Background: I am trying to create a model that can differentiate between 11 classes, based on my current understanding, all the probabilities should sum up to 1. When I was looking out through predictions for one of my OOT image I saw this not holding true. Can someone help me out in understanding the missing piece in my learning? Thanks in advance.
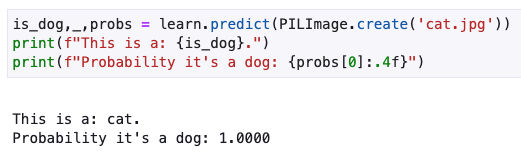
I’ve created a dog and cat classifiers, but the outputs are strange.
I changed probs[0] to probs[1] and it worked. My question is how do I know which index is associated to which animal? I respected the name order of the bird classifier, shouldn’t it be the same? Dog first, cat second.
I’m on Kaggle and I’m getting an error message right at the very start:
from fastdownload import download_url
dest = 'bird.jpg'
download_url(urls[0], dest, show_progress=False)
from fastai.vision.all import *
im = Image.open(dest)
im.to_thumb(256,256)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
/opt/conda/lib/python3.7/site-packages/IPython/core/formatters.py in __call__(self, obj)
700 type_pprinters=self.type_printers,
701 deferred_pprinters=self.deferred_printers)
--> 702 printer.pretty(obj)
703 printer.flush()
704 return stream.getvalue()
/opt/conda/lib/python3.7/site-packages/IPython/lib/pretty.py in pretty(self, obj)
392 if cls is not object \
393 and callable(cls.__dict__.get('__repr__')):
--> 394 return _repr_pprint(obj, self, cycle)
395
396 return _default_pprint(obj, self, cycle)
/opt/conda/lib/python3.7/site-packages/IPython/lib/pretty.py in _repr_pprint(obj, p, cycle)
698 """A pprint that just redirects to the normal repr function."""
699 # Find newlines and replace them with p.break_()
--> 700 output = repr(obj)
701 lines = output.splitlines()
702 with p.group():
/opt/conda/lib/python3.7/site-packages/fastai/vision/core.py in __repr__(x)
26 @patch
27 def __repr__(x:Image.Image):
---> 28 return "<%s.%s image mode=%s size=%dx%d at 0x%X>" % (x.__class__.__module__, x.__class__.__name__, x.mode, x.size[0], x.size[1])
29
30 # %% ../nbs/07_vision.core.ipynb 11
TypeError: not enough arguments for format string
@Billy, replace the underscore with variable ‘ndx’
e.g… pred,ndx,probs = learn.predict(...)
then probs[ndx] will give the probability of the prediction.
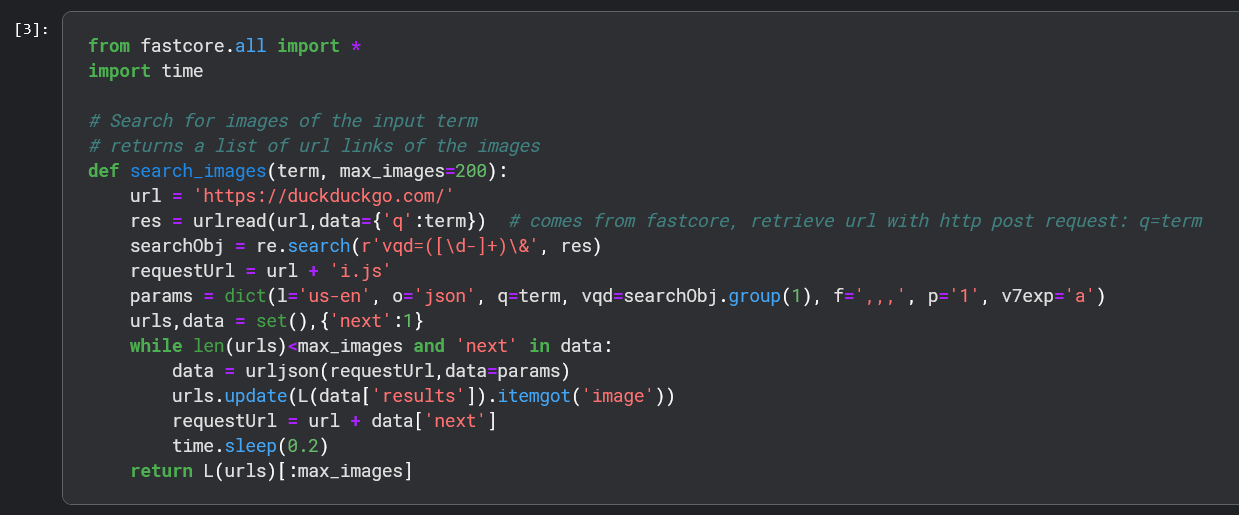
Got problem when trying to acquire a larger dataset, Keyerror: 'Next' when using search_iamges, anyone knows why?
