloud notebooks), I have to run it all over again and it downloads more images of those things. If I want to upload the code to GitHub, should I upload all the images as well?
Here’s the full code (original version as created by Jeremy with slight modifications): Is it a bird? Creating a model from your own data | Kaggle
Thanks! ![]()
1 Like
Yes. It gets the parent folder name using: get_y=parent_label
why does it download more or less 100 images of each bird?
Don’t know. It should default to downloading 1000…
The loop only iterates over two values
'eagle', 'parrot'yet it downloads so many images. Can you tell me why it does that?
The function name download_images indicates multiple.
when I turn on my laptop and come back to the code (I’m running it on my laptop and not on any of the cloud notebooks), I have to run it all over again and it downloads more images of those things.
Thats normal - that if you run it again, it does it again.
You may want to put the code that builds your dataset and does the training in separate notebooks. Or wrap the search-n-download in a condition check for the existence of the parent folder.
If I want to upload the code to GitHub, should I upload all the images as well?
Before uploading lots of photos you should consider Git Large File Storage (LFS). One of Jeremy’s live-coding walkthoughs takes you through it.
3 Likes
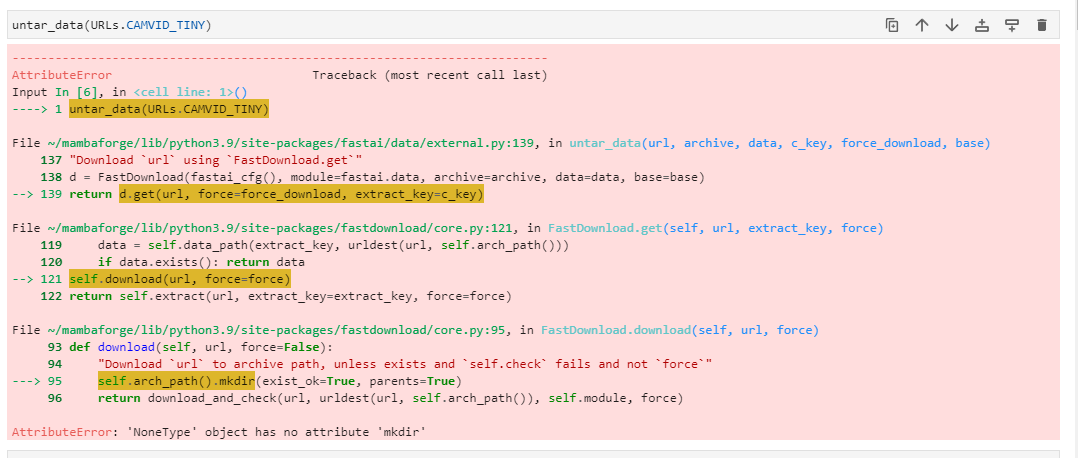
Hi. I’m using Paperspace and am having a problem with untar_data(). The error message is <‘NoneType’ object has no attribute ‘mkdir’>. Could anyone provide some help? Here is whole message:
I’m wondering the same thing. It’s confusing to confront that ascii table and the formatting around myth at the beginning of lesson 1 which is not rendered correctly (it is shown correctly in the video of lesson 1). I’ve been trying to find if you can enable asciidoc formatting in Colab, but I haven’t found anything. Any luck?
Haven’t bothered yet (I am trying to run the Jupyter Notebook on my laptop as I keep timing out on Google Colab - free tier).
when using the urls for searching and downloading images, how is this actually working? is it going to a browser and searching the images and downloading each? or am i completely wrong here?
any help would be great
just going to add this here as its similar part of the code, thanks
Hey James,
You can search using DuckDuckGo (and other search engines) without a browser. This can be done using the console (aka terminal) or directly from code.
For example, in Is it a bird? Creating a model from your own data | Kaggle in Step 1: Download images of birds and non-birds¶
we can that a python library called duckduckgo_search (I think from GitHub - deedy5/duckduckgo_search: Search for words, documents, images, videos, news, maps and text translation using the DuckDuckGo.com search engine. Downloading images to a local hard drive.) is used:
from duckduckgo_search import ddg_images
from fastcore.all import *
def search_images(term, max_images=30):
print(f"Searching for '{term}'")
return L(ddg_images(term, max_results=max_images)).itemgot('image')
With such a diverse community here, it’s hard to judge what things are obvious and what things are not. Do you mind expanding on which part is unclear?
3 Likes
Hello everybody.
i’ve been looking for some solution. I this lesson y this code block show an exception : UnsupportedOperation: fileno
it appears when i execute this code from lesson_1 notebook:
from fastai.text.all import *
dls = TextDataLoaders.from_folder(untar_data(URLs.IMDB), valid='test', bs=32)
learn = text_classifier_learner(dls, AWD_LSTM, drop_mult=0.5, metrics=accuracy)
learn.fine_tune(4, 1e-2)
Some idea how can i solve it?? Thank you in advance folks!!
It would help if you:
- Provide a public link to the whole notebook
- Isolate which line is causing the error, by separating this cell into four cells (Tip: Use CTRL SHIFT “-” ).
- Also put
imdb = untar_data(URLs.IMDB)on its own line.