Here are the questions:
- What is self-supervised learning?
Training a model without the use of labels. An example is a language model.
- What is a language model?
A language model is a self-supervised model that tries to predict the next word of a given passage of text.
- Why is a language model considered self-supervised learning?
There are no labels (ex: sentiment) provided during training. Instead, the model learns to predict the next word by reading lots of provided text with no labels.
- What are self-supervised models usually used for?
Sometimes, they are used by themselves. For example, a language model can be used for autocomplete algorithms! But often, they are used as a pre-trained model for transfer learning.
- Why do we fine-tune language models?
We can fine-tune the language model on the corpus of the desired downstream task, since the original pre-trained language model was trained on a corpus that is slightly different than the one for the current task.
- What are the three steps to create a state-of-the-art text classifier?
- Train a language model on a large corpus of text (already done for ULM-FiT by Sebastian Ruder and Jeremy!)
- Fine-tune the language model on text classification dataset
- Fine-tune the language model as a text classifier instead.
- How do the 50,000 unlabeled movie reviews help create a better text classifier for the IMDb dataset?
By learning how to predict the next word of a movie review, the model better understands the language style and structure of the text classification dataset and can, therefore, perform better when fine-tuned as a classifier.
- What are the three steps to prepare your data for a language model?
- Tokenization
- Numericalization
- Language model DataLoader
- What is tokenization? Why do we need it?
Tokenization is the process of converting text into a list of words. It is not as simple as splitting on the spaces. Therefore, we need a tokenizer that deals with complicated cases like punctuation, hypenated words, etc.
- Name three different approaches to tokenization.
- Word-based tokenization
- Subword-based tokenization
- Character-based tokenization
- What is ‘xxbos’?
This is a special token added by fastai that indicated the beginning of the text.
- List 4 rules that fastai applies to text during tokenization.
Here are all the rules:
fix_html:: replace special HTML characters by a readable version (IMDb reviews have quite a few of them for instance) ;replace_rep:: replace any character repeated three times or more by a special token for repetition (xxrep), the number of times it’s repeated, then the character ;replace_wrep:: replace any word repeated three times or more by a special token for word repetition (xxwrep), the number of times it’s repeated, then the word ;spec_add_spaces:: add spaces around / and # ;rm_useless_spaces:: remove all repetitions of the space character ;replace_all_caps:: lowercase a word written in all caps and adds a special token for all caps (xxcap) in front of it ;replace_maj:: lowercase a capitalized word and adds a special token for capitalized (xxmaj) in front of it ;lowercase:: lowercase all text and adds a special token at the beginning (xxbos) and/or the end (xxeos).
- Why are repeated characters replaced with a token showing the number of repetitions, and the character that’s repeated?
We can expect that repeated characters could have special or different meaning than just a single character. By replacing them with a special token showing the number of repetitions, the model’s embedding matrix can encode information about general concepts such as repeated characters rather than requiring a separate token for every number of repetitions of every character.
- What is numericalization?
This refers to the mapping of the tokens to integers to be passed into the model.
- Why might there be words that are replaced with the “unknown word” token?
If all the words in the dataset have a token associated with them, then the embedding matrix will be very large, increase memory usage, and slow down training. Therefore, only words with more than
min_freqoccurrence are assigned a token and finally a number, while others are replaced with the “unknown word” token.
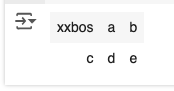
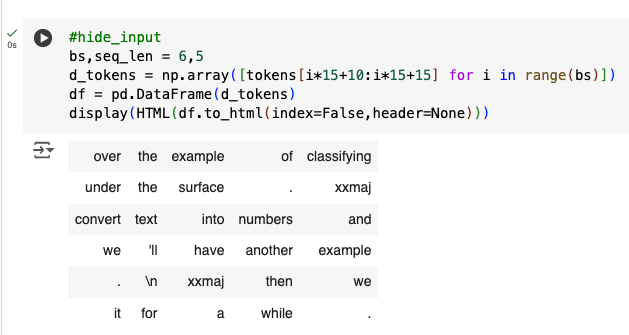
- With a batch size of 64, the first row of the tensor representing the first batch contains the first 64 tokens for the dataset. What does the second row of that tensor contain? What does the first row of the second batch contain? (Careful—students often get this one wrong! Be sure to check your answer against the book website.)
a. The dataset is split into 64 mini-streams (batch size)
b. Each batch has 64 rows (batch size) and 64 columns (sequence length)
c. The first row of the first batch contains the beginning of the first mini-stream (tokens 1-64)
d. The second row of the first batch contains the beginning of the second mini-stream
e. The first row of the second batch contains the second chunk of the first mini-stream (tokens 65-128)
I think this visualisation will help us understand this question better.

- Why do we need padding for text classification? Why don’t we need it for language modeling?
Since the documents have variable sizes, padding is needed to collate the batch. Other approaches. like cropping or squishing, either to negatively affect training or do not make sense in this context. Therefore, padding is used. It is not required for language modeling since the documents are all concatenated.
- What does an embedding matrix for NLP contain? What is its shape?
It contains vector representations of all tokens in the vocabulary. The embedding matrix has the size (vocab_size x embedding_size), where vocab_size is the length of the vocabulary, and embedding_size is an arbitrary number defining the number of latent factors of the tokens.
- What is perplexity?
Perplexity is a commonly used metric in NLP for language models. It is the exponential of the loss.
- Why do we have to pass the vocabulary of the language model to the classifier data block?
This is to ensure the same correspondence of tokens to index so the model can appropriately use the embeddings learned during LM fine-tuning.
- What is gradual unfreezing?
This refers to unfreezing one layer at a time and fine-tuning the pretrained model.
- Why is text generation always likely to be ahead of automatic identification of machine generated texts?
The classification models could be used to improve text generation algorithms (evading the classifier) so the text generation algorithms will always be ahead.