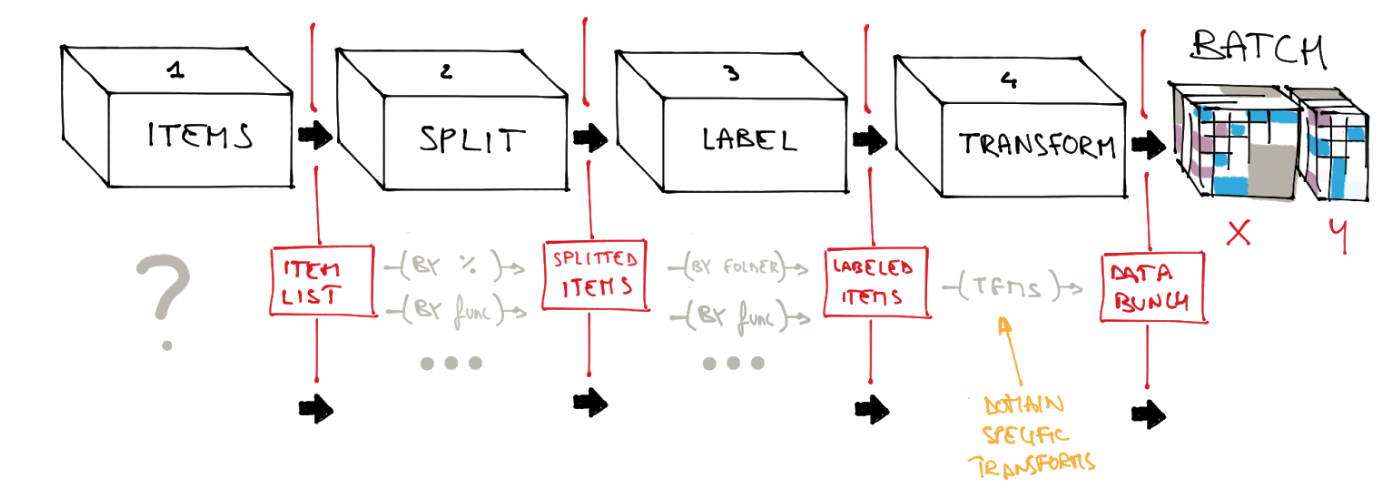
You may want to take a look at my SwiftAI project which I posted about (https://forums.fast.ai/t/share-your-work-here-part-2/41392/39?u=stephenjohnson) a week ago. You can find the project here https://github.com/sjaz24/SwiftAI. You may find some things that you like or maybe you will hate it all, but it might give you some ideas. When I started working on this I looked at the DataBlocks you had created and came to the same conclusion you have which is it can be tough to try to port it directly as is into Swift. Anyway, I’m planning to do a little bit of a rewrite of what I have but the basic gist is that I’ve created a DatasetBuilder. This builds the various datasets (train, valid, test). Through extensions you can load the inputs (from folder paths, from CSV, Coco, etc), then split them, etc. New functionality is added via extensions. The functionality you want the builder to have is added via functions which add captured closures which are later executed when you call the build method. Each time the build function is called the datasets are recreated allowing for re-use. Functions can be added or subtracted to the builder via the builderId (shown in second example) so that there can be a default builder for certain types of projects and then tweaked as needed via the builderIds. Below are 2 examples. The first for classification and the second for bounding boxes. The datasets are what I like to call the logical model. That is they don’t actually load the images and perform the augmentations. They just now have for example the file paths and Y values.
let datasetBuilder = DatasetBuilder<URL, String>()
.withFilesFromFolders(parentFolder: folder, extensions: extensions, trainFolder: trainFolder,
validFolder: validFolder, testFolder: testFolder)
.withFileLabelsOfParentFolder(includeTest: testHasLabels)
.withClasses(classes)
.withSample(of: .Train, pct: trainingPct, fixed: fixedSamples)
.withSample(of: .Valid, pct: validPct, fixed: fixedSamples)
.withSample(of: .Test, pct: testPct, fixed: fixedSamples)
if !testHasLabels {
datasetBuilder.withY(classes[0], type: .Test)
}
datasetBuilder.build()
let datasetBuilder = DatasetBuilder<URL, Y>()
.withCocoJson(builderId: "TrainCocoJson", atPath: "\(folder)/\(trainCocoJson)", imagesFolder: "\(folder)/\(trainFolder)",
largestBBoxOnly: largestBBoxOnly)
.withCocoJson(builderId: "ValidCocoJson", atPath: "\(folder)/\(validCocoJson)", imagesFolder: "\(folder)/\(validFolder)", type: .Valid,
largestBBoxOnly: largestBBoxOnly)
.withCocoJson(builderId: "TestCocoJson", atPath: "\(folder)/\(testCocoJson)", imagesFolder: "\(folder)/\(testFolder)", type: .Test,
largestBBoxOnly: largestBBoxOnly)
.withSample(of: .Train, pct: trainingPct, fixed: fixedSamples)
.withSample(of: .Valid, pct: validPct, fixed: fixedSamples)
.withSample(of: .Test, pct: testPct, fixed: fixedSamples)
datasetBuilder.build()
Next come the transforms (badly named; planning on changing it to pipeline or something like that) but these are what, for example, load the images, normalize them, flip them, convert them to tensors, etc. Presently they do this one image at a time, but am going to change them to do a batch at a time. Below is an example, that opens the image, resizes it, converts the PIL image to tensor, normalizes it, flips it and one hot encodes the Y value. The second one is for bounding boxes. I’m planning to make this more like the DatasetBuilder by using closures instead of classes. These “transforms” (what you call processors) are applied by DataLoader when you ask for a batch. I call this the physical model.
