dear fellow developers: consider grabbing some test scripts
… if I may suggest ![]()
dear fellow developers: consider grabbing some test scripts
… if I may suggest ![]()
Is there a tread to report bugs in, so we can discuss them before submitting a new issue on github?
Or should I create a whole new thread for any detected bugs?
If you think it’s a bug in fastai you can submit it directly as a github issue, but you can also post here about it if you’re not sure.
just a heads up. I have created this issue [https://github.com/fastai/fastai/issues/1378] with ref to a notebook on how to fix the memory overhead in LanguageModelLoader. The proposed version uses less than 5% of the current version. Testing and validation of accuracy on the english corpus is still need.
Would love some feedback
If you call learn.fit twice it will wrap learn.model twice. Not an issue on runtime, but problem if you try save and load model. May I propose unwrap model in the on_train_end method?
What you guys think about this code piece.
def cont_cat_split(df, max_card=20, dep_var=None):
"""
Parameters:
-----------
df: A pandas data frame, that you wish to take columns.
max_card: Maximum cardinality of a continuous variable.
dep_var: A dependent variable.
Returns:
-----------
cont_names: A list of names of continuous variables.
cat_names: A list of names of categorical variables.
Examples:
-----------
>>> df = pd.DataFrame({'col1' : [1, 2, 3], 'col2' : ['a', 'b', 'a'], 'col3' : [0.5, 1.2, 7.5], 'col4' : ['ab', 'ab', 'o']})
>>> df
col1 col2 col3 col4
0 1 a 0.5 ab
1 2 b 1.2 ab
2 3 a 7.5 o
>>> cont_cat_split(df, 20, 'col4')
(['col3'], ['col1', 'col2'])
"""
cont_names, cat_names = [], []
for label in df:
if label == dep_var: continue
if len(set(df[label])) > max_card and df[label].dtype == int or df[label].dtype == float: cont_names.append(label)
else: cat_names.append(label)
return cont_names, cat_names
It is making easier to choose which columns to label as category and which as continuous. I know that sometimes people like to do it by hand but often it is just choosing like this so why not create a function for it. I was thinking that best place might be above add_datepart() in structured.py. Can I create pull request about this or is it too useless?
Oh, good catch!
Yes unwrapping the model at the end is probably the best way to deal with this, and would get us loading and saving for free.
I think it would be a useful addition. If you make a PR, please note that the doc string should just take one line that explains what your function does (with arguments between if they are mentioned). Then edit the doc notebook tabular.transform (since I think this function should go there) and document your new function with more length (no need to list the parameters like you do) then you can show actual examples.
Done! I hope it is good enough for the library.
While Im trying to run the lesson 10 , Im facing issues,
AttributeError: ‘numpy.ndarray’ object has no attribute ‘x’ at this line ,
trn_dl = LanguageModelLoader(np.concatenate(trn_lm), bs, bptt)
And my environment is,
=== Software ===
python : 3.6.6
fastai : 1.0.38
fastprogress : 0.1.18
torch : 1.0.0
torch cuda : 9.0.176 / is **Not available**
=== Hardware ===
No GPUs available
=== Environment ===
platform : Linux-4.4.0-1065-aws-x86_64-with-debian-9.5
distro : Debian GNU/Linux 9 stretch
conda env : Unknown
python : /usr/local/bin/python
sys.path :
/usr/local/lib/python36.zip
/usr/local/lib/python3.6
/usr/local/lib/python3.6/lib-dynload
/usr/local/lib/python3.6/site-packages
/usr/src/app
/usr/local/lib/python3.6/site-packages/IPython/extensions
