I ran quick tests on Lamb, RangerLamb (lookahead+lamb), RangerAdam (adam+lookahead)…at least for five epochs, none were competitive. Small sample set of 1x5 epochs each, but the big ding on lamb is it’s like 2-3x as slow as Ranger…so for the same time, Ranger could run 2x+ epochs and beat on that basis alone.
Regardless, here’s the runs and their loss curves…basically what appears to really set Ranger ahead is it continues with a fairly aggressive path in the middle of the run. I believe this is from the solid launch pad that RAdam provides at the start. Lamb and variants all start off ok but then flatten quite a bit in the middle. I suppose this might be the trust ratio clamping down too hard there, but not sure.
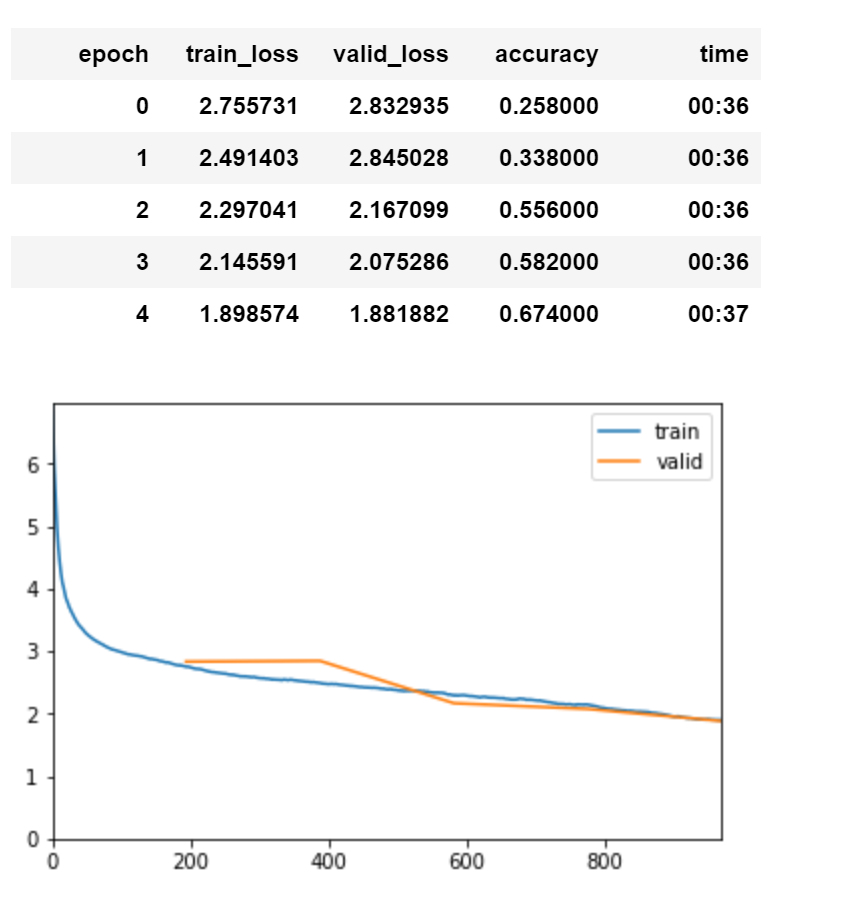
Ranger curve:
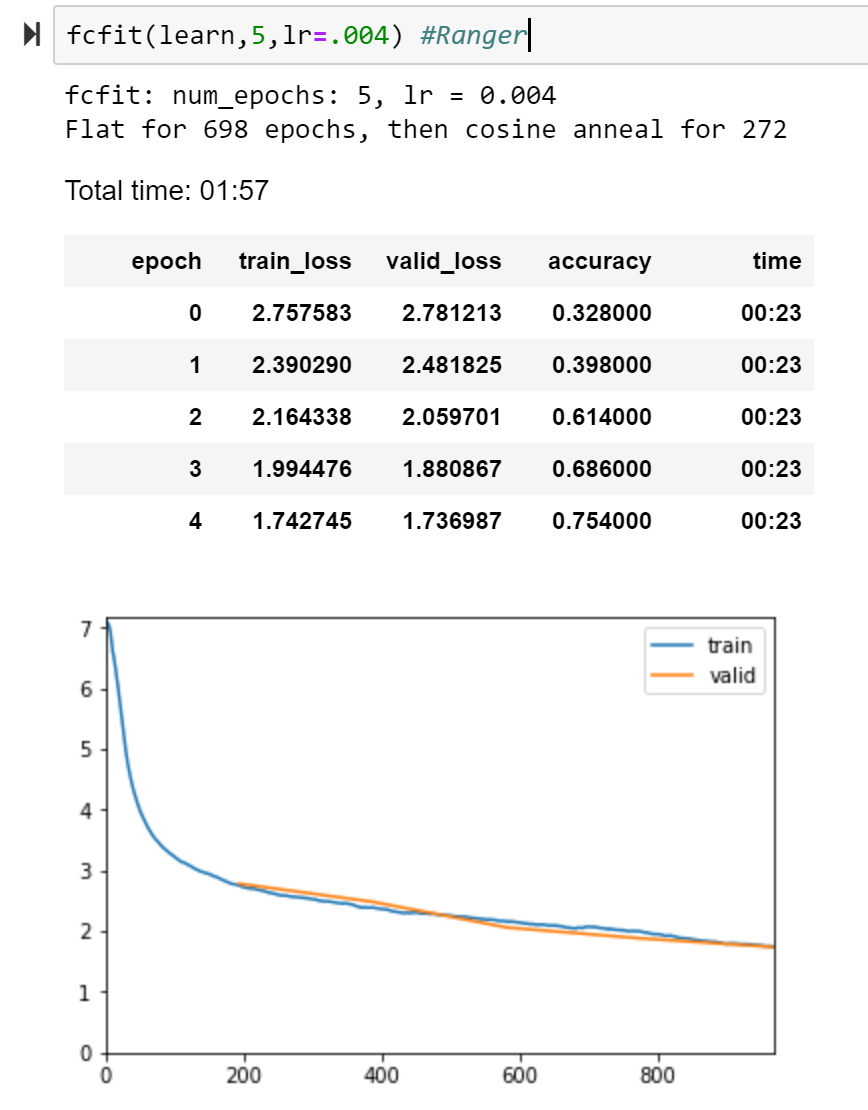
Lamb curve:
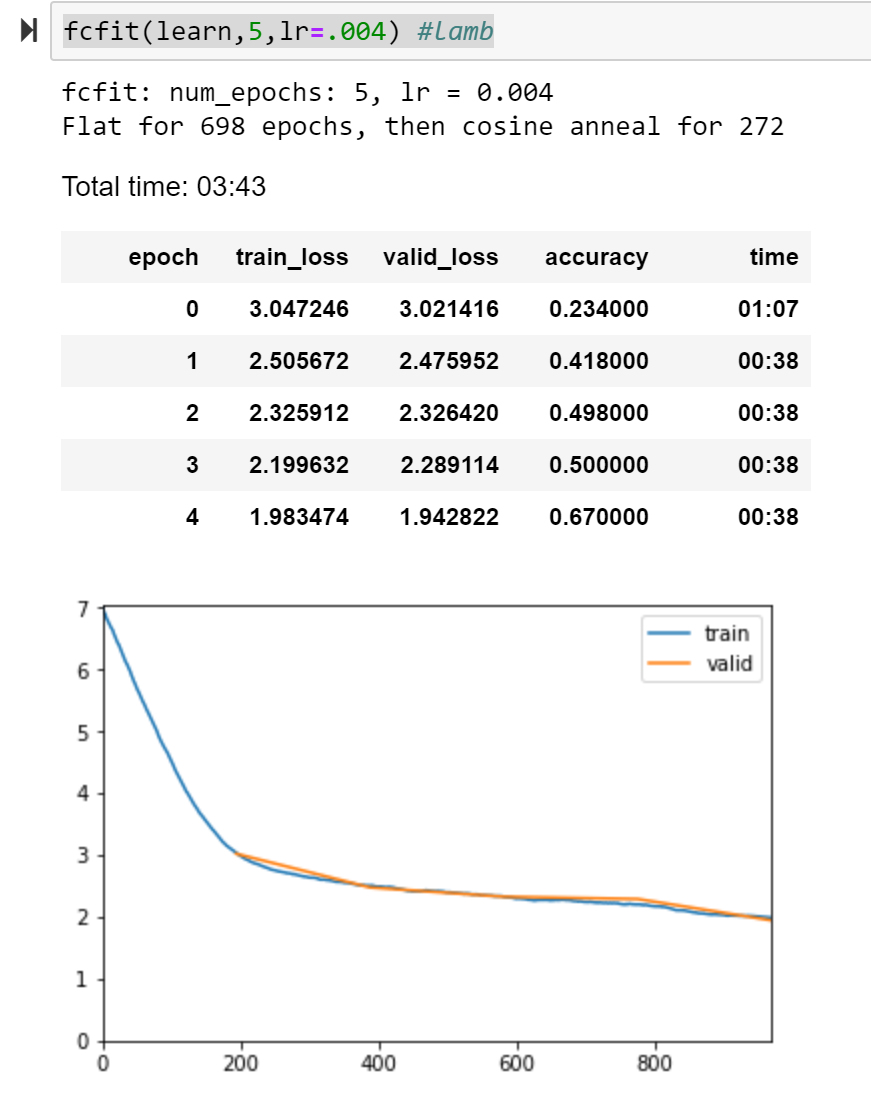
RangerLamb:
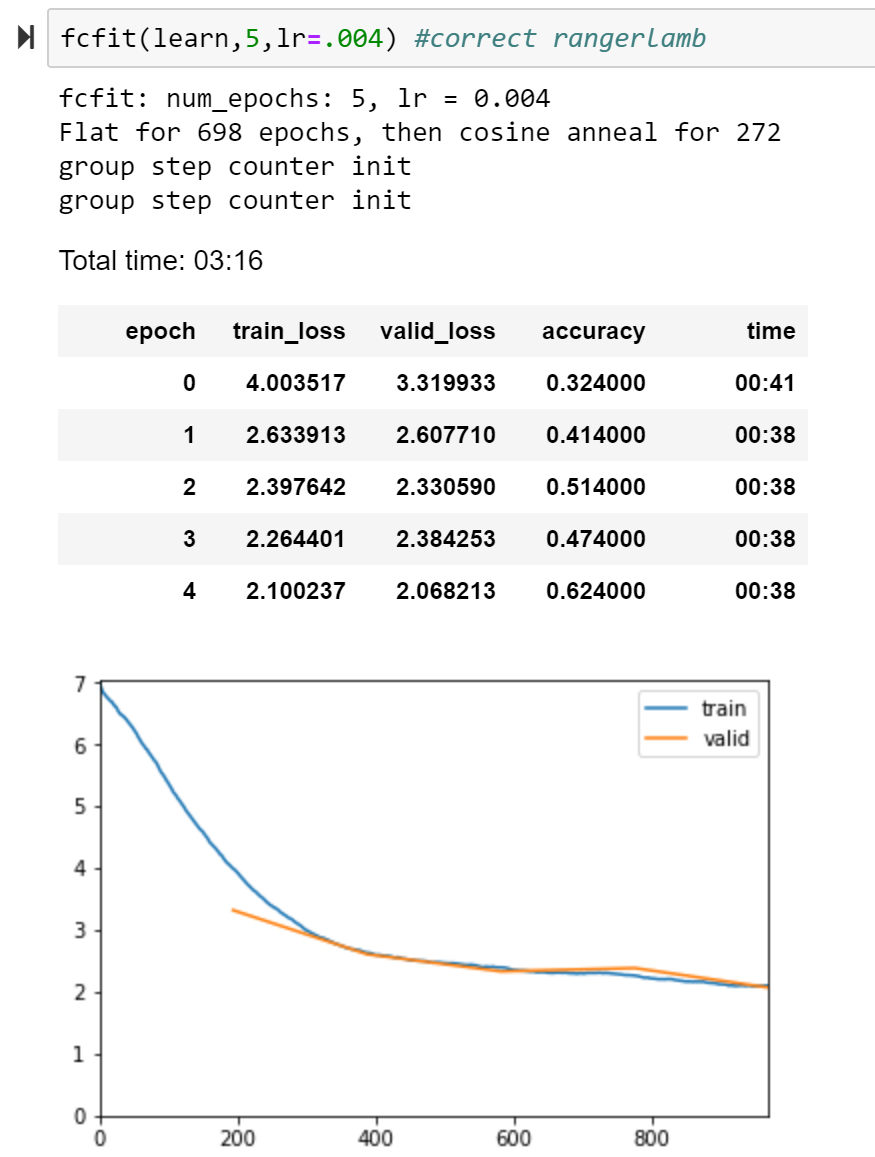
RangerAdam (Lamb running as Adam is why it’s so slow…same calcs but then ditches trust ratio):