Hi all,
I’m very happy to announce that after a lot of work, we’ve finally been able to pretty soundly improve the leaderboard score for 5 epoch Imagewoof.
Updates -
1 - More than just for 5 epochs: we’ve now used the same techniques for both Nette and ImageWoof, 5 and 20epochs, with all px size variations and beaten the previous records in every case (12 total cases). Continued out-performance on the 20 epochs was encouraging.
2 - Thanks to @muellerzr, if you update to the latest version of fastAI you can now use:
learn.fit_fc() to run the flat + cosine anneal we used in place of fit_one_cycle, and try it out for yourself.
It took a lot of new techniques combined and instead of reading the long Mish activation function thread where most of this happend, I thought it might be better to try and summarize here. This way, you can quickly see an overview of new techniques that we had success with, and see if they might be of use in your own work and you’ll be aware of what’s out there now.
(And to clarify when I say we - @Seb / @muellerzr / @grankin / @Redknight / @oguiza / @fgfm all made vital contributions to this effort).
First, here was the original ImageWoof 5 epoch, 128 score since March:
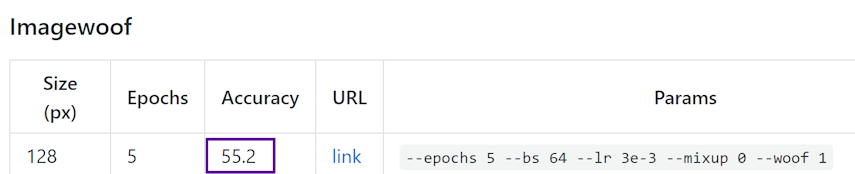
and here’s our latest result as of today:
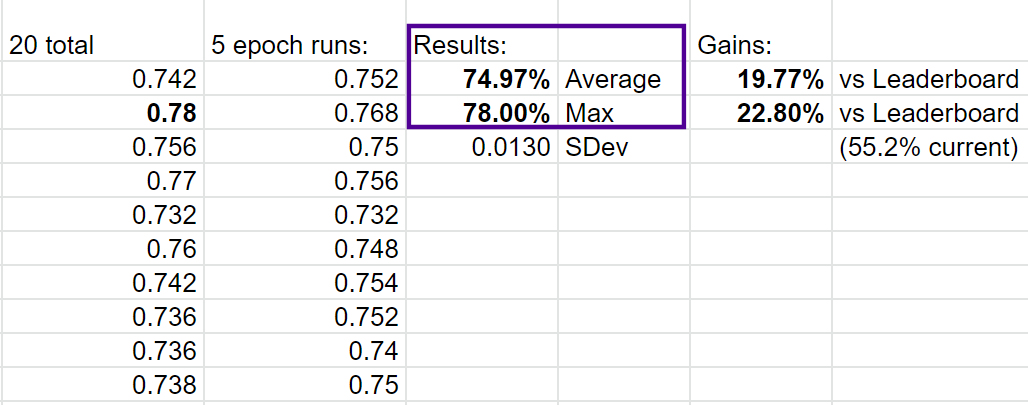
As you can see, it’s quite a nice jump. There are multiple changes involved to get there:
1 - Optimizer - we changed to use Ranger instead of Adam. Ranger came from combining RAdam + LookAhead.
The summary of each - RAdam (Rectified Adam) was the result of Microsoft research looking into why all adaptive optimizers need a warmup or else they usually shoot into bad optima. The answer was because it’s making premature jumps when the variance of the adaptive learning rate is too high. In short, it needs to wait to see more data to really start making larger decisions…and they achieve this automatically by adding in a rectifier that dynamically tamps down the adaptive learning rate until the variance settles. Thus, no warmup needed!
LookAhead - LookAhead was developed in part by Geoffrey Hinton (you may have heard of him?)keeps a separate set of weights from the optimizer, and then every k steps (5 or 6) interpolates between it’s weights and the optimizer and then splits the difference. The result is like having a buddy system to explore the loss terrain…the faster optimizer explores, LookAhead lets it scout while making sure it can be pulled back if it’s a bad optima. Thus, safer / better exploration and faster convergence. ( have a more detailed articles on both, which I’ll link below).
