Unofficial Deep Learning Lecture 2 Notes
Hi All,
Here’s my lecture 2 notes. Hope it’s useful.
Part 1: Overview of Dogs vs. Cats Image Recognition
Resources mainly from lesson 1 from the GitHub repository.
# Put these at the top of every notebook, to get automatic reloading and inline plotting
%reload_ext autoreload
%autoreload 2
%matplotlib inline
import torch
from fastai.imports import *
from fastai.transforms import *
from fastai.conv_learner import *
from fastai.model import *
from fastai.dataset import *
from fastai.sgdr import *
from fastai.plots import *
Opening
Recap: we made a simple classifier last week with dogs and cats.
How do we tune these neural networks? Learning rate. Practice. Epoch number.
Sample Code
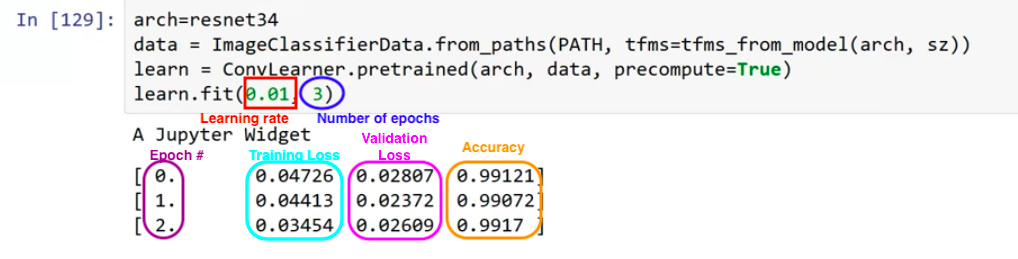
arch=resnet34
data = ImageClassifierData.from_paths(PATH, tfms=tfms_from_model(arch, sz))
learn = ConvLearner.pretrained(arch, data, precompute=True)
learn.fit(0.01, 3)
Output
A Jupyter Widget
[ 0. 0.04726 0.02807 0.99121]
[ 1. 0.04413 0.02372 0.99072]
