thanks @slawekbiel
Just my personal preference: I would prefer lessons’ official topics to remain pinned 
Who’s with me? 

3 Likes
I have similar experience. Generally speaking, I think it is just the way things are.
Is there any specific example you have in mind?
Maybe this addresses your issue? In short: what class is probs[1], what does it contain, etc.
Any update on this?
Both your link to https://book.fast.ai/ above and the relevant link in github fastbook just send me straight to course homepage.
Recommended tutorials would be really useful.
(Same happened for the questionnaire solution link but happily you made a wiki for this Fastbook Chapter 1 questionnaire solutions (wiki) - thanks)
@wlw if you go to the very top of this posting, under Lesson resources, click the link for the The fastai book which will take u to the github version
@foobar8675 thanks. I think you might have misunderstood (may be my bad though!)…
I have been reading the github version of the book already. This online book refers to a “book website” with helpful resources, and includes a corresponding link to https://book.fast.ai
Unfortunately this link just redirects to course homepage - which I have also already been using.
1 Like
The resources will be added to the course website. See this issue.
Well I try the code and it workd, though that upload button did not display the image I was uploading. And when I changed the image it the count on the button went up, though it still references the (0) item. So quite confusing.
I’ve setup my linux server with a nvidia 1080Ti with software installed to go through the jupyer notebooks of the course. I’m going through the 01_intro jupyter notebook and successfully evaluated every cell in sequence until I reached this cell:
dls = TextDataLoaders.from_folder(untar_data(URLs.IMDB), valid=‘test’, bs=4)
learn = text_classifier_learner(dls, AWD_LSTM, drop_mult=0.5, metrics=accuracy)
learn.fine_tune(4, 1e-2)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.727598 | 0.495284 | 0.785680 | 15:27 |
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.734474 | 00:01 |
Even though I’ve reduced the batch size to 4, it still errors out with the following message:
RuntimeError: CUDA out of memory. Tried to allocate 92.00 MiB (GPU 0; 10.92 GiB total capacity; 3.25 GiB already allocated; 63.75 MiB free; 3.31 GiB reserved in total by PyTorch)
Exception raised from malloc at /opt/conda/conda-bld/pytorch_1595629395347/work/c10/cuda/CUDACachingAllocator.cpp:272 (most recent call first):
frame #0: c10::Error::Error(c10::SourceLocation, std::string) + 0x4d (0x7f54c568d77d in /opt/anaconda3/envs/fastai2/lib/python3.8/site-packages/torch/lib/libc10.so)
Is there a workaround, or should I give up running this model training on my linux computer because it is underpowered? Is there any other workaround for this issue?
Cheers,
Nasir
Hello Nasir,
Welcome to the community.
As it is mentioned in lesson 1, there is absolutely no need to set up your own machine yet, as it will only take away time and energy from learning.
I for one have also struggled with this in an previous attempt to finish this course (I believe 2018). Believe me, it is not worth the hassle. Any free cloud service machine like Google colab or paperspace will easily outperform your 1080ti. And your own card will never be able to scale up when the time arrives that you need the performance.
Unless you have really sensitive data, I would advise to do as Jeremy says and use a cloud provider with ready to use fast.ai images. It is worth it.
Cheers!
Michael
A 1080Ti should be able to handle a bs=32 on that cell. I should know as I have the same configuration.
It sounds like the gpu memory is not clearing properly. I would restart the kernel, run the first cell of the notebooks to do the imports, then skip to run this cell.
Maybe have a second shell going to watch the ram usage with nvidia-smi?
1 Like
Thanks Michael for the advice. I’ll fall back on using cloud platform if problem persists. However, I find it curious that I was able to run all the other cells in the notebook.
Cheers,
Nasir
Thanks for the advice. I’ll plow through the remaining notebooks and see if the problem recurs elsewhere. Despite multiple kernel restarts and importing of libraries and reducing batch size to 4 , I get the same error.
Cheers,
Nasir
Hey guys,
thanks for this amazing tutorial.