My effort: tried different max_images parameter, and when it is less than 400 it works fine, but when larger than 1000 there is an error.
Here is the error info:
When I tried using fast setup and run./setup-conda.sh, I got curl: option --no-progress-meter: is unknown err. I searched online but seems that no answer regarding this, anyone know how to solve it?
fastsetup % ./setup-conda.sh
Downloading installer...
curl: option --no-progress-meter: is unknown
curl: try 'curl --help' or 'curl --manual' for more information
Hi, I just finished my first homework and I have two questions:
Where am I supposed to “share” it? I can’t seem to find the proper discussion.
What’s the purpose of the “probs” output from learn.predict ? I assumed it was the probabilities of the input belonging to one class, but after some testing, they seem uncorrelated (e.g. with my classifier an image is classified as “class 1” but the highest probs is for “class 3”). Any advice?
The article pasted below does a good job of explaining the output of learn.predict, I have copy and pasted the relevant part here:
“a fully decoded prediction including reversing transforms from the dataloader, a decoded prediction using decodes , and the prediction from the model passed through the loss function’s activation”
Which leads to some questions in regards to what your model is doing, is it a classification task? Can you please paste the output here?
Thank you!
For those who are facing the same problem:
I removed --no-progress-meter option
from curl -LO --no-progress-meter $DOWNLOAD in ./setup-conda.sh in fastsetup folder
and get curl -LO $DOWNLOAD instead.
Hi, first thanks for the links and the advice. I’ll post my work there when it is completed.
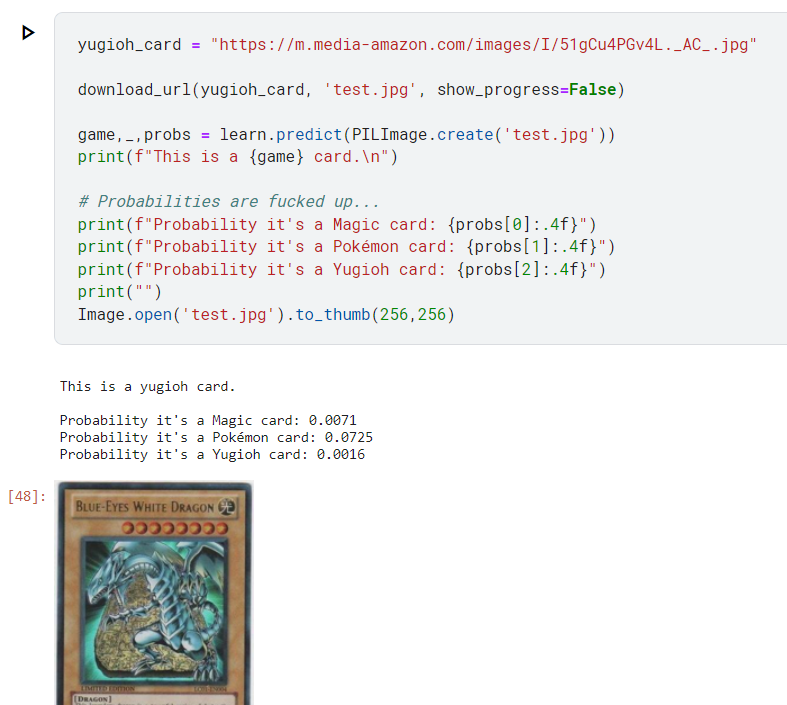
Here is a screenshot of the output. I wanted to try and distinguish between Magic, Pokémon, and Yugioh cards with a classifier. You can see that the game is correctly predicted but the biggest output is assigned to magic cards. Furthermore, I just notice that those can not be probabilities because they don’t add up to 1 but I guess the conversion is just a normalization that will preserve the order relation.
Hi @nerusskyhigh, thanks for sharing the notebook and it’s a cool idea and classification task!
I was able to decipher what the issue is. If you were to run dls.vocab on your data loader – once it’s been instantiated – you can see that there are more than three classes. So while the three classes will not add up 1.0 as expected, if you were to run probs.sum() (after the cell you’ve pasted), you will see the probabilities adding up to 1.0, as expected!