[ 2. 0.03454 0.02609 0.9917 ]
PATH = "/home/paperspace/Desktop/data/dogscats/"
sz=224
arch=resnet34
data = ImageClassifierData.from_paths(PATH, tfms=tfms_from_model(arch, sz))
learn = ConvLearner.pretrained(arch, data, precompute=True)
learn.fit(0.01, 3)
A Jupyter Widget
[ 0. 0.04247 0.02314 0.9917 ]
[ 1. 0.03443 0.02482 0.98877]
[ 2. 0.03072 0.02676 0.98975]
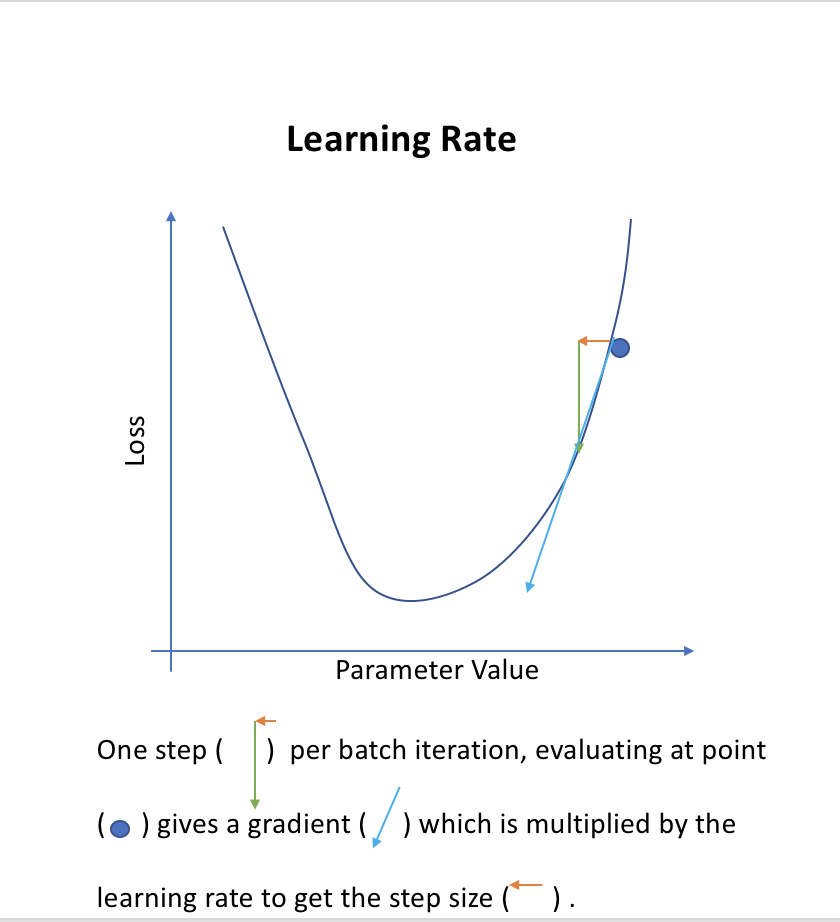
Choosing a learning rate
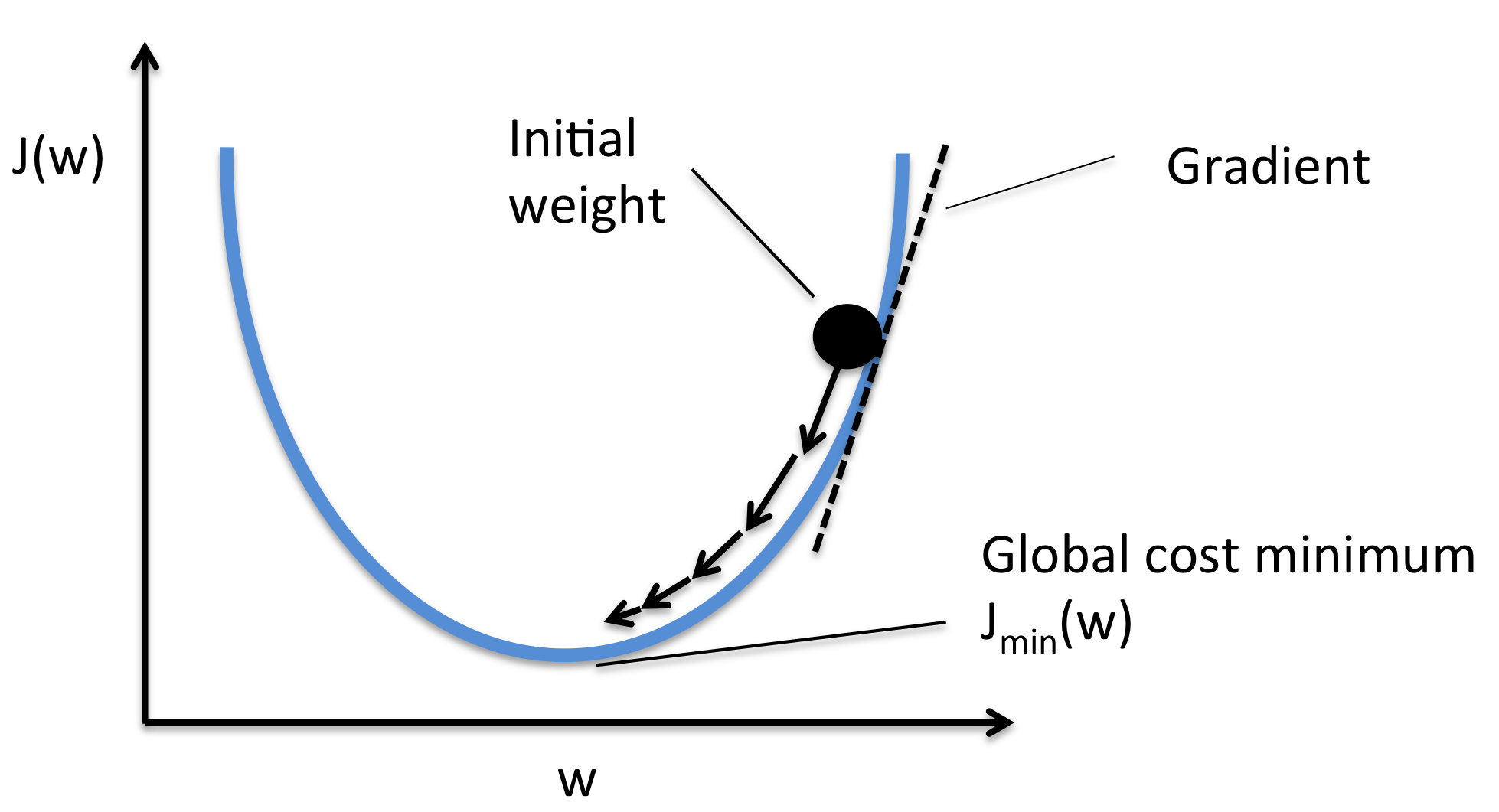
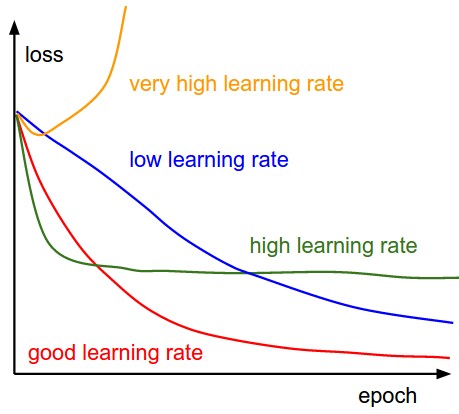
The thing that most determines how we are going to zoom in or hone in on the solution. Where is the “minimum point”. How do you find the minimum point?
If i was a computer algorithm, how do i found the minimum. The learning rate is how big of a jump that we will advance (the size of the arrow in the image below).
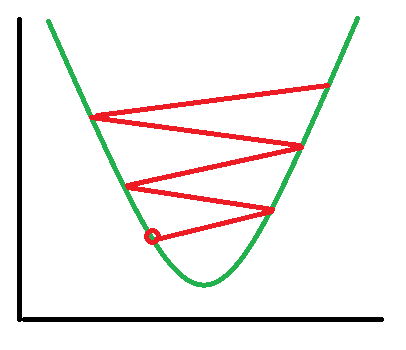
If your learning rate is too high:
Learning rate finder
learn = ConvLearner.pretrained(arch, data, precompute=True)
This is a custom function.
