Not currently, there isn’t support for this
1 Like
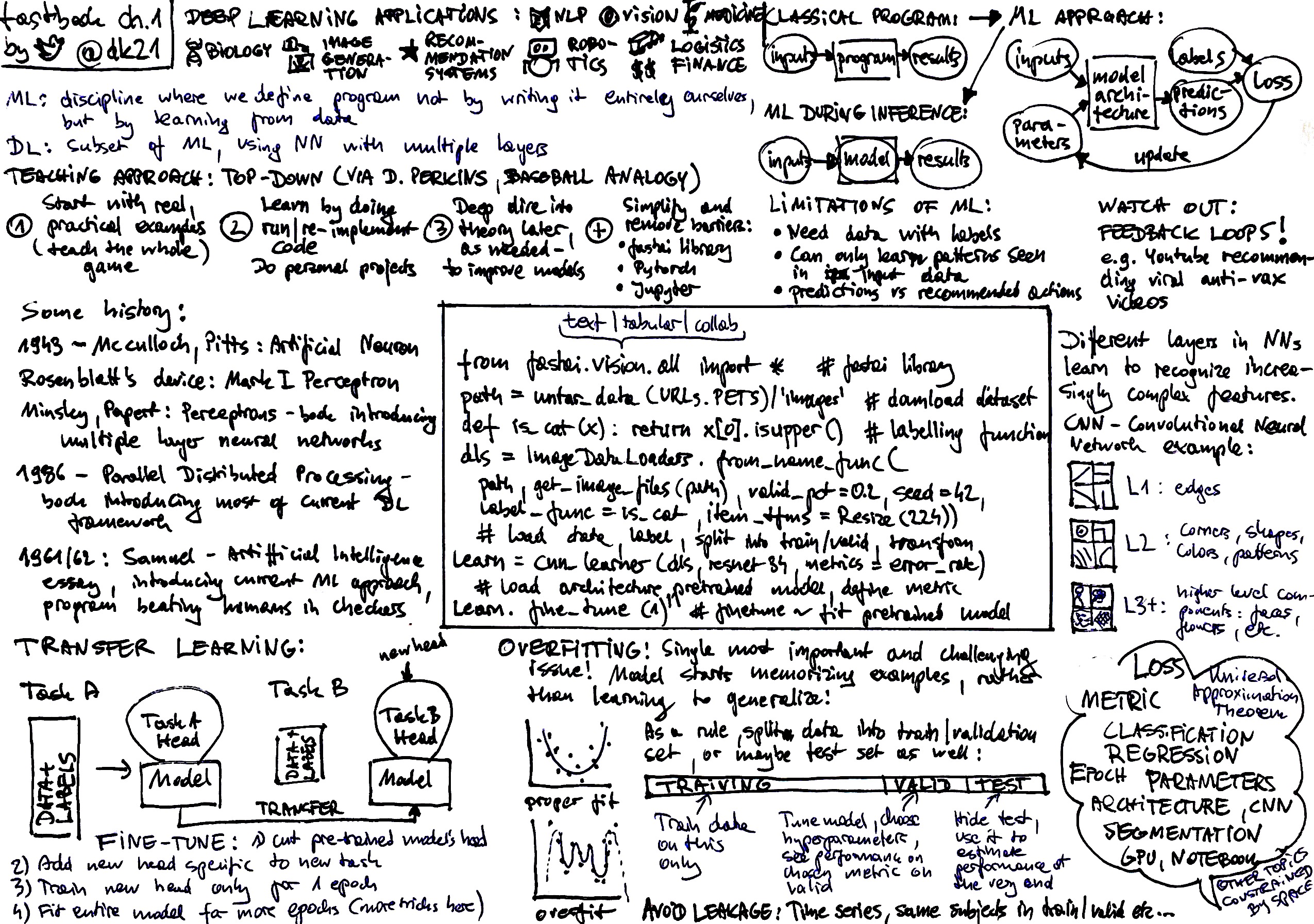
See attached my visual 1-page notes from chapter of the book - not fully correlated with the lesson, but I’d like to make a visual like that for every chapter of the book.
7 Likes
this looks great!
mine don’t look that pretty  . how do you create them if i can ask? is this visual re-drawn from the draft or is this the first attempt?
. how do you create them if i can ask? is this visual re-drawn from the draft or is this the first attempt?
It’s redrawn from draft, takes a bit of planning where to put which part, and the space limit forces some choices
2 Likes
In the utils.py file, there’s a set_seed(42) method, which sets the random seed. Is it still necessary then to call it here? Thanks,
dls = ImageDataLoaders.from_name_func(path,
get_image_files(path),
valid_pct=0.2,
seed=42,
label_func=is_cat,
item_tfms=Resize(224))
1 Like
If you want the same splits then yes. If you don’t specify it each time, the splits will be different (and this is on purpose). If you follow ImageDataLoaders in the source code eventually you’ll see that seed is passed into our RandomSplitter.
1 Like
I’m curious in that case-where is the seed from utils useful?
1 Like
Actually I’m incorrect. set_seed does more than just the splits seed, it sets torch and the random’s seeds as well, for full reproducibility. So no, you don’t have to pass in 42:
(First time seeing this function, cool!)
2 Likes
So debugging the code, ImageDataLoaders.from_name_func(…) eventually calls this:
in /fasta2/data/transforms.py
def RandomSplitter(valid_pct=0.2, seed=None, **kwargs):
"Create function that splits `items` between train/val with `valid_pct` randomly."
def _inner(o, **kwargs):
if seed is not None: torch.manual_seed(seed) <--------
rand_idx = L(int(i) for i in torch.randperm(len(o)))
cut = int(valid_pct * len(o))
return rand_idx[cut:],rand_idx[:cut]
return _inner
does the same as util.py IF seed is passed. So i think, in theory, we don’t have to pass it since it’s already set in util.py (at least for this example in the first notebook).