Note that RangerLars (Ranger + Layer Wise Adaptive Rate Scaling) is actively being worked on and looks really good as well (also called Over9000, but @Redknight developed along with @grankin / @oguiza / @fgfm / @muellerzr are rapidly driving this forward). It’s very close with Ranger and may surpass it in the future.
2 - Flat + Cosine annealing training curve instead of OneCycle - this is the invention of @grankin, and matched what I was suspecting after testing out a lot of new optimizers. Namely, the OneCycle appears to do well with vanilla Adam, but all that up and down tends to mess up the newer optimizers.
Thus, instead of cycling the learning rate up and down, we simply use a flat start (i.e. 4e-3), and then at 50% - 75%, start dropping the learning rate based on a cosine anneal.
That made a big performance jump regardless of the optimizer (except Adam). I had tested Novograd, stochastic Adam, etc.
3 - Mish activation function instead of ReLU - Mish is a new activation function that was released in a paper about a week ago. It has a much smoother curve vs relu, and in theory, that drives information more deeply through the network. It is slower than ReLU, but on average adds about 1-3% improvement vs ReLU. (details in article link below). There’s an MXResNet now to make it easy to use XResNet + Mish (link below).
4 - Self attention layer - this is @Seb’s brainchild, along with input from @grankin, so I’m stretching to describe it but it’s a small layer added to MXResNet / XResNet. The self attention layer is designed to help leverage long range dependencies within an image vs the more local feature focus of convolutions. (Original paper link below, but maybe @Seb will do a post on it in more detail).
5 - Resize Image quality - Finally, we found that resizing images to 128 from the original ImageWoof images (instead of resizing from 160->128) produces higher quality that literally adds ~2% accuracy. @fgfm confirmed the reason behind that, but it was a bit of a surprise. Thus, you’ll want to pay attention to how you are getting to your image size as it does have a non-trivial impact.
ImageNette/Woof serve a great gatekeeper function: One thing I should add is that the value of having these test datasets like ImageNette and especially ImageWoof (due to being harder) is quite great. I tested a lot of activation functions this year before Mish, and in most cases while things looked awesome in the paper, they would fall down as soon as I put them to use on more realistic toy datasets like ImageNette/Woof.
Many of the papers show results using MNIST or CIFAR-10, which really has minimal proof of how they will truly fare in my experience.
Thus, a big thanks to @jeremy for making these as it really does serve as an important gatekeeper to quickly testing what has real promise and what does not!
That’s the quick overview - now for some links if you want to dig deeper:
If you want to test out MXResNet and all the changes above -
There’s a full github repo with a training workbook so you can readily test out these features and ideally improve on them. You can run with and without self attention layer as well via --sa 1 parameter:
Here’s some more reading info to learn more about Ranger / Mish and Self Attention:
Mish activation:
and github for it:
Ranger optimizer:
Self- Attention:
https://arxiv.org/abs/1805.08318 (and see @Seb for more 
Most of the developments ended up happening in this Mish thread:
https://forums.fast.ai/t/meet-mish-new-activation-function-possible-successor-to-relu
Finally @muellerzr put together a nice list of all the relevant papers (including some like Novograd that were tested but didn’t ultimately get used):
- Mish: A Self Regularized Non-Monotonic Neural Activation Function
- Bag of Tricks for Resnet (aka the birth of xResNet)
- Lookahead Optimizer: k steps forward, 1 step back
- On the Variance of the Adaptive Learning Rate and Beyond, RAdam
- Self-Attention Generative Adversarial Networks
- Large Batch Optimization for Deep Learning, LAMB
- Stochastic Gradient Methods with Layer-wise
Adaptive Moments for Training of Deep Networks, Novograd - LARS paper (Large Batch Training of Neural Networks
Anyway, exciting times for deep learning as a lot of new ideas make their way into testing and possibly long term success.
Enjoy!
Less