The ConvLearner Class
def __init__(self, data, models, precompute=False, **kwargs):
self.precompute = False
super().__init__(data, models, **kwargs)
self.crit = F.binary_cross_entropy if data.is_multi else F.nll_loss
if data.is_reg: self.crit = F.l1_loss
elif self.metrics is None:
self.metrics = [accuracy_multi] if self.data.is_multi else [accuracy]
if precompute: self.save_fc1()
self.freeze()
self.precompute = precompute
@classmethod
def pretrained(self, f, data, ps=None, xtra_fc=None, xtra_cut=0, **kwargs):
models = ConvnetBuilder(f, data.c, data.is_multi, data.is_reg, ps=ps, xtra_fc=xtra_fc, xtra_cut=xtra_cut)
return self(data, models, **kwargs)
@property
def model(self): return self.models.fc_model if self.precompute else self.models.model
@property
def data(self): return self.fc_data if self.precompute else self.data_
def create_empty_bcolz(self, n, name):
return bcolz.carray(np.zeros((0,n), np.float32), chunklen=1, mode='w', rootdir=name)
def set_data(self, data):
super().set_data(data)
self.save_fc1()
self.freeze()
def get_layer_groups(self):
return self.models.get_layer_groups(self.precompute)
def get_activations(self, force=False):
tmpl = f'_{self.models.name}_{self.data.sz}.bc'
# TODO: Somehow check that directory names haven't changed (e.g. added test set)
names = [os.path.join(self.tmp_path, p+tmpl) for p in ('x_act', 'x_act_val', 'x_act_test')]
if os.path.exists(names[0]) and not force:
self.activations = [bcolz.open(p) for p in names]
else:
self.activations = [self.create_empty_bcolz(self.models.nf,n) for n in names]
def save_fc1(self):
self.get_activations()
act, val_act, test_act = self.activations
if len(self.activations[0])==0:
m=self.models.top_model
predict_to_bcolz(m, self.data.fix_dl, act)
predict_to_bcolz(m, self.data.val_dl, val_act)
if self.data.test_dl: predict_to_bcolz(m, self.data.test_dl, test_act)
self.fc_data = ImageClassifierData.from_arrays(self.data.path,
(act, self.data.trn_y), (val_act, self.data.val_y), self.data.bs, classes=self.data.classes,
test = test_act if self.data.test_dl else None, num_workers=8)
def freeze(self): self.freeze_to(-self.models.n_fc)
What the Fastai library does:
- uses the Adam optimizer
- tries to find the fastest way to converge to a solution.
Best thing to do for your model is get more data:
Problem: models will eventually start memorizing answers, this is called overfitting. Ideally more data will prevent this occurrence. There’s other techniques to assist with gathering more data.
Data augmentation (from lesson 1)
If you try training for more epochs, you’ll notice that we start to overfit, which means that our model is learning to recognize the specific images in the training set, rather than generalizing such that we also get good results on the validation set. One way to fix this is to effectively create more data, through data augmentation. This refers to randomly changing the images in ways that shouldn’t impact their interpretation, such as horizontal flipping, zooming, and rotating.
