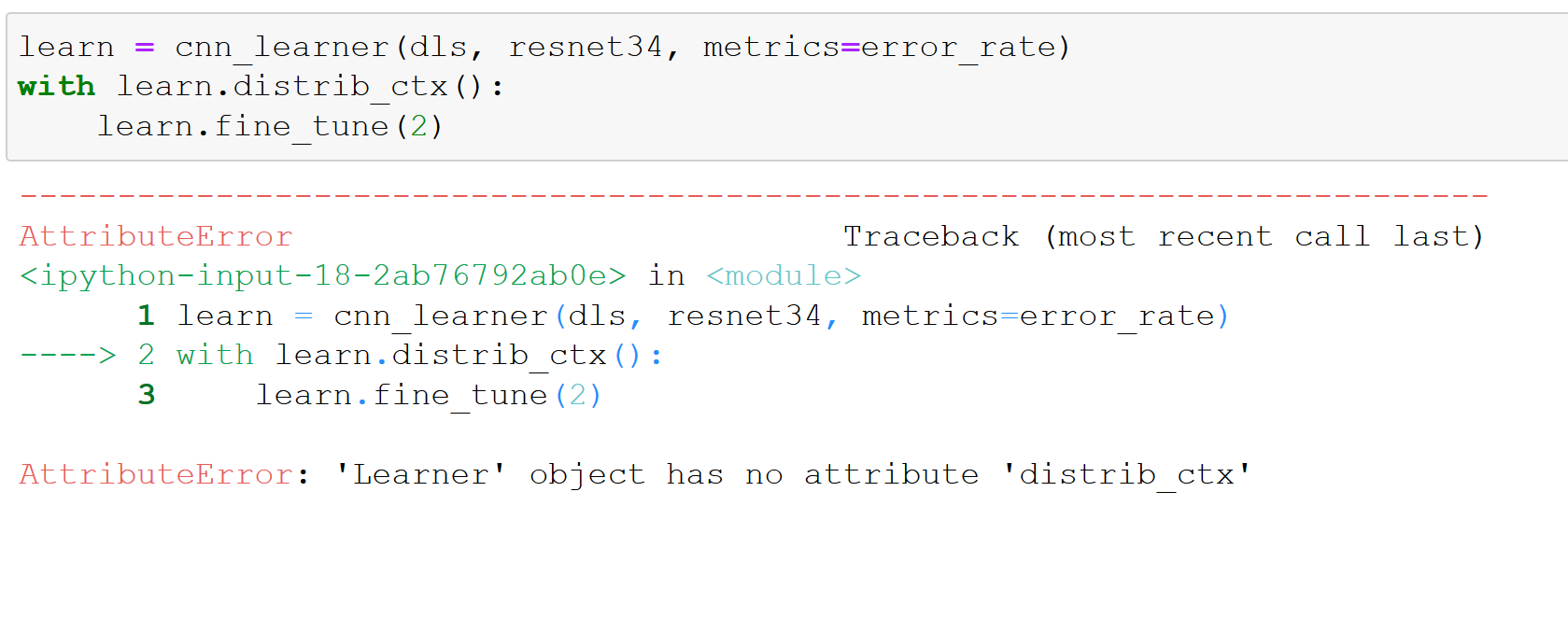
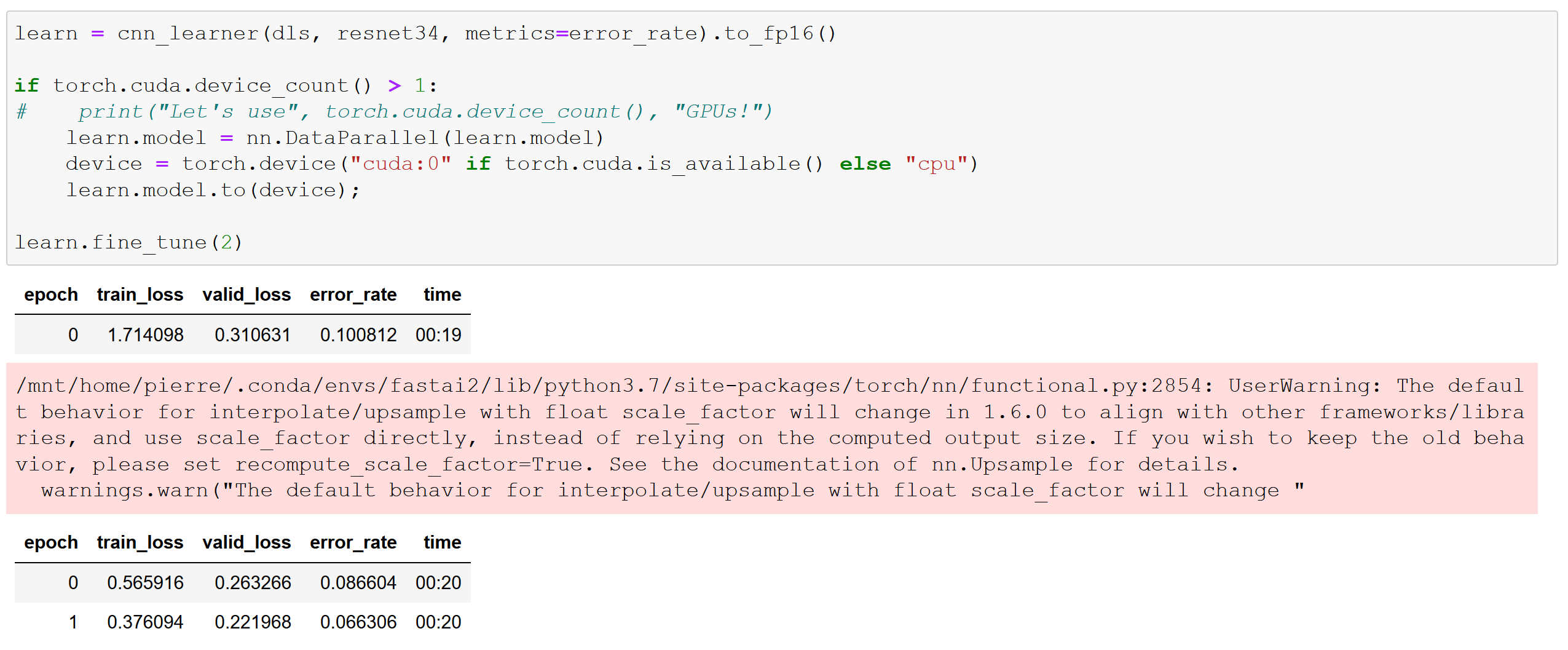
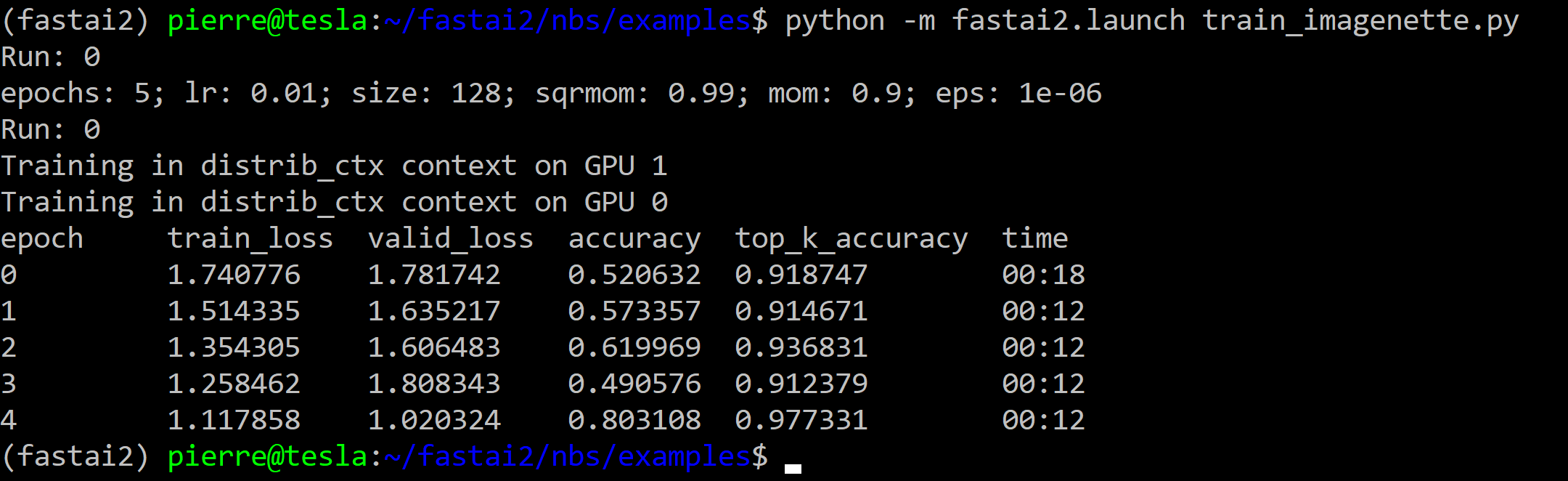
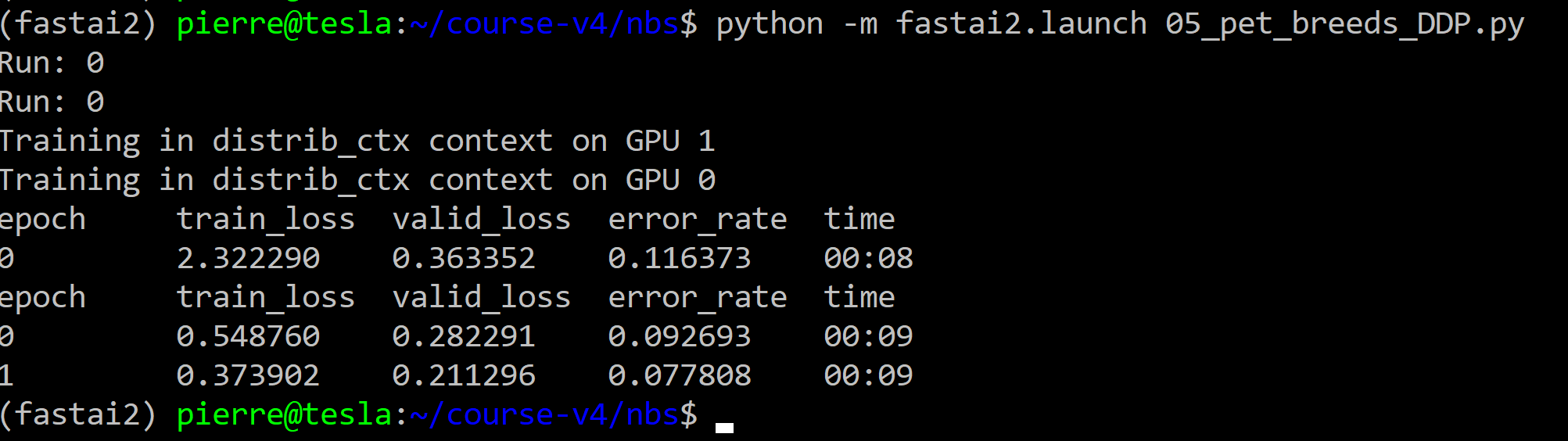
fastai v2 and Transformers | Problems not solved with DDP
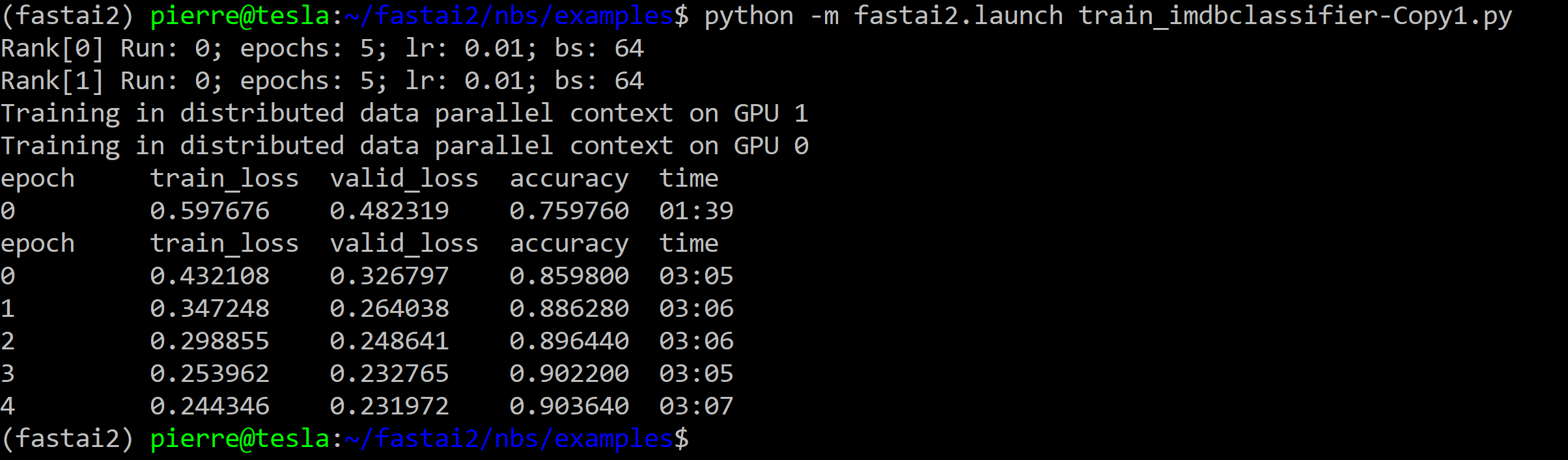
I wanted to run in DDP the Transformers tutorial of Sylvain using the code of train_imdbclassifier.py.
To do this, I created the script 39_tutorial.transformers_DDP.py that I ran with the following command in the same environment (server with 2 GPUs NVIDIA V100 32Go within a fastai v2 virtual environment) than the one of my (successful) tests with the fastai v2 scripts (see this post):
python -m fastai2.launch 39_tutorial.transformers_DDP.py