I’ll leave it up to you to determine how to figure out how to rectify the path naming issue, but I hope that this helps and it was clear enough for you to understand your question in regards to the learn.predict.
The “dls.vocab” made the trick, I thought there wasn’t any real way yo check the class found other than using the verbose option (which is not completely clear). Once I noticed the other classes I looked for other folders inside of “cards/” and worked from there. I don’t really know where they came from, but I settle things once and for all by sanitizing the cards’ names. Thanks a gain for your time. If there is a proper way to thank you other than the heart let me know!
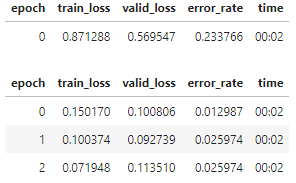
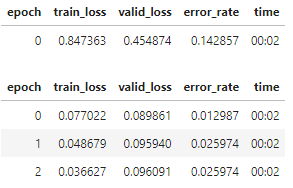
Great idea! I gave it a shot to see if resnet18 performs better with 192 pixel images or 224 pixel images.
Sized to 192:
Sized to 224:
I’m not sure the results are meaningful because of the small dataset size for the birds vs. forest problem. So I might need to try with some other datasets.
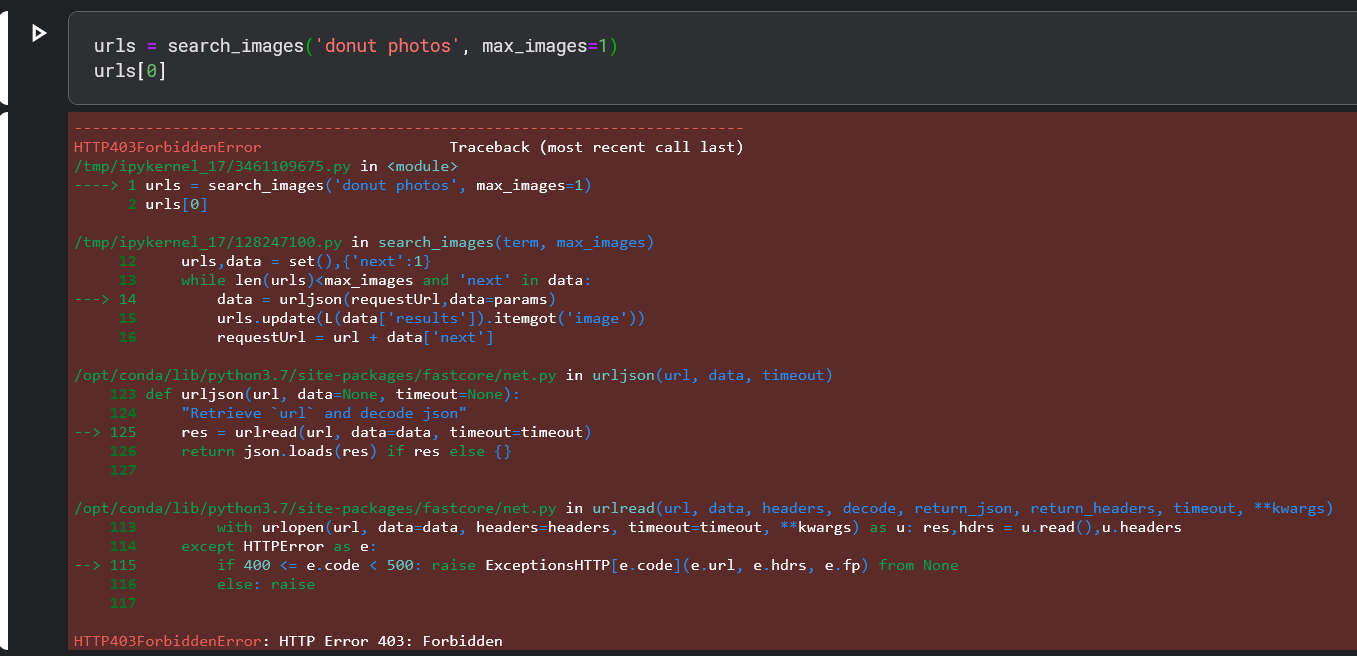
I’m having trouble running the search_images function, i did ran it couple of times before in the afternoon, but when I ran it again in the night, it has this http error 403. I’m thinking that there’s some sort of API limit for urlread(), is this accurate or could there be another limitation that I’m not aware of? Any help or pointers would be appreciated.