Transforms<URL,Y,PythonObject,V>([
OpenImage(type: imageType),
ResizeImage(size: imageSize),
PilToTensor(),
Normalize(divisor: nil, mean: imageMean, std: imageStd),
Flip(type: .Horizontal),
ClassLabelToInt(classes: classes)
])
Transforms<URL, Y, PythonObject, PythonObject>([
OpenImage(type: imageType),
NormalizeBoundingBoxes(),
ResizeImage(size: imageSize),
PilToTensor(),
Flip(type: .Horizontal),
Normalize(divisor: nil, mean: imageMean, std: imageStd)
])
So the DataSet builder loads the “logical” model of your data whereas the DataLoader loads the “physical” model of the data. This allows easy access to both sets and makes matching up the two quite easy for example when running test and getting nice output. Since I couldn’t use PyTorch’s DataLoader stuff because no current easy way to have Python call Swift and because PyTorch isn’t great at multi-threading, I also implemented my own BatchSamplers (RandomSample, SequentialSampler, etc.)
Then, what I’ve done is to use the Template pattern to provide defaults for most things. I call the top level the “Project” for example VisionProject which calls various methods to create a Learner. See example below from VisionProject class. Most of these methods are actually implemented by subclasses or a default is provided which can be overridden. For example, the DatasetBuilders shown above are returned when getDatasetBuilder() (shown below) is called for a single classification project or bounding box project. And the transforms shown above are returned for the getTransforms() (shown below) is called.
open func learner() -> Learner<X,Y,U,V> {
let datasetBuilder = getDatasetBuilder()
let datasets = datasetBuilder.build()
if classes.count == 0 {
classes = datasetBuilder.classes!
}
let transforms = getTransforms()
let dataLoaders = DataLoaderSet(datasets: datasets, bs: batchSize, transforms: transforms)
let model = getSavedModel()
let lossFunc = getLossFunc()
let testModel = getTestModel(forModel: model)
let callbacks = getCallbacks(forModel: model)
let testCallback = getTestCallback()
printSummary(dataLoaders: dataLoaders)
return Learner(dataLoaders: dataLoaders, model: model, lossFunc: lossFunc, optimizer: optimizer,
learningRate: learningRate, callbacks: callbacks, testModel: testModel,
testCallback: testCallback)
}
What this boils down to is that a Pascal bounding box project can be defined something like this
public class Pascal : LargestBBoxODVP {
public override init() {
super.init()
folder = "./data/pascal"
validFolder = "train"
trainCocoJson = "pascal_train2007.json"
validCocoJson = "pascal_val2007.json"
testCocoJson = "pascal_test2007.json"
savedModelPath = "./pascal.pth"
}
}
Or if some tweaking is desired some of the defaults can be overridden and modified like for DogsCats. In this example, the default dataset builder is being modified by having the FileLabelsOfParentFolder removed and FileLabelsFromFilename added. Also a fixed split is being done with 20% of files being moved from the training to the validation set.
public class DogsCats : SingleClassICVP {
public var testResultsFilePath = "./dogs-vs-cats-redux-kaggle-submission.csv"
public override init() {
super.init()
folder = "./data/dogscats"
classes = ["cat","dog"]
savedModelPath = "./dogs-cats-model.pth"
}
override open func getDatasetBuilder() -> DatasetBuilder<URL, String> {
let datasetBuilder = super.getDatasetBuilder()
let at = datasetBuilder.indexOf(builderId: "FileLabelsOfParentFolder")
return datasetBuilder.without(builderId: "FileLabelsOfParentFolder")
.withFileLabelsFromFilename(at: at) { String($0.prefix { $0 != "." }) }
.withFixedSplit(from: .Train, to: .Valid, pct: 0.2)
}
override public func getTestCallback() -> TestCallback<URL,String> {
return DogsCatsReduxKaggleCallback(classes: classes, testResultsFilePath: testResultsFilePath)
}
}