Got the same problem as well. no idea how to solve this
My workaround while waiting for an explanation is to use this library, the functions closely mimic what the search_images() does
1 Like
The output of the model tuning has two sets of runs:
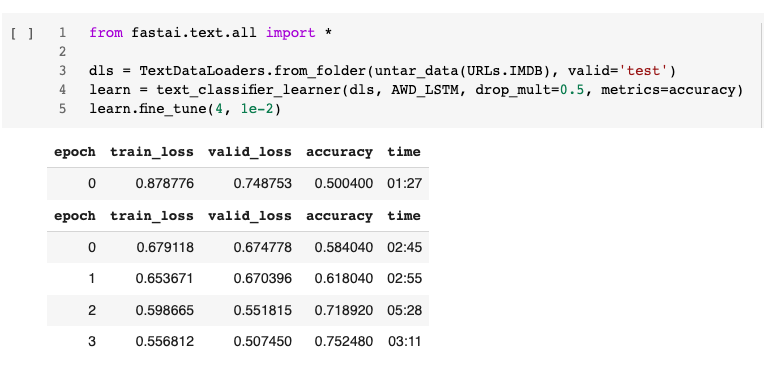
What are the 2 groups of runs for?
Is the first run (only 1 epoch) more like a sanity check to see how well the loaded model (AWD_LSTM in this case) does with just one epoch?
hey everyone! just started the fast.ai course and got a bit confused. so i watched the video recently, there was presented a model that distinguishes between birds and forests. now when i start reading the first chapter of the book, they show the cell and notebook with another model, called “cats and dogs”. and the notebook itself is called “00_intro” in the book but i have not been able to find it anywhere.
the book then continues on the first cell:
To do so, just press Shift-Enter on your keyboard, or click the Play button on the toolbar. Then wait a few minutes while the following things happen:
A dataset called the Oxford-IIIT Pet Dataset that contains 7,349 images of cats and dogs from 37 breeds will be downloaded from the fast.ai datasets collection to the GPU server you are using, and will then be extracted.
but in the model from the notebook called “Is it a bird? creating a model from your own data” there is no Oxford Pet dataset. feel a bit confused
am i correct to believe that the content of the first lesson was updated in the most recent version of the course and i can disregard the out-dated information in the first chapter of the book?
1 Like
got exactly the same issue, HTTP Error 403: Forbidden raised.
However, when I changed the url from ‘duckduckgo.com’ to ‘google.com’, i got another type of error: HTTP Error 405: Method not allowed.
and when changed from ‘google.com’ to ‘yandex.com’ (russian-based search engine) it throws another error: AttributeError: 'NoneType' object has no attribute 'group'.
2 Likes
My understanding is that the materials are basically the same thing but with a bit of a variation.
I think this might be the notebook you are looking for but it might be better to stick to the 2022 stuff?
1 Like
Continuing the discussion from Lesson 1 official topic:
Hello;
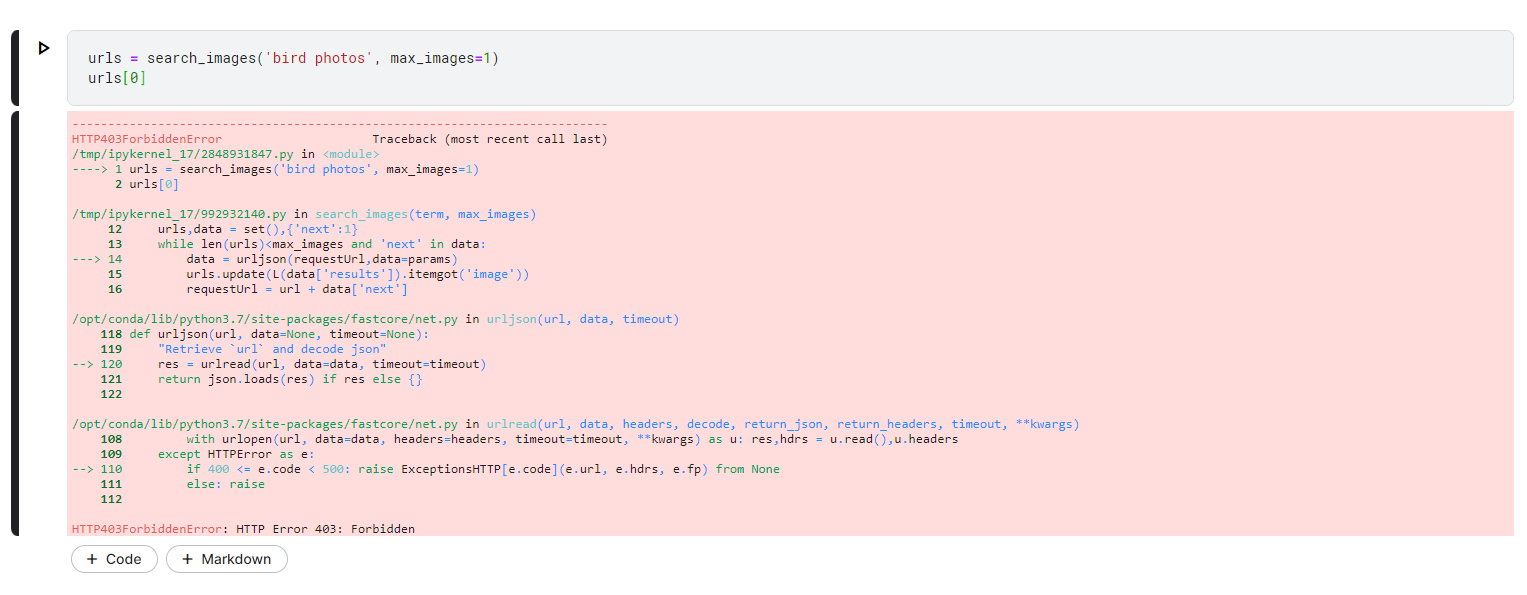
in this lesson, it seems the search_images() function doesn’t work for me, the output is:
---------------------------------------------------------------------------
HTTP403ForbiddenError Traceback (most recent call last)
<ipython-input-11-4702b8990eb9> in <module>()
----> 1 urls = search_images('bird photos', max_images=1)
2 urls[0]
2 frames