However, it did not work.
@ilovescience, @morgan, @wgpubs, @muellerzr, @sgugger: if you have an idea about it, you are welcome to post it. Thank you in advance.
Versions of frameworks: transformers==3.0.0 | fastai2==0.0.17
(fastai2) pierre@tesla:~/fastai2/nbs$ python -m fastai2.launch 39_tutorial.transformers_DDP.py
Some weights of GPT2LMHeadModel were not initialized from the model checkpoint at gpt2 and are newly initialized: ['h.0.attn.masked_bias', 'h.1.attn.masked_bias', 'h.2.attn.masked_bias', 'h.3.attn.masked_bias', 'h.4.attn.masked_bias', 'h.5.attn.masked_bias', 'h.6.attn.masked_bias', 'h.7.attn.masked_bias', 'h.8.attn.masked_bias', 'h.9.attn.masked_bias', 'h.10.attn.masked_bias', 'h.11.attn.masked_bias', 'lm_head.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Some weights of GPT2LMHeadModel were not initialized from the model checkpoint at gpt2 and are newly initialized: ['h.0.attn.masked_bias', 'h.1.attn.masked_bias', 'h.2.attn.masked_bias', 'h.3.attn.masked_bias', 'h.4.attn.masked_bias', 'h.5.attn.masked_bias', 'h.6.attn.masked_bias', 'h.7.attn.masked_bias', 'h.8.attn.masked_bias', 'h.9.attn.masked_bias', 'h.10.attn.masked_bias', 'h.11.attn.masked_bias', 'lm_head.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Rank[0] Run: 0; epochs: 1; lr: 0.0001; bs: 8; sl: 1024
Rank[1] Run: 0; epochs: 1; lr: 0.0001; bs: 8; sl: 1024
Training in distributed data parallel context on GPU 1
Training in distributed data parallel context on GPU 0
epoch train_loss valid_loss perplexity time
The current process just got forked. Disabling parallelism to avoid deadlocks...
To disable this warning, please explicitly set TOKENIZERS_PARALLELISM=(true | false)
The current process just got forked. Disabling parallelism to avoid deadlocks...
To disable this warning, please explicitly set TOKENIZERS_PARALLELISM=(true | false)
The current process just got forked. Disabling parallelism to avoid deadlocks...
To disable this warning, please explicitly set TOKENIZERS_PARALLELISM=(true | false)
The current process just got forked. Disabling parallelism to avoid deadlocks...