We can do this by passing aug_tfms (augmentation transforms) to tfms_from_model, with a list of functions to apply that randomly change the image however we wish. For photos that are largely taken from the side (e.g. most photos of dogs and cats, as opposed to photos taken from the top down, such as satellite imagery) we can use the pre-defined list of functions transforms_side_on. We can also specify random zooming of images up to specified scale by adding the max_zoom parameter.
Transformations library
We can use the available options to change the zoom, rotate and shift variations.
tfms = tfms_from_model(resnet34,
sz,
aug_tfms=transforms_side_on,
max_zoom=1.1)
def get_augs():
data = ImageClassifierData.from_paths(PATH, bs=2, tfms=tfms, num_workers=1)
x,_ = next(iter(data.aug_dl))
return data.trn_ds.denorm(x)[1]
ims = np.stack([get_augs() for i in range(6)])
plots(ims, rows=2)
Other Options
transforms_side_on
transforms_top_down

Why do we use the learning rate that isn’t the lowest point?
Each time we iterate, we will double the learning rate. The purpose of this to find what learning rate is helping use to decrease quickly. The learning rate is going too high.
Comment: this augmentation won’t doing anything because of precompute
Note, we are using a pretrained network. We can take the 2nd last layer and save those activations. There is this level of “dog space” “eyeballs” etc. We save these and call these pre-computed activations.
Activations - is a number. This feature is in this location with this level of confidence and probability
Making a new classifier from precompute
We can quickly train a simple linear model based on these saved precomputed numbers. So the first time you run a model, it will take some time to calculate and compile. Then afterwards, it will train much faster.
data = ImageClassifierData.from_paths(PATH, tfms=tfms)
learn = ConvLearner.pretrained(arch, data, precompute=True)
learn.fit(1e-2, 1)
[ 0. 0.04783 0.02601 0.99023]
Since we have precomputed the different cat pictures don’t help. So we will turn it off.
By default when we create a learner, it sets all but the last layer to frozen. That means that it’s still only updating the weights in the last layer when we call fit.
learn.precompute=False
learn.fit(1e-2, 3, cycle_len=1)
[ 0. 0.0472 0.0243 0.99121]
[ 1. 0.04335 0.02358 0.99072]
[ 2. 0.04403 0.0229 0.99219]
Cycle Length = 1
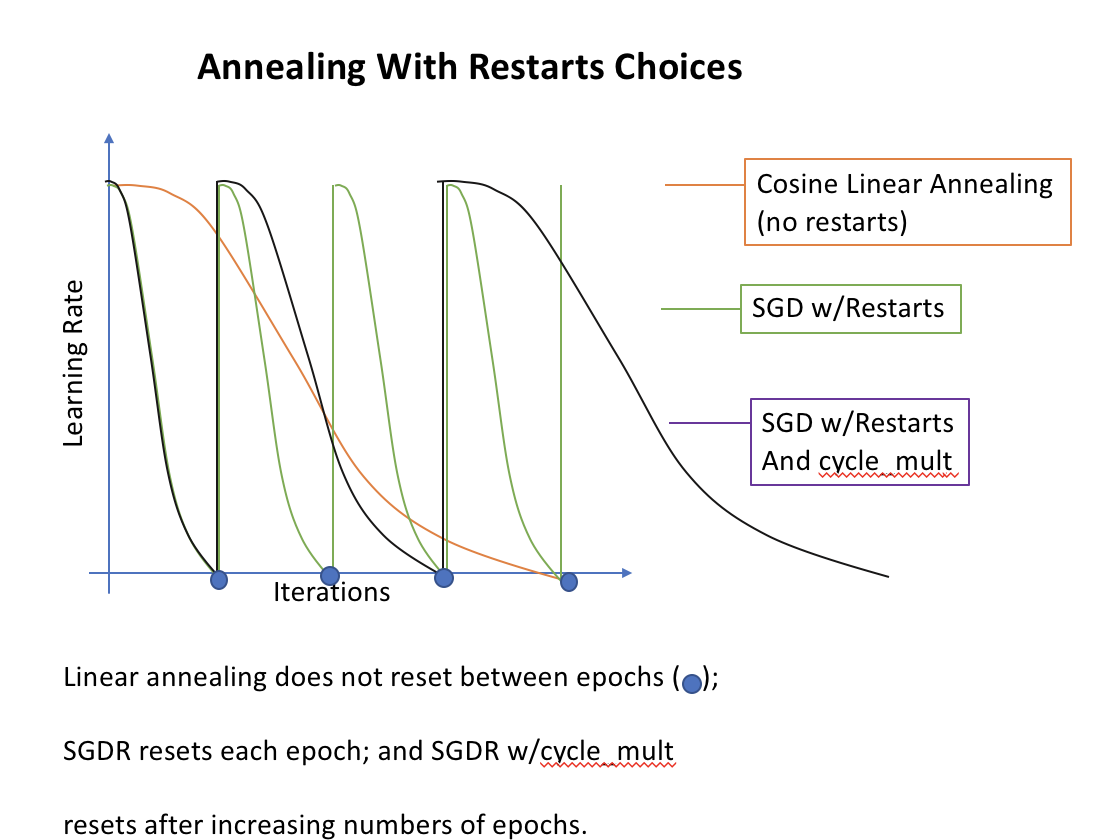
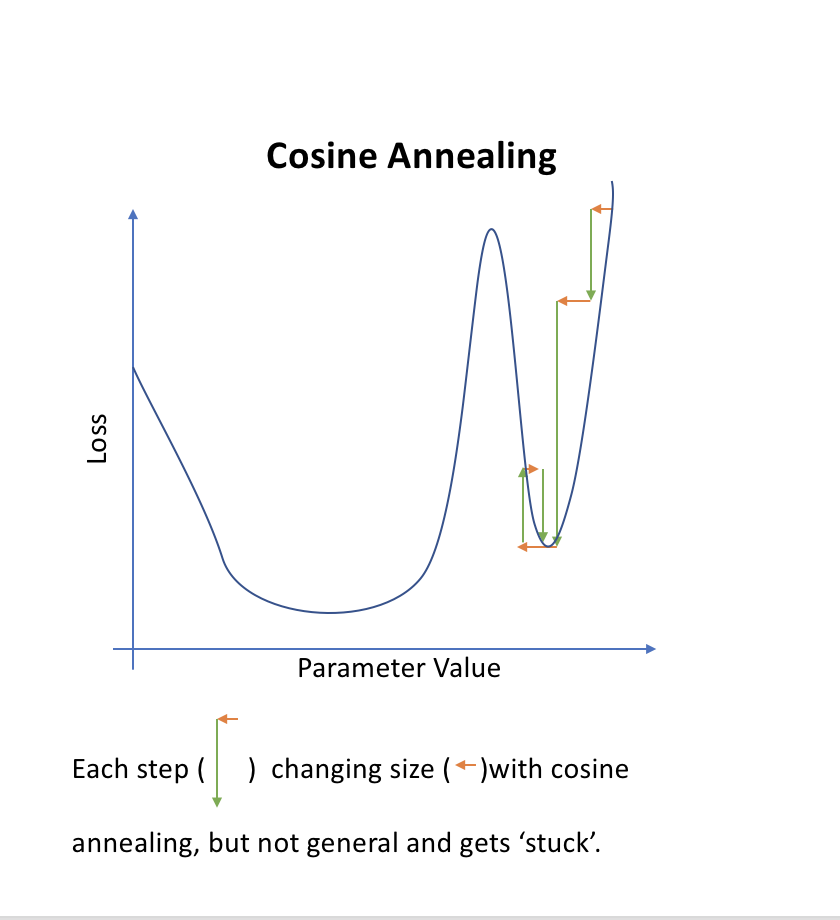
As we get closer, we may want to decrease the learning rate to get a more precise. Also known as annealing.
Most common annealing:
Pick a rate, then drop it 10x, then drop again. Stepwise, very manual. A simpler approach is to choose a functional form such as a line. Turns out that half a cosine curve works out well.
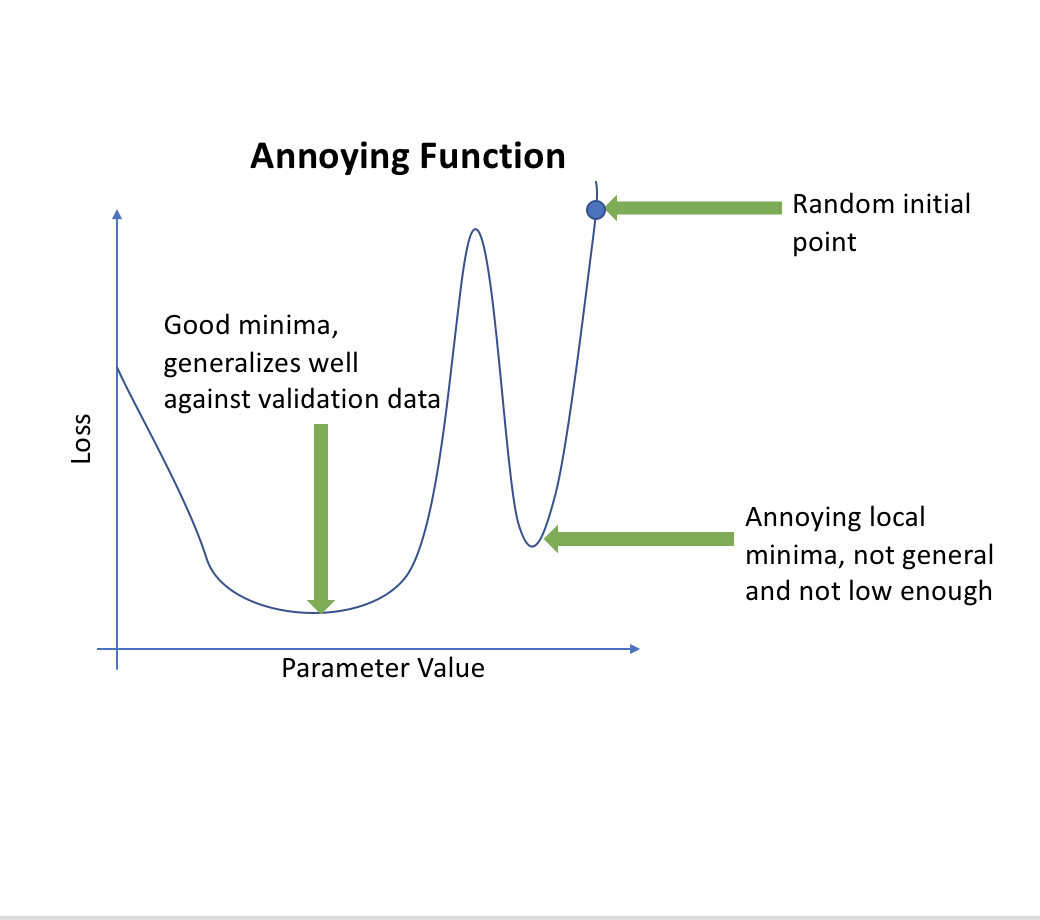
What do you do when you have more than one minima?
