Data Parallel (DP) and Distributed Data Parallel (DDP) training in Pytorch and fastai v2
For training a Deep Learning model in parallel using PyTorch or fastai v2, there are 2 modes: DataParallel (DP) and Distributed Data Parallel (DDP) but you should use DDP instead of DP (see below for explications).
1. Pytorch | How to train a model across multi-GPUs?
Pytorch | Data Parallel (DP)
nn.DataParallel (DP) is for performing one-process on multiple devices of a single machine .
As an example, it can perform the training of your Deep Learning model (which is a process) by distributing it on many GPUs of a single machine (GPU is a device).
- How? By distributing batches of the training and validation dataloaders on the GPUs available. This is data parallelism at the
modulelevel. - Positive : batch size can be bigger as batches will be equally distributed to all GPUs
- Negative: just-one-process is a bottleneck that can increase process time
This is the official definition from PyTorch:
- This container parallelizes the application of the given
moduleby splitting the input across the specified devices by chunking in the batch dimension (other objects will be copied once per device). In the forward pass, the module is replicated on each device, and each replica handles a portion of the input. During the backwards pass, gradients from each replica are summed into the original module.- The batch size should be larger than the number of GPUs used.
- WARNING: It is recommended to use
DistributedDataParallel, instead of this class, to do multi-GPU training, even if there is only a single node. See: Use nn.parallel.DistributedDataParallel instead of multiprocessing or nn.DataParallel and Distributed Data Parallel.
PyTorch code
You will find the full code of the notebook 05_pet_breeds.ipynb using Data Parallel PyTorch code in my notebook 05_pet_breeds_DataParallel.ipynb (nbviewer version).
The lines chaves are the following ones:
if torch.cuda.device_count() > 1:
learn.model = nn.DataParallel(learn.model)
PyTorch forum
- About Data Parallel and DataParallel
Pytorch | Distributed Data Parallel (DDP)
nn.parallel.DistributedDataParallel (DDP) is useful when you want to perform multi-processes on devices of multiple machines but you can use it on devices of just a single machine as well: differently than DataParallel, within DDP each device (GPU) performs independently one copy of the process on a part of the training dataset (this is true process and data parallelism).
This is the official definition from PyTorch:
- DDP implements distributed data parallelism that is based on
torch.distributedpackage at the module level.- This container parallelizes the application of the given module by splitting the input across the specified devices by chunking in the batch dimension. The module is replicated on each machine and each device, and each such replica handles a portion of the input. During the backwards pass, gradients from each node are averaged.
- The batch size should be larger than the number of GPUs used locally.
- See also: Basics and Use nn.parallel.DistributedDataParallel instead of multiprocessing or nn.DataParallel. The same constraints on input as in
torch.nn.DataParallelapply.- Creation of this class requires that
torch.distributedto be already initialized, by callingtorch.distributed.init_process_group().DistributedDataParallelis proven to be significantly faster thantorch.nn.DataParallelfor single-node multi-GPU data parallel training.
PyTorch forum
PyTorch code
- ImageNet training in PyTorch: this implements training of popular model architectures (file main.py), such as ResNet, AlexNet, and VGG on the ImageNet dataset with multi-processing Distributed Data Parallel Training:
PyTorch tutorials
- Distributed data parallel training in Pytorch
- Motivation: The easiest way to speed up neural network training is to use a GPU, which provides large speedups over CPUs on the types of calculations (matrix multiplies and additions) that are common in neural networks. As the model or dataset gets bigger, one GPU quickly becomes insufficient. For example, big language models such as BERT and GPT-2 are trained on hundreds of GPUs. To multi-GPU training, we must have a way to split the model and data between different GPUs and to coordinate the training.
- Why distributed data parallel?: I like to implement my models in Pytorch because I find it has the best balance between control and ease of use of the major neural-net frameworks. Pytorch has two ways to split models and data across multiple GPUs:
nn.DataParallelandnn.DistributedDataParallel.nn.DataParallelis easier to use (just wrap the model and run your training script). However, because it uses one process to compute the model weights and then distribute them to each GPU during each batch, networking quickly becomes a bottle-neck and GPU utilization is often very low. Furthermore,nn.DataParallelrequires that all the GPUs be on the same node and doesn’t work with Apex for mixed-precision training.
- PyTorch Distributed Training
- PyTorch has relatively simple interface for distributed training. To do distributed training, the model would just have to be wrapped using
DistributedDataParalleland the training script would just have to be launched usingtorch.distributed.launch. Although PyTorch has offered a series of tutorials on distributed training, I found it insufficient or overwhelming to help the beginners to do state-of-the-art PyTorch distributed training. Some key details were missing and the usages of Docker container in distributed training were not mentioned at all. - In this blog post, I would like to present a simple implementation of PyTorch distributed training on CIFAR-10 classification using
DistributedDataParallelwrapped ResNet models. The usage of Docker container for distributed training and how to start distributed training usingtorch.distributed.launchwould also be covered.
