Questionnaire entry 13 may be slightly misleading (Why does SGD use mini batches?).
Perhaps you could say a few words about the differences between (1) Stochastic Gradient Descent, (2) Mini Batch Gradient Descent, and (3) Batch Gradient Descent.
@SMEissa there are a few smaller groups that are active-please check the study groups section, we have a book reading group and a Mid-Level API ones that are active.
There are few open collaborations created by Radek. If you find something interesting and want to start a group-please do so!
Gradient descent is when you use all your data to compute the gradients, then update your weights. Stochastic gradient descent is when you use mini-batches with random samples of your training set to compute the gradients, then update your weights.
Technically: Gradient Descent ==> Gradient is calculated using Whole data Stochastic Gradient Descent ==> Gradient is calculated using one sample of data Mini Batch Gradient Descent ==> Gradient is calculated using batch(generally given by batch-size) of data
Traditionally, we call mini-batch gradient descent as SGD.
I don’t really like this terminology that is pretty old (and absolutely no one does true stochastic gradient descent anyway). When we say stochastic gradient descent, it’s the mini-batch gradient descent (and usually, when people that want to refer to the stochastic gradient descent of this definition, they say true stochastic gradient descent).
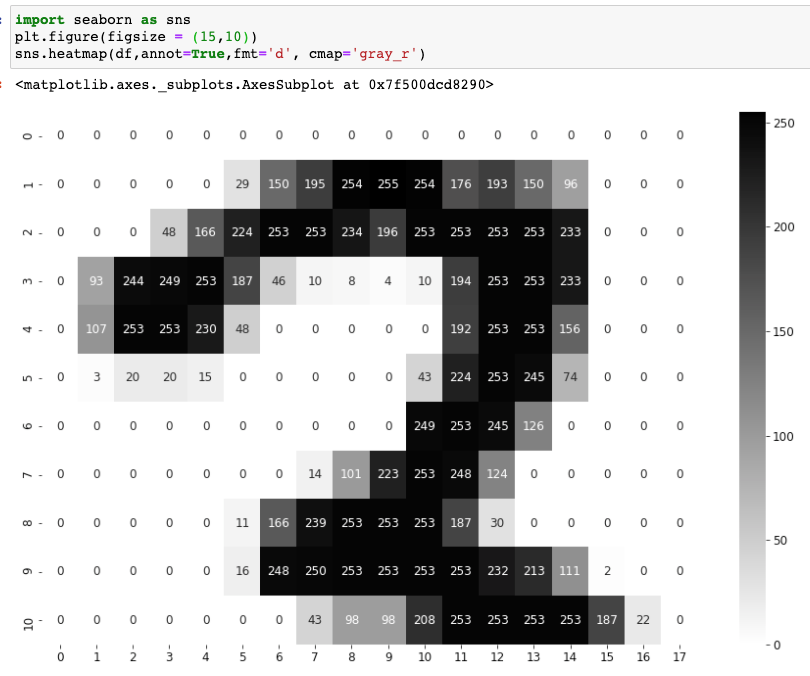
To be able to do a matrix multiplication with the set of those images by our weights: you can’t multiply a tensor of size N x 28 x 28 by some weights, but you can multiply a tensor of size N x 784 by some weights.