Sometimes one minima will be better than others (based on how well it generalizes). So sharply changing the learning rate has the idea that if we suddenly jump up the learning rate, we will get out of “narrow” minimum and find the most “generalized” minimum.
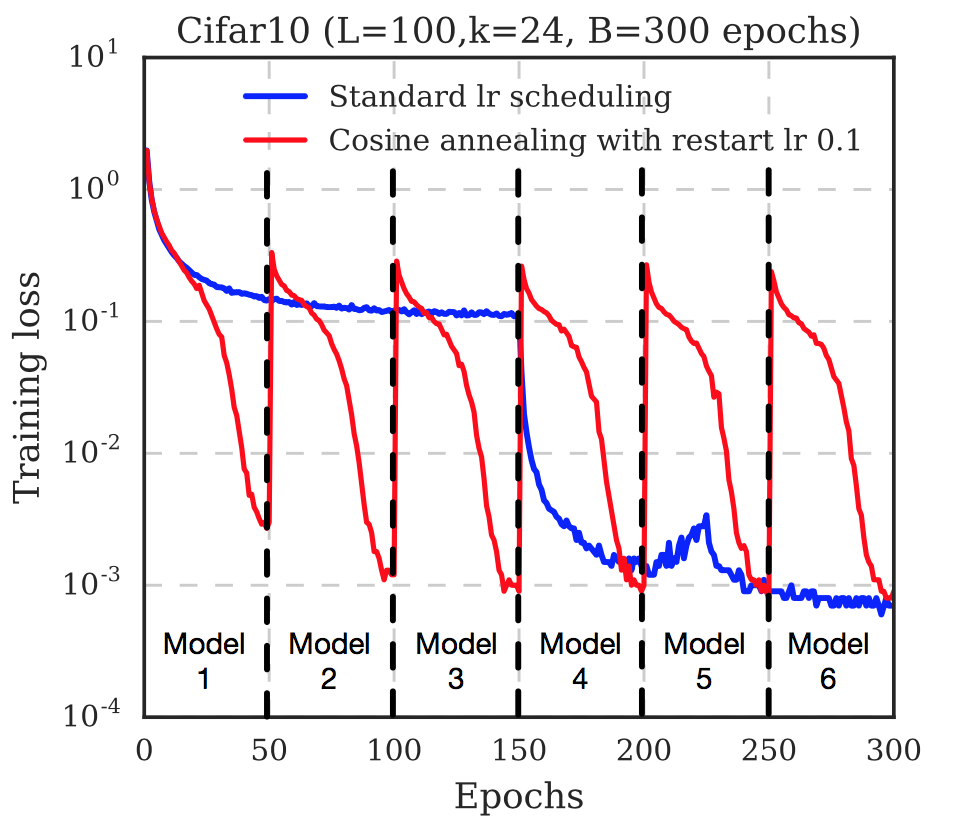
Note that annealing is not necessarily the same as restarts
We are not starting from scratch each time, but we are ‘jumping’ a bit to ensure we are in the best minima.
From the lesson 2 notebook:
What is that cycle_len parameter? What we’ve done here is used a technique called stochastic gradient descent with restarts (SGDR), a variant of learning rate annealing, which gradually decreases the learning rate as training progresses. This is helpful because as we get closer to the optimal weights, we want to take smaller steps.