no supported gpus found on this system
Thanks in advance
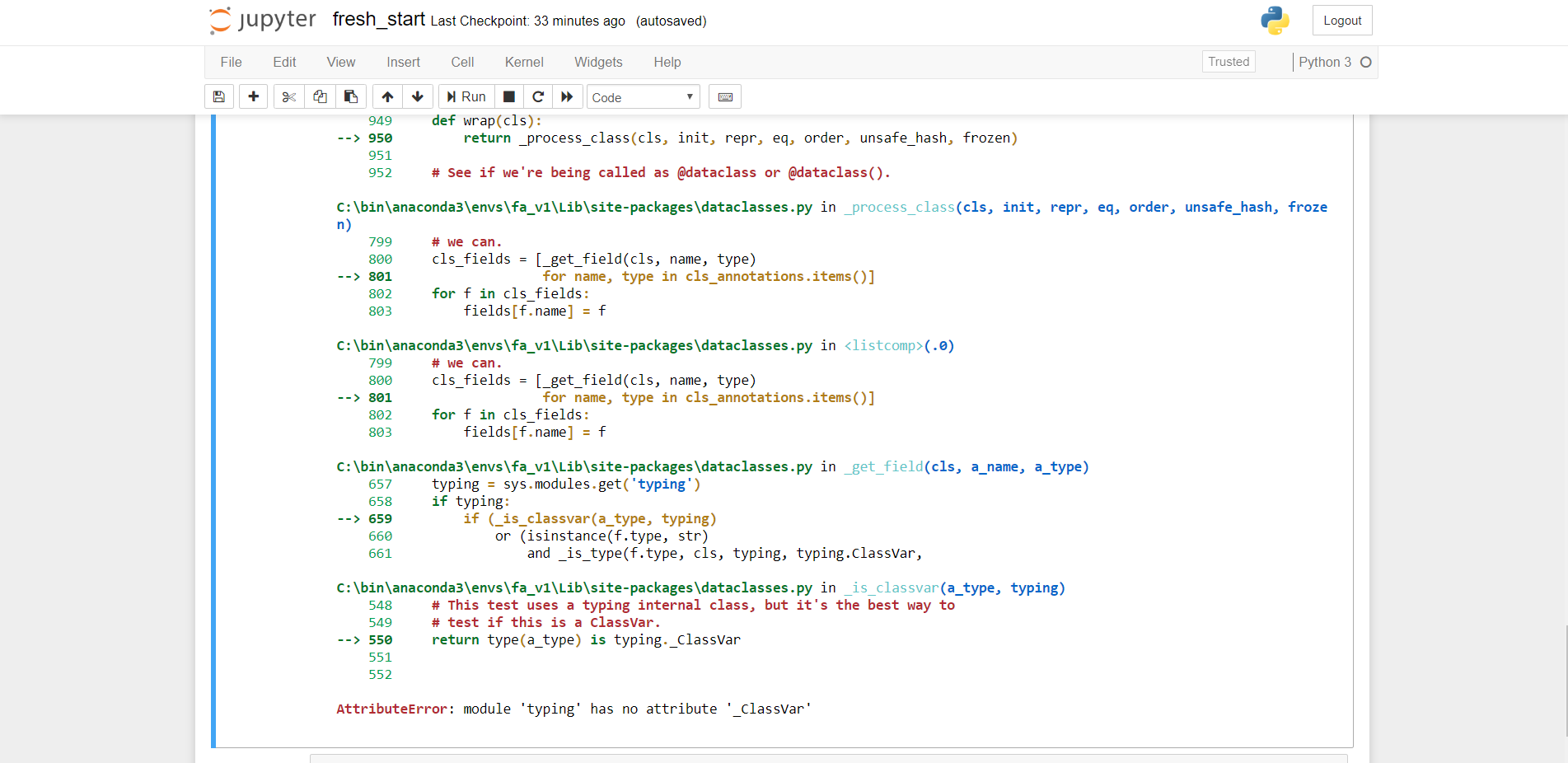
Hello:
After following the install instruction on my laptop, I got the “AttributeError: module ‘typing’ has no attribute ‘_ClassVar’” error
during the “from fastai.vision import *”.
I searched the forum, but couldn’t find any posting relating to this error. Any advice would be greatly appreciated. [include image]
Why do we have get_preds's default ds Valid? Isn’t the main use for get_preds is with the test set?
So currently we need to use:
predictions = learn.get_preds(ds_type=DatasetType.Test)
to do that. Yuck. At least perhaps having a thin wrapper?
predictions = learn.get_preds_for_test()
And then there is an issue with docs which currently don’t show any default value. It looks like a bug in show_doc, all the methods below it have the same issue, showing: ds_type = ``
https://docs.fast.ai/basic_train.html#Learner.get_preds
Hi guys,
Based on Jeremy lesson 6 pet nb I wrote a class to simplify the process of plotting Gradcam (optionally with guided backprop based on the Gradcam paper). I think it would be a nice complement to the ClassificationInterpretation and to deep learning model’s interpretation in general
The post is originally here https://forums.fast.ai/t/gradcam-and-guided-backprop-intergration-in-fastai-library/33462 and I am not sure how to move it to fastai dev topic…
Anyway I hope this is helpful and if there’s a way to add this to fastai let me know. I’d love to contribute this to the code base.
You just saved me hours of debugging ![]() , as we are overwriting the language model loader to create batches for bi-directional training, and everything was working except that the results were random.
, as we are overwriting the language model loader to create batches for bi-directional training, and everything was working except that the results were random.
Thank you! ![]()
I’m doing distributed training on 4 machines with 8 GPUs each. Validation part of .fit() loop takes more time than anything else combined. I believe that is because there is no distributed inference. Is anybody working on that ATM?
Hi all, I have started working with some medical imaging. I have made some custom ItemLists for this 3d volumes and segmentation volumes, and I would like to share the work, but I’m wondering what is the common format for this kind of elements. Right now what I did is to build some bcolz carrays to store the datasets and my ItemLists are working in top of that (I have some limitations like num_workers=0). What do you recommend?
We make a github repro with the code/notebook and publish a link here: https://forums.fast.ai/t/share-your-work-here/27676
I’m not sure I understand the problem. Validation is done on the full dataset for each GPU, just so the stats printed are correct, but if this is taking that long, maybe reduce your validation set? There is no need to have a huge one.
I’ve used 80/20 training/validation split, so it wasn’t that huge. It takes a lot of time because fitting is fast in distributed environment. I’ve reduced the validation set and now it is doing ok. Distributed inference is not a real problem but a nice thing to have, Pytorch dev will implement it some day hopefully https://github.com/pytorch/examples/issues/461
Oh, no. I’ve started to train the bigger images and there is a problem with validation phase. I’m receiving “CUDA out of memory” on the validation phase of the loop. I can’t fix that by reducing the size of the validation set. I’ve already set batch size to 2, doesn’t help at all. The forward pass works nice even with batch size = 16.