So im not 100% sure if i got everything corretly.
I am not able to open the files in jupyter, where do i get the files? Can i directly open them from github?
Idk how but it works on my google Colab.
In the first lession you say: if this takes more than 5 min, its obvious that something goes wrong -> mine took about 30 mins and i even stopped it.
May you help me?
THis course seems to be super nice but not really good structured.
thanks in advance
Hi Community,
Can anyone help me understand why there are differences in the error_rates (first dogs/cats model) between runs ? First time I run the “#CLICK ME” cell I got pretty good error_rates (around 0.005…), in the following executions of the cell I’m getting better or worst rates, sometimes even pretty bad ones like 0.015
How to understand those differences between executions ?
Thanks
Similar to @Nasir65 above, I am not able to run that particular cell from the 01_intro notebook, except that I am using a ml.p2.xlarge instance within Sagemaker as recommended by the book.
from fastai.text.all import *
dls = TextDataLoaders.from_folder(untar_data(URLs.IMDB), valid='test')
learn = text_classifier_learner(dls, AWD_LSTM, drop_mult=0.5, metrics=accuracy)
learn.fine_tune(4, 1e-2)
The initial code with no batch size specified returned the CUDA out of memory error. I then lowered to a batch size of 32 and let the model run for ~25 minutes but my output seems to show that epoch 0 repeated?
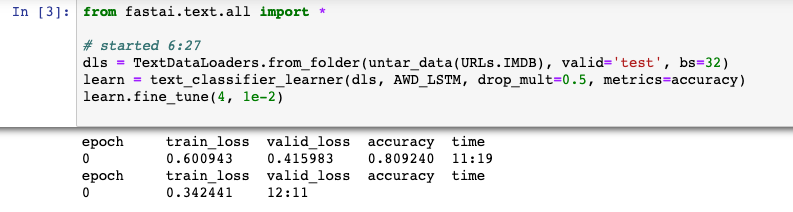
A batch size of 16 shows the same behavior.
I’ve restarted the kernel and just let this one cell run after importing the libraries at the top but no luck. Any suggestions? All the other models train in less than a minute so I feel like something is off here.
I’m new to Deep Learning and this book. This question is regarding chapter 1.I’m able to run a notebook and the cats and dogs model. But when I try and “test” the model in the next step using an image of my own, I encounter an error. I’m hoping to find what I’m doing wrong and how to remedy. Thanks!

In notebook have quote:
A Jupyter widget could not be displayed because the widget state could not be found. This could happen if the kernel storing the widget is no longer available, or if the widget state was not saved in the notebook. You may be able to create the widget by running the appropriate cells.
May be this help you
uploader = SimpleNamespace(data = ['images/chapter1_cat_example.jpg'])
Hi, I m getting the below error in 01_intro.ipynb when executing
path = untar_data(URLs.CAMVID_TINY)
dls = SegmentationDataLoaders.from_label_func(
path, bs=8, fnames = get_image_files(path/“images”),
label_func = lambda o: path/‘labels’/f’{o.stem}_P{o.suffix}’,
codes = np.loadtxt(path/‘codes.txt’, dtype=str)
)
learn = unet_learner(dls, resnet34)
learn.fine_tune(8)
errror
TypeError Traceback (most recent call last)
in ()
7
8 learn = unet_learner(dls, resnet34)
----> 9 learn.fine_tune(8)
17 frames
/usr/local/lib/python3.6/dist-packages/torch/overrides.py in handle_torch_function(public_api, relevant_args, *args, **kwargs)
1069 raise TypeError("no implementation found for ‘{}’ on types that implement "
1070 ‘torch_function: {}’
-> 1071 .format(func_name, list(map(type, overloaded_args))))
1072
1073 def has_torch_function(relevant_args: Iterable[Any]) -> bool:
TypeError: no implementation found for ‘torch.nn.functional.cross_entropy’ on types that implement torch_function: [<class ‘fastai.torch_core.TensorImage’>, <class ‘fastai.torch_core.TensorMask’>]