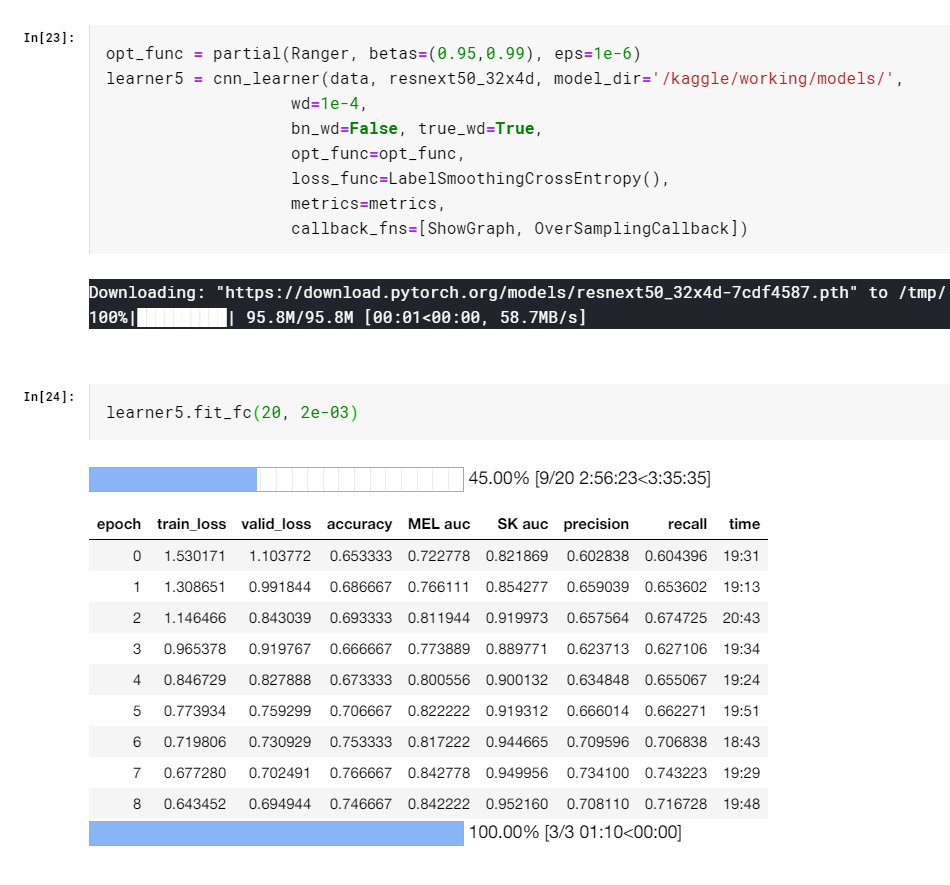
I used fit_fc() method from official fastai repo, which is known as “flat cosine annealing” lr scheduler. But I’m facing this issue many times with various choices of total epochs and platforms (google colab, kaggle) when the notebook line learn.fit_fc() didn’t complete the given total epochs but no errors were returned.
Hi, when I made fit_fc I noticed this issue occurring every once in while. I believe that it was the optimizer itself but I’ll have to double check. Are you retraining the same learner and it’s having this issue? Eg: train one model for 20 epochs and then retrain again? That’s the exact scenario where I saw some troubles
Hi, I often have the issue with the first run of fit_fc. You might be right about the optimizer, as I have only used fit_fc with Ranger. Have you found any workaround?
Yeah I also found an issue when calling lr_find() first causing the learner didn’t reset its weights and start fitting with a too big lr using fit_fc, but nothing like this issue here. Also the actual running epoch (9/20 in this case) is very random.
I did the test and was able to confirm that with the same total epoch (20), same other settings (run in the same notebook), fit_fc with AdamW ran into the same issue. Maybe you can check it out? Thank you.
@MichaelScofield could you show exactly the steps you’re doing from start to finish? As I just ran it start to finish for 20 and then 30 epochs and it worked fine. (mabye share the kernel if you can)
Edit: AHA! I found the bug. It has to do with the callbacks. Let me see which one
It’s the oversampling callback and I know exactly why. fit_fc goes and looks at total training batches to determine when to start annealing, and oversampling changes that on the fly, causing the bug as it thinks its “finished” much earlier than it has.
Great to hear that. I guessed so when add oversampling callback due to class imbalance in my problem, how dumb did I not include it . But how quickly you can identify it was amazing. So do you have any suggestions using this callback with fit_fc?
Considering they both begin on on_train_begin i’m unsure quite how that would wind up working, my apologies Perhaps mabye merging the two together from the OverSampling callback source code?
The current issue is I believe that the end point is being set first, then the oversampling occurs and so we finish much sooner than anticipated.
I will have a deeper look and compare fit_fc and LessW2020’s flattenAnneal function in his ImageWoof notebook since I also did a test on the latter and didn’t find the bug. Anyway, thank you for your support @muellerzr.
Nope it is. At the time it was not (I was working on getting it merged). Also wrote the championship notebook
Back to the issue, I can try to modify the callback into an actual callback and adjust to try to come up with something. Give me a few moments (a merged scheduler with flattenAnneal to get it working)
So right now, it is creating a new train_dl with the correct oversampled length. So I am not sure why the problem is arising. Could it be due to the order of which the callbacks are applied? If so, isn’t there an _order attribute to control this?

 . But how quickly you can identify it was amazing. So do you have any suggestions using this callback with
. But how quickly you can identify it was amazing. So do you have any suggestions using this callback with 