However, we may find ourselves in a part of the weight space that isn’t very resilient - that is, small changes to the weights may result in big changes to the loss. We want to encourage our model to find parts of the weight space that are both accurate and stable. Therefore, from time to time we increase the learning rate (this is the ‘restarts’ in ‘SGDR’), which will force the model to jump to a different part of the weight space if the current area is “spiky”. Here’s a picture of how that might look if we reset the learning rates 3 times (in this paper they call it a “cyclic LR schedule”):
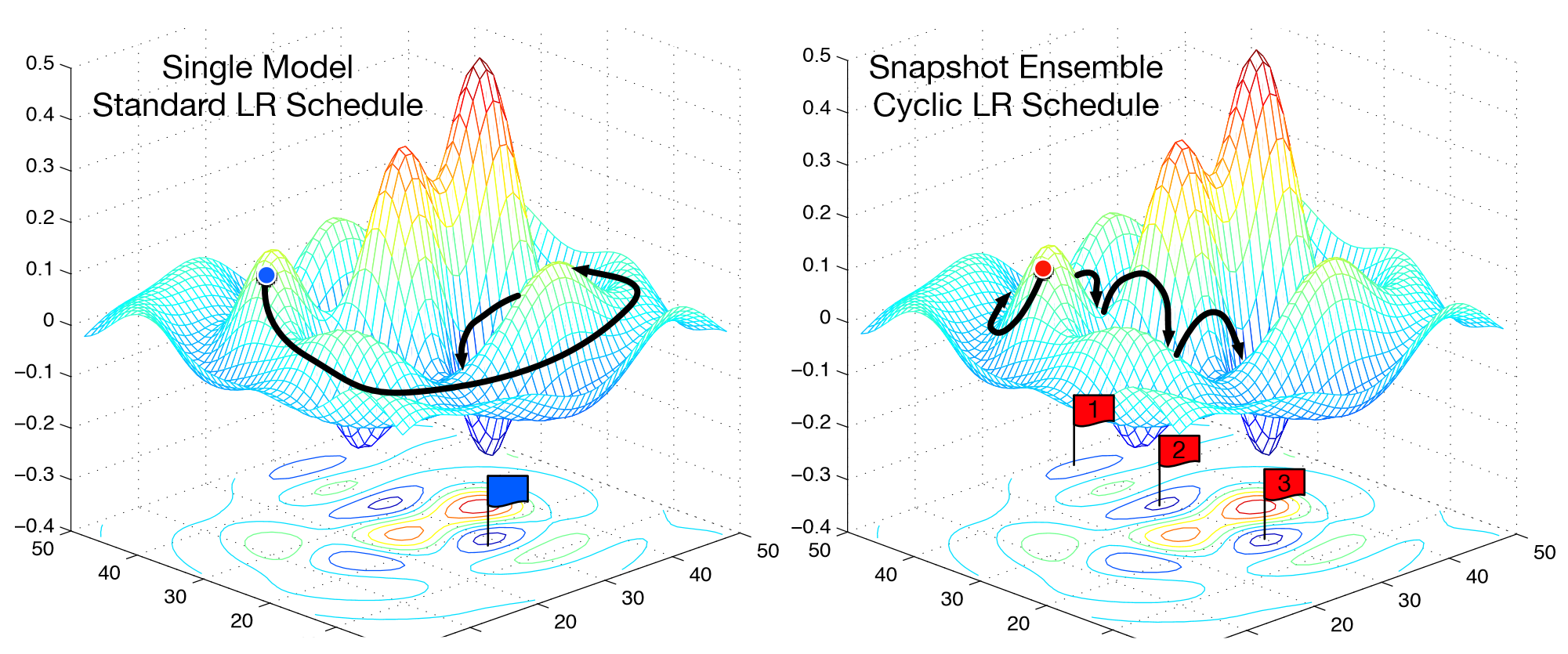
(From the paper Snapshot Ensembles).
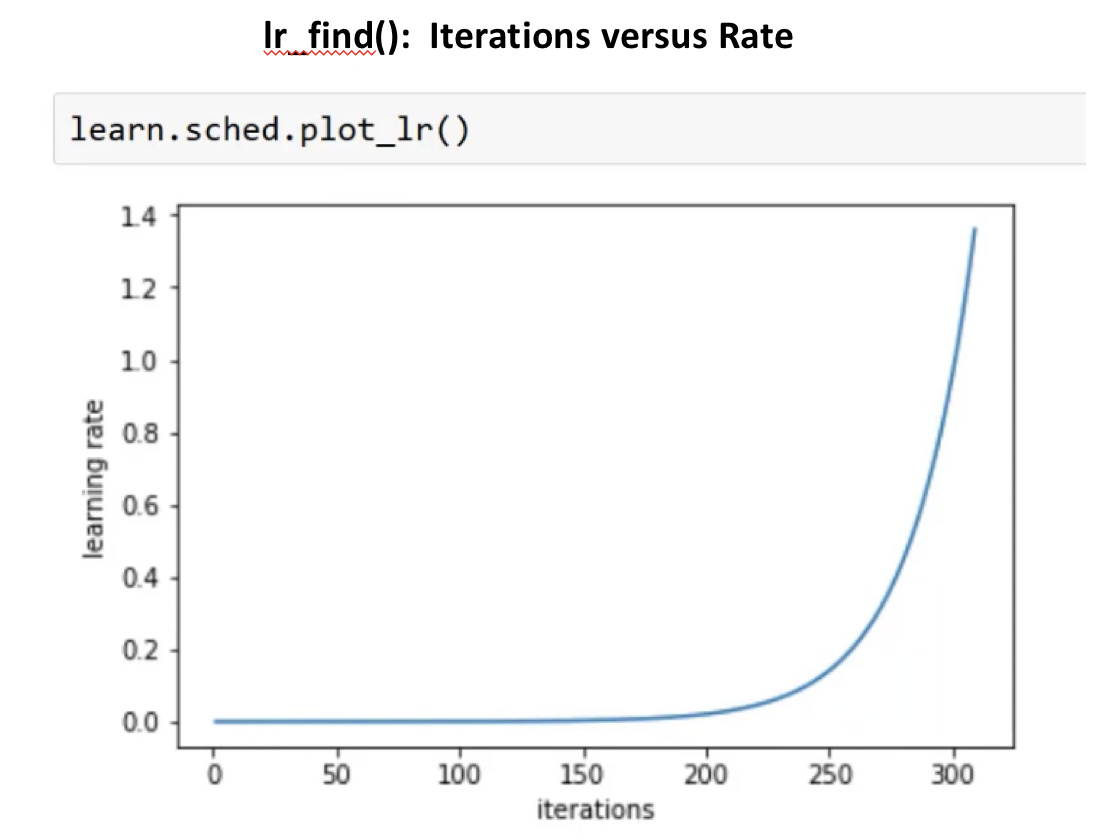
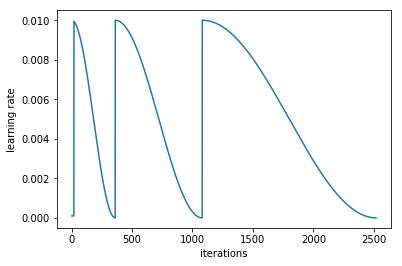
The number of epochs between resetting the learning rate is set by cycle_len, and the number of times this happens is referred to as the number of cycles, and is what we’re actually passing as the 2nd parameter to fit(). So here’s what our actual learning rates looked like:
learn.sched.plot_lr()
Good Tip: Save your weights as you go!