It was very useful for us to always get the same results in the book.
1 Like
The model can only learn on the task that you gave it examples for ![]() (and should also in most cases be evaluated on unseen data, but data ideally coming from the same distribution as the train data).
(and should also in most cases be evaluated on unseen data, but data ideally coming from the same distribution as the train data).
Here, your sentence has negative connotations, we can tell that, but is it a sentence likely to be seen in the context of a movie review? Movie reviews is the data that we trained our model on!
If you would like to perform a probably better test, maybe try writing a review of a movie, similar to the reviews the model trained on, and see what you get?
This is actually a great question Sylvain and I remember Jeremy speaking to this at some point of the lecture but I don’t recall now where - we can only expect our model to perform well on data that is similar to what it has been trained on. There is some nuance to this, but overall this is a great high level view to start from!
5 Likes
Very interesting results just playing around with words on the sentiment of a movie review. Certain words seem to have quite an effect on how the model considers a review to be positive or negative. Here’s the effect of adding the word “not” to a sentence.
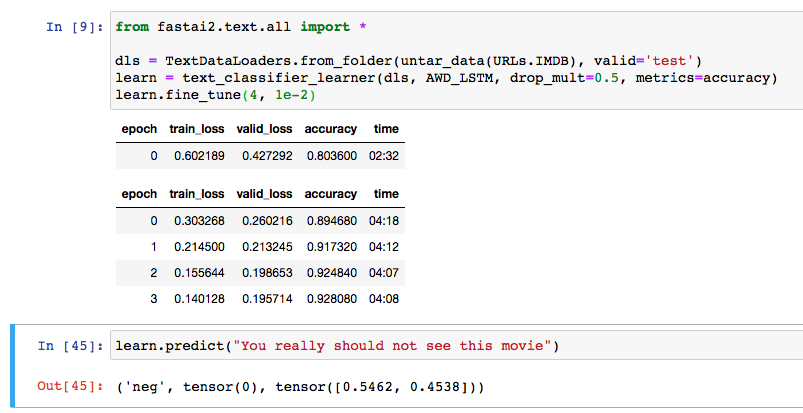

IMDb reviews are generally around 1500+ words, so you’d need something more like that to get a good result (or train on smaller docs as well).
2 Likes
Yes, I noticed it was better with longer reviews.
The example in the book is:
learn.predict(“I really liked that movie!”)
which is definitely short.
learn.predict(“I did not like that movie!”)
gives a positive review which is surprising.
My example was not a good one… But funny
The example in the book is
learn.predict(“I really liked that movie!”)
which gives positive
learn.predict(“I did not like that movie!”)
gives positive also.
Seems like the model does much better on longer reviews.
Somehow I feel that "I did not like that movie!” doesn’t sound very negative… it would be interesting to see if anyone writing a negative review ever used such a phrase. Maybe the model has a similar intuition?
Access the notebook via ipywidgets enabled JupyterLab, as shown here
hi fastai communiity, any insight into why there seems to be 2 passes (2 blocks of epoch iterations) during the training and fine tuning of the models in the lesson 1 notebook
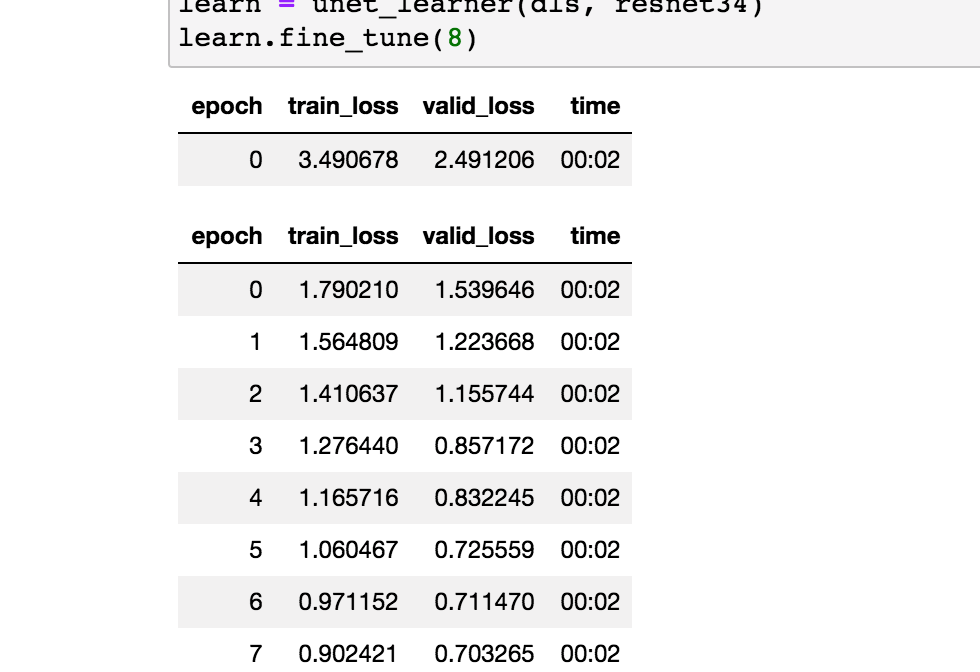
is this because there is one for each layer?
On a separate note, how are folks handling getting into the fastai python code to get a sense of what is being done. I am working on paperspace and was planning on cloning the github repo to my local machine and then using a python IDE to start exploring. Is this the best way?
In the case of transfer learning there are two phases. First with the pretrained part frozen and only the newly added parameters are trained (by default for 1 epoch) and then the whole model together with the pretrained part. See the code here.
As for your general question, I’ve actually created a tutorial for that
3 Likes