- PyTorch has relatively simple interface for distributed training. To do distributed training, the model would just have to be wrapped using
- Getting Started with Distributed Data Parallel
- DistributedDataParallel (DDP) implements data parallelism at the module level which can run across multiple machines. Applications using DDP should spawn multiple processes and create a single DDP instance per process. DDP uses collective communications in the torch.distributed package to synchronize gradients and buffers. More specifically, DDP registers an autograd hook for each parameter given by
model.parameters()and the hook will fire when the corresponding gradient is computed in the backward pass. Then DDP uses that signal to trigger gradient synchronization across processes. Please refer to DDP design note for more details. - The recommended way to use DDP is to spawn one process for each model replica, where a model replica can span multiple devices. DDP processes can be placed on the same machine or across machines, but GPU devices cannot be shared across processes. This tutorial starts from a basic DDP use case and then demonstrates more advanced use cases including checkpointing models and combining DDP with model parallel.
- DistributedDataParallel (DDP) implements data parallelism at the module level which can run across multiple machines. Applications using DDP should spawn multiple processes and create a single DDP instance per process. DDP uses collective communications in the torch.distributed package to synchronize gradients and buffers. More specifically, DDP registers an autograd hook for each parameter given by
- Distributed Data Parallel:
torch.nn.parallel.DistributedDataParallel(DDP) transparently performs distributed data parallel training. This page describes how it works and reveals implementation details.
2. fastai v2 | How to train a model across multi-GPUs?
fastai v2 implements the 2 modes as documented in Distributed and parallel training fastai v2 doc.
fastai v2 | Data Parallel (DP)
This is the simplest one. Use the class functions of the class ParallelTrainer.
You will find the full code of the notebook 05_pet_breeds.ipynb using Data Parallel fastai v2 code in my notebook 05_pet_breeds_DataParallel.ipynb (nbviewer version).
The lines chaves are the following ones:
ctx = learn.parallel_ctx
with partial(ctx, gpu)():
print(f"Training in {ctx.__name__} context on GPU {list(range(n_gpu))}")
learn.fine_tune(2)
fastai v2 | Distributed Data Parallel (DDP)
This is the most fast one as it will train truly in parallel all the model copies (one model copy by GPU). Use the class functions of the class DistributedTrainer.
As you will need to launch at least 2 process in parallel, this can not be done in a Jupyter notebook but in a Terminal via the following command to be run at the script.py path within a fastai v2 virtual environment:
python -m fastai2.launch script.py
with fastai2.launch that refers to launch.py and script.py that contains the DDP formatted training code like the following files in fastai > fastai2 > nbs > examples in github:
- train_imagenette.py (images classification)
- train_imdbclassifier.py (texts classification)
- train_tabular.py (regression)
Notebooks on DDP from fastai v2
I run the following commands at the path of the py files in a Terminal of a server with 2 GPUs NVIDIA V100 32Go within a fastai v2 virtual environment.