learn.save('224_lastlayer')
Fine-tuning and differential learning rate annealing
Now that we have a good final layer trained, we can try fine-tuning the other layers. To tell the learner that we want to unfreeze the remaining layers, just call (surprise surprise!) unfreeze().
learn.unfreeze()
In general you can only freeze layer from ‘n’ and on
Note that the other layers have already been trained to recognize ImageNet photos (whereas our final layers where randomly initialized), so we want to be careful of not destroying the carefully tuned weights that are already there.
Generally speaking, the earlier layers (as we’ve seen) have more general-purpose features. Therefore we would expect them to need less fine-tuning for new datasets. For this reason we will use different learning rates for different layers: the first few layers will be at 1e-4, the middle layers at 1e-3, and our Fully Connected (FC) layers we’ll leave at 1e-2 as before. We refer to this as differential learning rates, although there’s no standard name for this technique in the literature that we’re aware of.
Specifying learning rates
We are going to specify ‘differential learning rates’ for different layers. We are grouping the blocks (ResNet blocks) in different areas and assigning different learning rates.
Reminder: we unfroze the layers and now we are retraining the whole set. The learning rate is smaller for early layers and making them larger for the ones farther away.
lr=np.array([1e-4,1e-3,1e-2])
# 3 is the number of cycles
# 3 cycles of 2 epochs
learn.fit(lr, 3, cycle_len=1, cycle_mult=2)
[ 0. 0.04913 0.02252 0.99268]
[ 1. 0.04842 0.02123 0.99219]
[ 2. 0.03309 0.02412 0.99121]
[ 3. 0.03528 0.02148 0.99072]
[ 4. 0.02364 0.02106 0.99023]
[ 5. 0.01987 0.01931 0.9917 ]
[ 6. 0.01994 0.02058 0.99121]
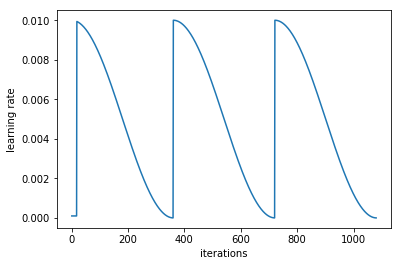
cycle_mult parameter
It doubles the length of the cycle after each cycle.
Another trick we’ve used here is adding the cycle_mult parameter. Take a look at the following chart, and see if you can figure out what the parameter is doing:
learn.sched.plot_lr()

At this point, we are going to look back at incorrect pictures
We are going to do. Use test time augmentation we are going to take 4 random data augmentation. Move them around and flip and mix with the prediction. We are going to average all the predictions of the original + permutation. Ideally the rotating + zoom will get it in the right orientation.
Test-Time-Augmentation (TTA)
TTA makes predictions not only on the originals but also on the random augmented generated.
log_preds,y = learn.TTA()
accuracy(log_preds,y)
0.99199999999999999
Part 2: Dog Breeds Walkthrough
Overview of the Steps
- Enable data augmentation, and precompute=True
- Use
lr_find()to find highest learning rate where loss is still clearly improving - Train last layer from precomputed activations for 1-2 epochs
- Train last layer with data augmentation (i.e. precompute=False) for 2-3 epochs with
cycle_len=1 - Unfreeze all layers
- Set earlier layers to 3x-10x lower learning rate than next higher layer
- Use
lr_find()again - Train full network with
cycle_mult=2until over-fitting
Dog Breeds
PATH = '/home/paperspace/Desktop/data/dogbreeds/'
# Put these at the top of every notebook, to get automatic reloading and inline plotting
%reload_ext autoreload
%autoreload 2
%matplotlib inline
import torch
from fastai.imports import *
from fastai.transforms import *
from fastai.conv_learner import *
from fastai.model import *
from fastai.dataset import *
from fastai.sgdr import *
from fastai.plots import *
sz=224
arch=resnet34
bs=24
label_csv = f'{PATH}labels.csv'
#list of rows, minus 1, nubmer of rows in CSV, number of imgs
n = len(list(open(label_csv)))-1
# get crossvalidation indexes custom FASTAI
val_idxs = get_cv_idxs(n)
n
10222
val_idxs
array([3694, 1573, 6281, ..., 5734, 5191, 5390])
Will get 20% of the data will be in the validation set
??get_cv_idxs
def get_cv_idxs(n, cv_idx=4, val_pct=0.2, seed=42):
np.random.seed(seed)
n_val = int(val_pct*n)
idx_start = cv_idx*n_val
idxs = np.random.permutation(n)
return idxs[idx_start:idx_start+n_val]
The data can be downloaded via the Kaggle CLI
Initial Exploration
!ls {PATH}
labels.csv sample_submission.csv.zip test.zip train
labels.csv.zip test tmp train.zip
label_df = pd.read_csv(label_csv)
label_df.head()
| id | breed | |
|---|---|---|
| 0 | 000bec180eb18c7604dcecc8fe0dba07 | boston_bull |
| 1 | 001513dfcb2ffafc82cccf4d8bbaba97 | dingo |
| 2 | 001cdf01b096e06d78e9e5112d419397 | pekinese |
| 3 | 00214f311d5d2247d5dfe4fe24b2303d | bluetick |
| 4 | 0021f9ceb3235effd7fcde7f7538ed62 | golden_retriever |
label_df.pivot_table(index='breed', aggfunc=len).sort_values('id', ascending=False)[:10]
| id | |
|---|---|
| breed | |
| scottish_deerhound | 126 |
| maltese_dog | 117 |
| afghan_hound | 116 |
| entlebucher | 115 |
| bernese_mountain_dog | 114 |
| shih-tzu | 112 |
| great_pyrenees | 111 |
| pomeranian | 111 |
| basenji | 110 |
| samoyed | 109 |
tfms = tfms_from_model(arch, sz, aug_tfms=transforms_side_on, max_zoom=1.1)
data = ImageClassifierData.from_csv(PATH, 'train' ,f'{PATH}labels.csv', test_name='test', val_idxs=val_idxs, suffix='.jpg', tfms=tfms, bs=bs)
fn = PATH + data.trn_ds.fnames[0]; fn
'/home/paperspace/Desktop/data/dogbreeds/train/000bec180eb18c7604dcecc8fe0dba07.jpg'
img = PIL.Image.open(fn); img

img.size
(500, 375)
How big are the images?