/usr/local/lib/python3.7/dist-packages/fastcore/net.py in urlread(url, data, headers, decode, return_json, return_headers, timeout, **kwargs)
113 with urlopen(url, data=data, headers=headers, timeout=timeout, **kwargs) as u: res,hdrs = u.read(),u.headers
114 except HTTPError as e:
--> 115 if 400 <= e.code < 500: raise ExceptionsHTTP[e.code](e.url, e.hdrs, e.fp) from None
116 else: raise
117
HTTP403ForbiddenError: HTTP Error 403: Forbidden
Please, does someone know about this?
Thank you
5 Likes
i agree, but 2022 stuff seems to not be reflected in the book
Hi, Is there any resolution for this? I am getting the same error. Thanks.
1 Like
I hope this is the right place to ask for help. LMK if not!
I’m trying to run the code in the 1st lecture and getting this error when trying to get 1 pic from DuckDuckGo.
Code:
urls = search_images('bird', max_images=1)
urls[0]
Error:
HTTP403ForbiddenError: HTTP Error 403: Forbidden
4 Likes
Hello lesson 1 fails at cell 5 with:
HTTP403ForbiddenError: HTTP Error 403: Forbidden
3 Likes
Is the internet enabled on your kaggle notebook?
DDG seems to be requiring a referer header. I had success changing the cell that defines search_images to the following:
from fastcore.all import *
import time
import json
def search_images(term, max_images=200):
url = 'https://duckduckgo.com/'
res = urlread(url,data={'q':term})
searchObj = re.search(r'vqd=([\d-]+)\&', res)
requestUrl = url + 'i.js'
params = dict(l='us-en', o='json', q=term, vqd=searchObj.group(1), f=',,,', p='1', v7exp='a')
headers = dict( referer='https://duckduckgo.com/' )
urls,data = set(),{'next':1}
while len(urls)<max_images and 'next' in data:
res = urlread(requestUrl, data=params, headers=headers)
data = json.loads(res) if res else {}
urls.update(L(data['results']).itemgot('image'))
requestUrl = url + data['next']
time.sleep(0.2)
return L(urls)[:max_images]
24 Likes
or look at the suggestion above…
Tnx! This seems to work.
I’ve updated the code in the repo now and DDG seems to work. (I hadn’t seen the suggestion to add a referer header above – if it breaks again we’ll try that).
2 Likes
@jeremy Hi Jeremy, The output of the model tuning always has two sets of runs. What are the 2 groups of runs for?
Is the first run (only 1 epoch) more like a sanity check to see how well the loaded model (AWD_LSTM in this case) does with just one epoch?
I understand that the 2nd group of runs are the epochs that are specified in the fine_tune() function.
Screenshot for reference: Lesson 1 official topic - #277 by replica2915
Hi @jeremy – I had got this error yesterday when I ran your notebook on Kaggle. Can you please share what the issue was and the code change that fixed it? Thanks.
I had the same question as I could not find the 00 intro notebook anywhere.