Did you ever fix your specific attribute error 'Learner' object has no attribute 'distrib_ctx'?
I have the exact same issue where only torch.nn.DataParallel(learner.model) works.
1 Like
I had the same issue and resolved it by importing from fastai.distributed import *. Also remember to launch your training script using python -m fastai.launch train.py
The distributed example https://github.com/fastai/fastai/blob/master/nbs/examples/distrib.py is useful for pointing out details missed in the docs.
2 Likes
Thank you. This was my issue ttoo and now its working!
I still have problems with nn.DataParallel(learn.model).
RuntimeError: Input and hidden tensors are not at the same device, found input tensor at cuda:1 and hidden tensor at cuda:0
Which doesn’t make sense because I am trying to run it across 8 GPUs.
I have come to two possibilities.
- My data loader is mismatching with the learner and I need to fix devices. pierreguillou’s example don’t seem to work for me.
- Its just impossible right now. Fastai v2 text - #431 by chess
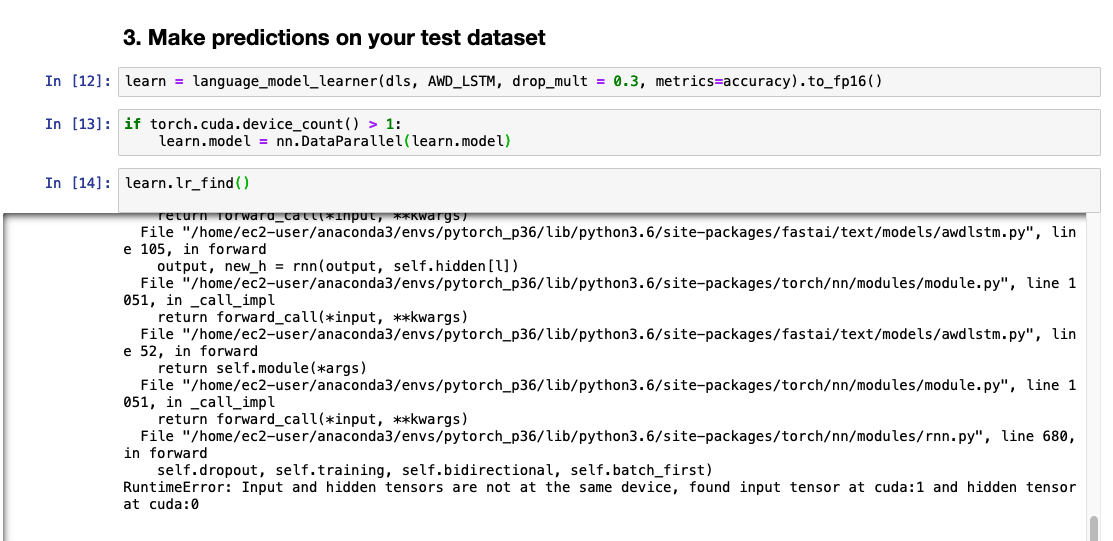
I am also running into this same issue on Sagemaker Studio at the moment on a multi-GPU instance. Did you manage to find a fix for this?
I have a code which runs on all my four gpus (I see it on nvidia-smi). But each epoch takes longer on 4 gpus than in one!
If i run without specifying DataParallel:
learn = vision_learner(dls, resnet152, metrics=error_rate)
learn.fit_one_cycle(n_epoch=1)
epoch train_loss valid_loss error_rate time
0 0.018546 0.014250 0.003585 01:19
With dataparallel
learn = vision_learner(dls, resnet152, metrics=error_rate)
learn.model = torch.nn.DataParallel(learn.model) # send it to all gpus
learn.fit_one_cycle(n_epoch=1)
epoch train_loss valid_loss error_rate time
0.049150 0.033304 0.007547 01:36
What can I be doing wrong?