Most ImageNet models are trained on 224 x 224 or 299 x 299. Lets make a dictionary comprehension to store all the names of the files to the size of the files. This will be important for memory and size consideration.
size_d = {k: PIL.Image.open(PATH+k).size for k in data.trn_ds.fnames}
row_sz, col_sz = list(zip(*size_d.values()))
row_sz = np.array(row_sz); col_sz=np.array(col_sz)
row_sz[:5]
array([500, 500, 400, 500, 231])
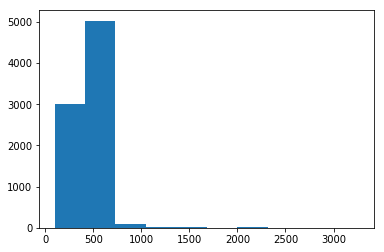
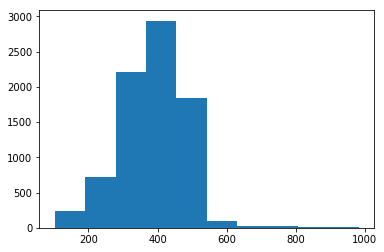
Let’s look at the distribution of the Image Sizes (rows first)
Most of them are under 1000, so we will use NumPy to filter.
plt.hist(row_sz)
(array([ 3014., 5029., 91., 12., 8., 3., 17., 1., 1., 2.]),
array([ 97. , 413.7, 730.4, 1047.1, 1363.8, 1680.5, 1997.2, 2313.9, 2630.6, 2947.3, 3264. ]),
<a list of 10 Patch objects>)
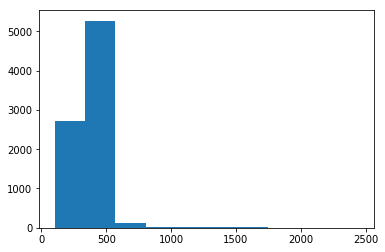
plt.hist(row_sz[row_sz<1000])
(array([ 148., 600., 1307., 1205., 4581., 122., 78., 62., 15., 7.]),
array([ 97. , 186.3, 275.6, 364.9, 454.2, 543.5, 632.8, 722.1, 811.4, 900.7, 990. ]),
<a list of 10 Patch objects>)
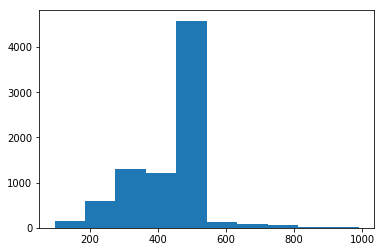
Let’s look at the distribution of the Image Sizes (cols)
plt.hist(col_sz)
(array([ 2713., 5267., 131., 21., 15., 8., 17., 4., 0., 2.]),
array([ 102. , 336.6, 571.2, 805.8, 1040.4, 1275. , 1509.6, 1744.2, 1978.8, 2213.4, 2448. ]),
<a list of 10 Patch objects>)
plt.hist(col_sz[col_sz<1000])
(array([ 243., 721., 2218., 2940., 1837., 95., 29., 29., 8., 8.]),
array([ 102. , 190.2, 278.4, 366.6, 454.8, 543. , 631.2, 719.4, 807.6, 895.8, 984. ]),
<a list of 10 Patch objects>)
Let’s look at the classes
len(data.trn_ds), len(data.test_ds)
(8178, 10357)
len(data.classes), data.classes[:5]
(120,
['affenpinscher',
'afghan_hound',
'african_hunting_dog',
'airedale',
'american_staffordshire_terrier'])
Initial Model
def get_data(sz, bs):
tfms = tfms_from_model(arch, sz, aug_tfms=transforms_side_on, max_zoom=1.1)
data = ImageClassifierData.from_csv(PATH, 'train' ,f'{PATH}labels.csv', test_name='test', val_idxs=val_idxs, suffix='.jpg', tfms=tfms, bs=bs)
return data if sz > 300 else data.resize(340, 'tmp')
Precompute
data = get_data(sz,bs)
Used ResNet34 since ResNext didn’t load for some errors
learn = ConvLearner.pretrained(arch,data, precompute=True, ps=0.5)
0%|===================================>| 0/341 [00:00<?, ?it/s]
learn.fit(1e-2,2)
Do a few more cycles, more epochs
Epoch - 1 pass through the data.
Cycle - is how many epoches in a full cycle.
offline - tried to find the learning rate
learn.precompute=False
learn.fit(1e-2, 5, cycle_len =1)
Can continue training on larger images after starting on smaller images
Started with 224 x 224, and continuing with 299 x 299. Will start small then move to larger general images to limit the overfitting.
Some addition trial and error training
learn.set_data(get_data(299,bs))
learn.fit(1e-2,3,cycle_len=1)
learn.fit(1e-2,3 cycle_len=1, cycle_mult=2)
Scoring
log_preds,y = learn.TTA()
probs = np.exp(log_preds)
accuracy(log_preds,y), metrics.log_loss(y, probs)