1. Images Classification with ImageNette
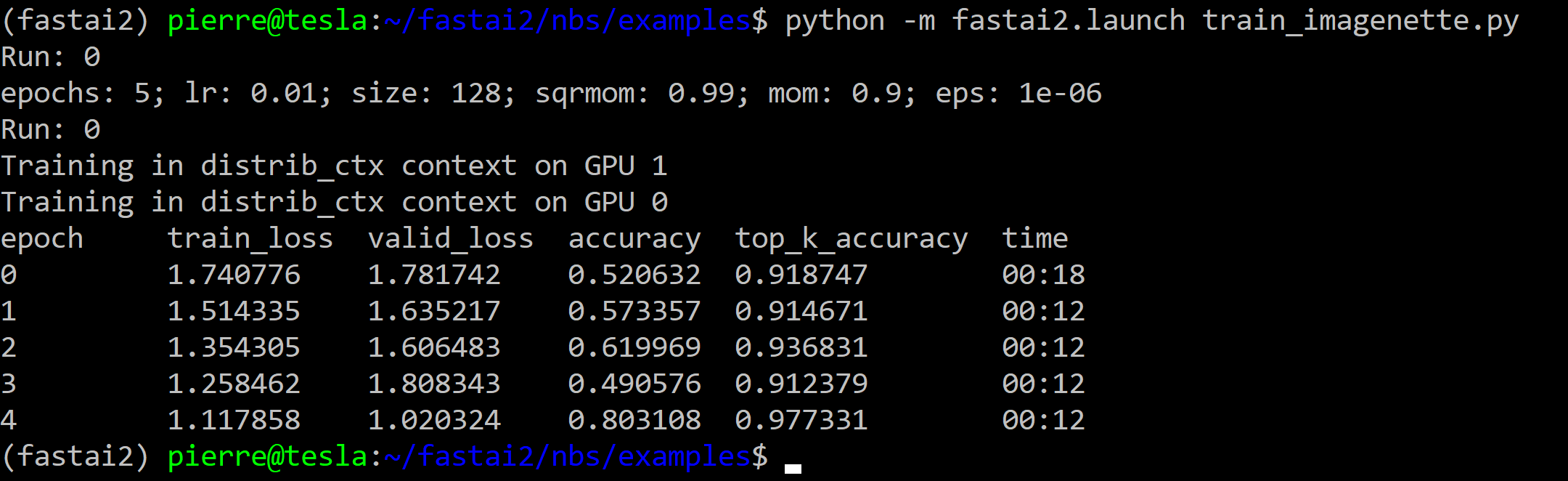
File: train_imagenette.py
python -m fastai2.launch train_imagenette.py
In order to test the train_imagenette.py code with another dataset, I created the file 05_pet_breeds_DDP.py from the notebook 05_pet_breeds.ipynb that ran perfectly with DDP (Distributed Data Parallel) and fastai v2 as I divided by 3 the training and validation time ![]() using the following command:
using the following command:
python -m fastai2.launch 05_pet_breeds_DDP.py
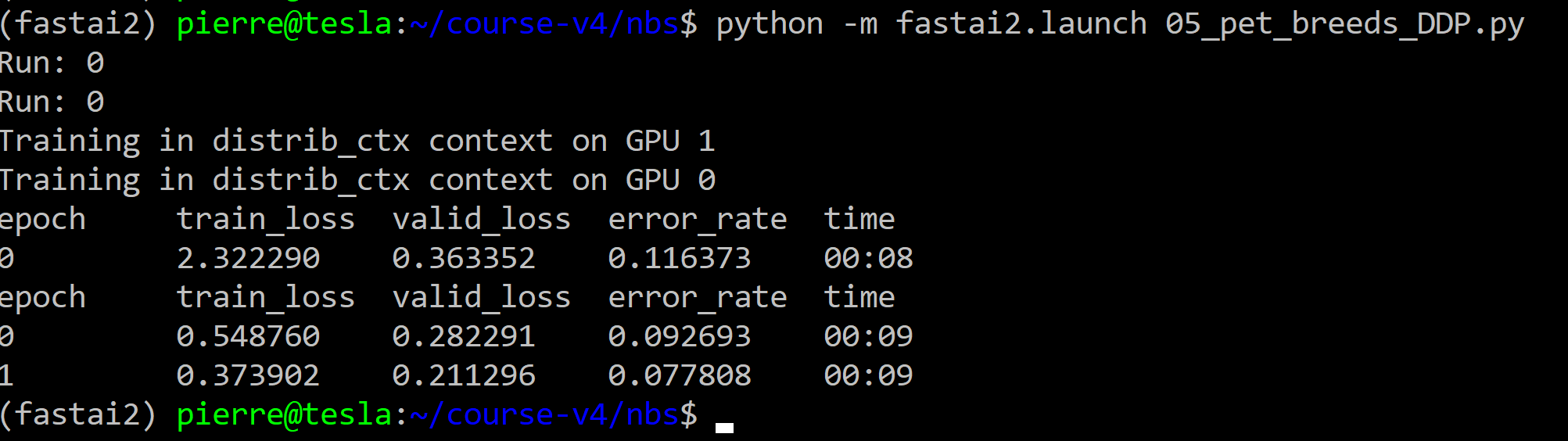
To be compared to the training and validation times values in the notebook 05_pet_breeds.ipynb (just one GPU)…

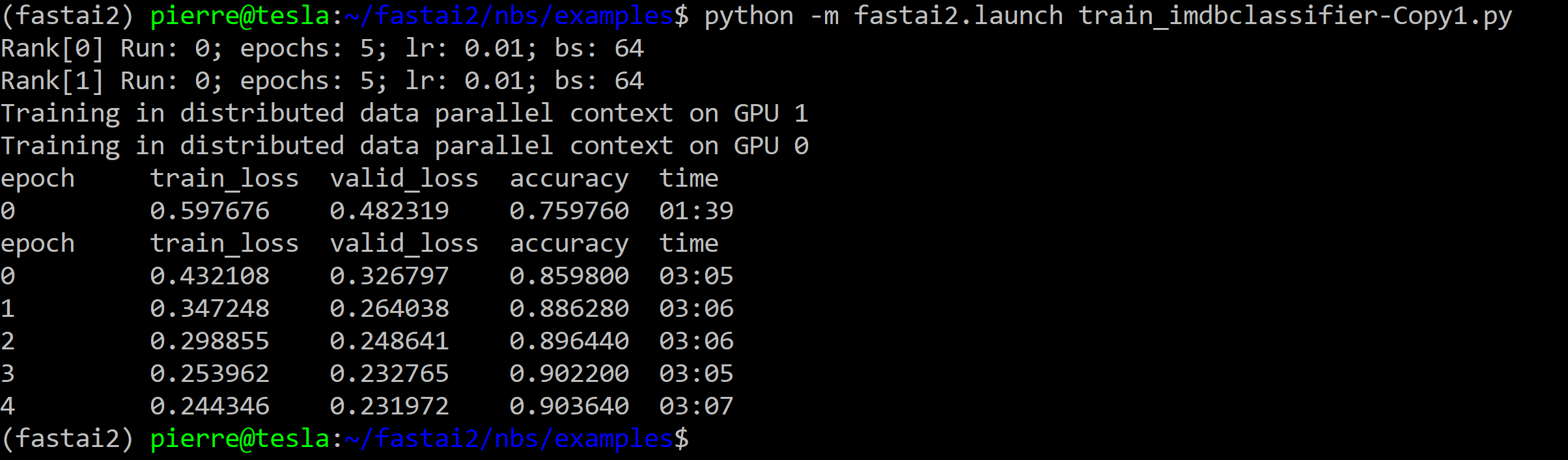
2. Texts Classification with IMDB
File: train_imdbclassifier-Copy1.py (I needed to setup DistributedTrainer.fup = True in the original file train_imdbclassifier.py)
python -m fastai2.launch train_imdbclassifier-Copy1.py
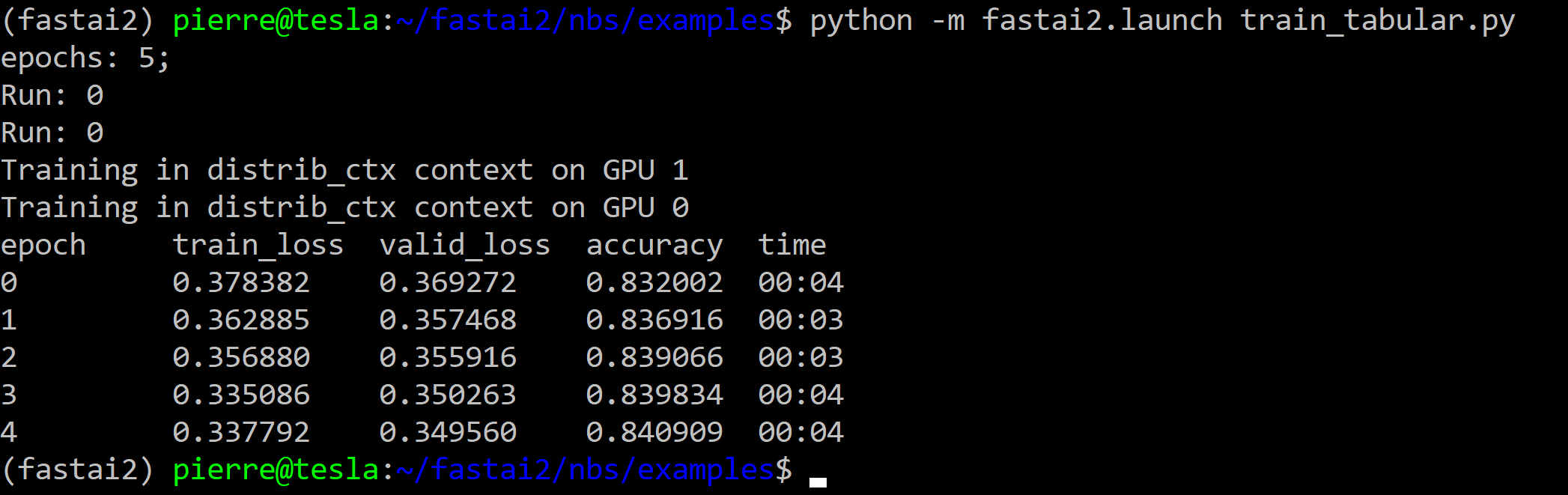
3. Tabular Classification with ADULTS
File: train_tabular.py
python -m fastai2.launch train_tabular.py
Note: when running python -m fastai2.launch script.py, if you get the error store = TCPStore(master_addr, master_port, start_daemon) RuntimeError: Address already in use in the Terminal, just launch the command ps -elf | grep python to get the PIDs of running python zombie processes. Then, you can kill them by PID (ex: kill -9 14275) or by file name (ex: pkill -9 -f script.py).
fastai v2 | Problems not solved with DDP
I wanted to run in DDP the Transformers tutorial using the code from train_imdbclassifier.py but it does not work (see this post).