To disable this warning, please explicitly set TOKENIZERS_PARALLELISM=(true | false)
The current process just got forked. Disabling parallelism to avoid deadlocks...
To disable this warning, please explicitly set TOKENIZERS_PARALLELISM=(true | false)
The current process just got forked. Disabling parallelism to avoid deadlocks...
To disable this warning, please explicitly set TOKENIZERS_PARALLELISM=(true | false)
The current process just got forked. Disabling parallelism to avoid deadlocks...
To disable this warning, please explicitly set TOKENIZERS_PARALLELISM=(true | false)
The current process just got forked. Disabling parallelism to avoid deadlocks...
To disable this warning, please explicitly set TOKENIZERS_PARALLELISM=(true | false)
The current process just got forked. Disabling parallelism to avoid deadlocks...
To disable this warning, please explicitly set TOKENIZERS_PARALLELISM=(true | false)
The current process just got forked. Disabling parallelism to avoid deadlocks...
To disable this warning, please explicitly set TOKENIZERS_PARALLELISM=(true | false)
The current process just got forked. Disabling parallelism to avoid deadlocks...
To disable this warning, please explicitly set TOKENIZERS_PARALLELISM=(true | false)
The current process just got forked. Disabling parallelism to avoid deadlocks...
To disable this warning, please explicitly set TOKENIZERS_PARALLELISM=(true | false)
The current process just got forked. Disabling parallelism to avoid deadlocks...
To disable this warning, please explicitly set TOKENIZERS_PARALLELISM=(true | false)
The current process just got forked. Disabling parallelism to avoid deadlocks...
To disable this warning, please explicitly set TOKENIZERS_PARALLELISM=(true | false)
The current process just got forked. Disabling parallelism to avoid deadlocks...
To disable this warning, please explicitly set TOKENIZERS_PARALLELISM=(true | false)
The current process just got forked. Disabling parallelism to avoid deadlocks...
To disable this warning, please explicitly set TOKENIZERS_PARALLELISM=(true | false)
Traceback (most recent call last):
File "39_tutorial.transformers_DDP.py", line 66, in <module>
runs: Param("Number of times to repeat training", int)=1,
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastscript/core.py", line 76, in call_parse
return _f()
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastscript/core.py", line 73, in _f
func(**args.__dict__)
File "39_tutorial.transformers_DDP.py", line 126, in main
learn.fit_one_cycle(epochs, lr)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastcore/utils.py", line 431, in _f
return inst if to_return else f(*args, **kwargs)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastai2/callback/schedule.py", line 113, in fit_one_cycle
self.fit(n_epoch, cbs=ParamScheduler(scheds)+L(cbs), reset_opt=reset_opt, wd=wd)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastcore/utils.py", line 431, in _f
return inst if to_return else f(*args, **kwargs)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastai2/learner.py", line 200, in fit
self._do_epoch_train()
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastai2/learner.py", line 175, in _do_epoch_train
self.all_batches()
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastai2/learner.py", line 153, in all_batches
for o in enumerate(self.dl): self.one_batch(*o)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastai2/data/load.py", line 98, in __iter__
for b in _loaders[self.fake_l.num_workers==0](self.fake_l):
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 345, in __next__
data = self._next_data()
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 856, in _next_data
return self._process_data(data)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 881, in _process_data
data.reraise()
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/torch/_utils.py", line 395, in reraise
raise self.exc_type(msg)
RuntimeError: Caught RuntimeError in DataLoader worker process 0.
