Here are the questions!:
- Why do we first resize to a large size on the CPU, and then to a smaller size on the GPU?
This concept is known as presizing. Data augmentation is often applied to the images and in fastai it is done on the GPU. However, data augmentation can lead to degradation and artifacts, especially at the edges. Therefore, to minimize data destruction, the augmentations are done on a larger image, and then RandomResizeCrop is performed to resize to the final image size.
- If you are not familiar with regular expressions, find a regular expression tutorial, and some problem sets, and complete them. Have a look on the book website for suggestions.
To be done by the reader.
- What are the two ways in which data is most commonly provided, for most deep learning datasets?
- Individual files representing items of data, such as text documents or images.
- A table of data, such as in CSV format, where each row is an item, each row which may include filenames providing a connection between the data in the table and data in other formats such as text documents and images.
- Look up the documentation for L and try using a few of the new methods is that it adds.
To be done by the reader.
- Look up the documentation for the Python pathlib module and try using a few methods of the Path class.
To be done by the reader
- Give two examples of ways that image transformations can degrade the quality of the data.
- Rotation can leave empty areas in the final image
- Other operations may require interpolation which is based on the original image pixels but are still of lower image quality
- What method does fastai provide to view the data in a DataLoader?
DataLoader.show_batch
- What method does fastai provide to help you debug a DataBlock?
DataBlock.summary
- Should you hold off on training a model until you have thoroughly cleaned your data?
No. It is best to create a baseline model as soon as possible.
- What are the two pieces that are combined into cross entropy loss in PyTorch?
Cross Entropy Loss is a combination of a Softmax function and Negative Log Likelihood Loss.
- What are the two properties of activations that softmax ensures? Why is this important?
It makes the outputs for the classes add up to one. This means the model can only predict one class. Additionally, it amplifies small changes in the output activations, which is helpful as it means the model will select a label with higher confidence (good for problems with definite labels).
- When might you want your activations to not have these two properties?
When you have multi-label classification problems (more than one label possible).
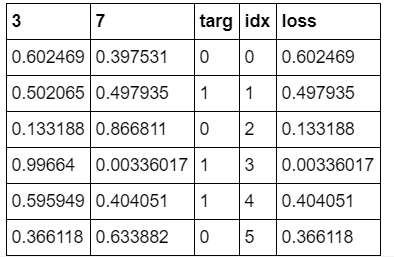
- Calculate the “exp” and “softmax” columns of <
MISSING!
- Why can’t we use torch.where to create a loss function for datasets where our label can have more than two categories?
Because
torch.wherecan only select between two possibilities while for multi-class classification, we have multiple possibilities.
- What is the value of log(-2)? Why?
This value is not defined. The logarithm is the inverse of the exponential function, and the exponential function is always positive no matter what value is passed. So the logarithm is not defined for negative values.
- What are two good rules of thumb for picking a learning rate from the learning rate finder?
Either one of these two points should be selected for the learning rate:
one order of magnitude less than where the minimum loss was achieved (i.e. the minimum divided by 10)
the last point where the loss was clearly decreasing.
- What two steps does the fine_tune method do?
- Train the new head (with random weights) for one epoch
- Unfreeze all the layers and train them all for the requested number of epochs
- In Jupyter notebook, how do you get the source code for a method or function?
Use
??after the function ex:DataBlock.summary??
- What are discriminative learning rates?
Discriminative learning rates refers to the training trick of using different learning rates for different layers of the model. This is commonly used in transfer learning. The idea is that when you train a pretrained model, you don’t want to drastically change the earlier layers as it contains information regarding simple features like edges and shapes. But later layers may be changed a little more as it may contain information regarding facial feature or other object features that may not be relevant to your task. Therefore, the earlier layers have a lower learning rate and the later layers have higher learning rates.
- How is a Python slice object interpreted when passed as a learning rate to fastai?
The first value of the slice object is the learning rate for the earliest layer, while the second value is the learning rate for the last layer. The layers in between will have learning rates that are multiplicatively equidistant throughout that range.
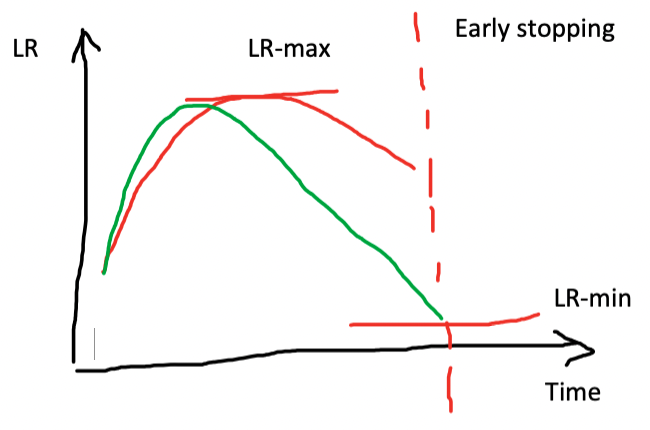
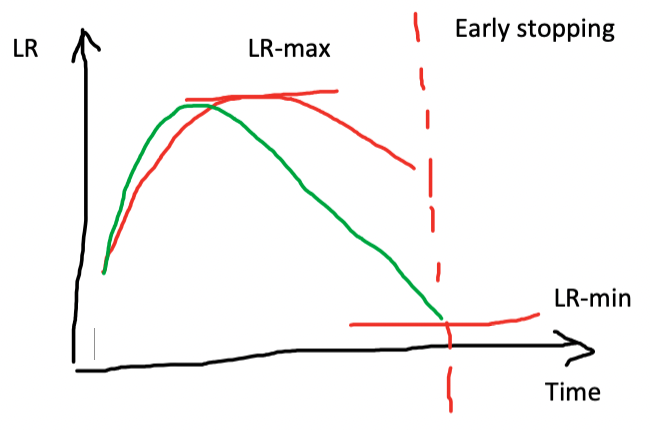
- Why is early stopping a poor choice when using one cycle training?
If early stopping is used, the training may not have time to reach lower learning rate values in the learning rate schedule, which could easily continue to improve the model. Therefore, it is recommended to retrain the model from scratch and select the number of epochs based on where the previous best results were found.
- What is the difference between resnet 50 and resnet101?
The number 50 and 101 refer to the number of layers in the models. Therefore, ResNet101 is a larger model with more layers versus ResNet50. These model variants are commonly as there are ImageNet-pretrained weights available.
- What does to_fp16 do?
This enables mixed-precision training, in which less precise numbers are used in order to speed up training.

{kind=link}