Original Traceback (most recent call last):
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/torch/utils/data/_utils/worker.py", line 178, in _worker_loop
data = fetcher.fetch(index)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py", line 34, in fetch
data = next(self.dataset_iter)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastai2/data/load.py", line 107, in create_batches
yield from map(self.do_batch, self.chunkify(res))
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastai2/data/load.py", line 128, in do_batch
def do_batch(self, b): return self.retain(self.create_batch(self.before_batch(b)), b)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastai2/data/load.py", line 127, in create_batch
def create_batch(self, b): return (fa_collate,fa_convert)[self.prebatched](b)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastai2/data/load.py", line 45, in fa_collate
return (default_collate(t) if isinstance(b, _collate_types)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/torch/utils/data/_utils/collate.py", line 55, in default_collate
return torch.stack(batch, 0, out=out)
RuntimeError: stack expects each tensor to be equal size, but got [3029] at entry 0 and [4514] at entry 1
0 nan 00:00
^CTraceback (most recent call last):
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastai2/distributed.py", line 166, in distrib_ctx
yield self
File "39_tutorial.transformers_DDP.py", line 126, in main
learn.fit_one_cycle(epochs, lr)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastcore/utils.py", line 431, in _f
return inst if to_return else f(*args, **kwargs)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastai2/callback/schedule.py", line 113, in fit_one_cycle
self.fit(n_epoch, cbs=ParamScheduler(scheds)+L(cbs), reset_opt=reset_opt, wd=wd)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastcore/utils.py", line 431, in _f
return inst if to_return else f(*args, **kwargs)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastai2/learner.py", line 200, in fit
self._do_epoch_train()
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastai2/learner.py", line 175, in _do_epoch_train
self.all_batches()
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastai2/learner.py", line 153, in all_batches
for o in enumerate(self.dl): self.one_batch(*o)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastai2/data/load.py", line 98, in __iter__
for b in _loaders[self.fake_l.num_workers==0](self.fake_l):
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 345, in __next__
data = self._next_data()
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 856, in _next_data
return self._process_data(data)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 881, in _process_data
data.reraise()
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/torch/_utils.py", line 395, in reraise
raise self.exc_type(msg)
RuntimeError: Caught RuntimeError in DataLoader worker process 0.
Original Traceback (most recent call last):
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/torch/utils/data/_utils/worker.py", line 178, in _worker_loop
data = fetcher.fetch(index)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py", line 34, in fetch
data = next(self.dataset_iter)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastai2/data/load.py", line 107, in create_batches
yield from map(self.do_batch, self.chunkify(res))
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastai2/data/load.py", line 128, in do_batch
def do_batch(self, b): return self.retain(self.create_batch(self.before_batch(b)), b)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastai2/data/load.py", line 127, in create_batch
def create_batch(self, b): return (fa_collate,fa_convert)[self.prebatched](b)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastai2/data/load.py", line 45, in fa_collate
return (default_collate(t) if isinstance(b, _collate_types)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/torch/utils/data/_utils/collate.py", line 55, in default_collate
return torch.stack(batch, 0, out=out)
RuntimeError: stack expects each tensor to be equal size, but got [4382] at entry 0 and [4065] at entry 1
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "39_tutorial.transformers_DDP.py", line 66, in <module>
runs: Param("Number of times to repeat training", int)=1,
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastscript/core.py", line 76, in call_parse
return _f()
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastscript/core.py", line 73, in _f
func(**args.__dict__)
File "39_tutorial.transformers_DDP.py", line 126, in main
learn.fit_one_cycle(epochs, lr)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/contextlib.py", line 130, in __exit__
self.gen.throw(type, value, traceback)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastai2/distributed.py", line 169, in distrib_ctx
if cleanup_dpg: teardown_distrib()
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastai2/distributed.py", line 65, in teardown_distrib
if torch.distributed.is_initialized(): torch.distributed.destroy_process_group()
KeyboardInterrupt
^CTraceback (most recent call last):
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/subprocess.py", line 1019, in wait
return self._wait(timeout=timeout)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/subprocess.py", line 1653, in _wait
(pid, sts) = self._try_wait(0)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/subprocess.py", line 1611, in _try_wait
(pid, sts) = os.waitpid(self.pid, wait_flags)
KeyboardInterrupt
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastai2/launch.py", line 9, in <module>
args:Param("Args to pass to script", nargs='...', opt=False)=''
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastscript/core.py", line 76, in call_parse
return _f()
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastscript/core.py", line 73, in _f
func(**args.__dict__)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/site-packages/fastai2/launch.py", line 26, in main
for process in processes: process.wait()
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/subprocess.py", line 1032, in wait
self._wait(timeout=sigint_timeout)
File "/mnt/home/pierre/.conda/envs/fastai2/lib/python3.7/subprocess.py", line 1647, in _wait
time.sleep(delay)
KeyboardInterrupt
(fastai2) pierre@tesla:~/fastai2/nbs$