So just recently (yesterday) I figured out a way to combine Tabular + Images in the fastai2 framework, and this general approach should work with just about any DataLoader, and I’ll try to explain and discuss why here.
Caution: So far just works with Tab + Vision, need to figure out why it won’t work for text Can verify it works any DataLoader except LMDataLoaders (as those have their own special bits, etc)
The Pipeline
Here is an outline of how you go about doing this:
- Make your
tabandvisDataLoaders
(vis= Vision,tab= Tabular) - Combine them together into a
Hybrid DataLoader - Adjust your own
test_dlframework how you choose - Train
The Code:
Now let’s talk about the code. For our “DataLoader”, it won’t inherit the DataLoader class (hence the quotes around it). Instead we’ll give it the minimal similar behavior to a DataLoader that is needed, and have everything else work internally. Specifically, these functionalities:
FakeLoader__len____iter__one_batchshow_batchshuffle_fnto
Now to build this I’m going to walk us through it with @patch from the fastcore library. Basically this lets us lazily define the class as we go, so don’t get confused to why it’s all in more than one block.
__init__ and FakeLoader
The __init__ for our model needs to store 5 items, the device we’re running on, our two DataLoaders we’re passing in, a count, a _FakeLoader, and our new shuffle function (for now this will be undefined, we’ll discuss it more in a moment). Also, FakeLoader is used during the __iter__, see the regular DataLoader source code to see it there:
from fastai2.data.load import _FakeLoader, _loaders
class MixedDL():
def __init__(self, tab_dl:TabDataLoader, vis_dl:TfmdDL, device='cuda:0'):
"Stores away `tab_dl` and `vis_dl`, and overrides `shuffle_fn`"
self.device = device
tab_dl.shuffle_fn = self.shuffle_fn
vis_dl.shuffle_fn = self.shuffle_fn
self.dls = [tab_dl, vis_dl]
self.count = 0
self.fake_l = _FakeLoader(self, False, 0, 0)
shuffle_fn
Now we’ll look at the shuffle_fn there. What needs to have happen? The shuffle_fn returns a list of index’s for us to use, that’s stored inside of self.rng, and we want those index’s to change every 2 times we call the shuffle_fn (as we call it for each of our internal DataLoaders), to ensure that both are mapped out to the same index’s for preparing our batch. This is what that looks like:
@patch
def shuffle_fn(x:MixedDL, idxs):
"Generates a new `rng` based upon which `DataLoader` is called"
if x.count == 0: # if we haven't generated an rng yet
x.rng = x.dls[0].rng.sample(idxs, len(idxs))
x.count += 1
return x.rng
else:
x.count = 0
return x.rng
This is all that’s needed to ensure that all of our batches get shuffled together. And if you’re using more than two, count is just equal to n internal DataLoaders.
While we’re at it, we’ll take care of two other functions, the __len__ attribute and the to function. __len__ just needs to grab the length of one of our DataLoaders, and to just returns the name of our device:
@patch
def __len__(x:MixedDL): return len(x.dls[0])
@patch
def to(x:MixedDL, device): x.device = device
__iter__
Now let’s move into something a bit more complex, the iterator. Now, our iterator needs to take all of our batches from our loaders and perform the after_batch transform for those outputs from their respective DataLoader before finally being put into a batch, also moving each to the device. While this may look scary, the _loaders etc is all the same as it is from the DataLoaders class, so it’s just how we access them:
@patch
def __iter__(dl:MixedDL):
"Iterate over your `DataLoader`"
z = zip(*[_loaders[i.fake_l.num_workers==0](i.fake_l) for i in dl.dls])
for b in z:
if dl.device is not None:
b = to_device(b, dl.device)
batch = []
batch.extend(dl.dls[0].after_batch(b[0])[:2]) # tabular cat and cont
batch.append(dl.dls[1].after_batch(b[1][0])) # Image
try: # In case the data is unlabelled
batch.append(b[1][1]) # y
yield tuple(batch)
except:
yield tuple(batch)
Notice the device is adjusted recursively before we move to the batch transforms (this is how fastai moves them all to the GPU)
one_batch
Alright, so we can build it, iterate it, now how do we get our good ol’ fashion one_batch? Quite easily. We call fake_l.no_multiproc() (which so you know, that means we temporarily adjust the num_workers in our DataLoader to zero) and grab the first batch, while also discarding any iterators the DataLoader may have (as first calls next(iter(dl))):
@patch
def one_batch(x:MixedDL):
"Grab a batch from the `DataLoader`"
with x.fake_l.no_multiproc(): res = first(x)
if hasattr(x, 'it'): delattr(x, 'it')
return res
You may or may not get an exception error, (Sylvain if you’re reading this, it’s:
Exception ignored in: <generator object MixedDL.__iter__ at 0x7f75b31d0cd0>
RuntimeError: generator ignored GeneratorExit
) However this can be ignored I’ve found, as all your data will be returned. Your batch now returns as [cat, cont, im, y]
show_batch
Next up is probably the easiest out of all of the functions. All we’re wanting to do here is in each DataLoader, call show_batch. It’s as simple as it sounds:
@patch
def show_batch(x:MixedDL):
"Show a batch from multiple `DataLoaders`"
for dl in x.dls:
dl.show_batch()
For an example output, here is one for a recent (and ongoing) kaggle comp:
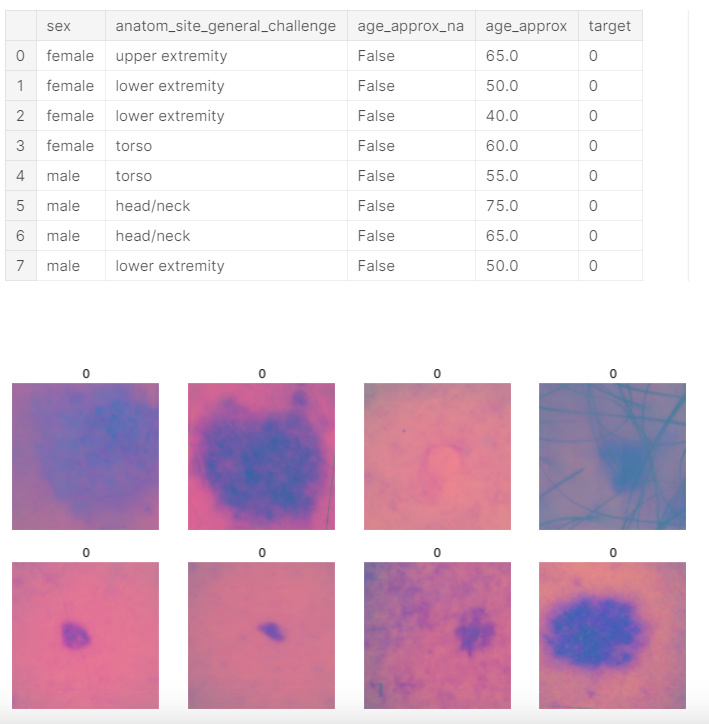
And that’s all that’s needed to start training and have all the functionalities of fastai while bringing in the various DataTypes. So they key that made this entire thing possible is due to how fastai does the shuffle_fn, and the fact they are indices.
test_dl
The last thing I’ll show is how to do the test_dl. When you’re making these ideally you build the entire Image and Tabular dls, which gives you access to the .test_dl function. From there, simply do something like:
im_test = vis_dl.test_dl(test_df)
tab_test = tab_dl.test_dl(test_df)
test_dl = MixedDL(tab_test, im_test)
And you’re good to go! The main reason we don’t have to worry about enabling shuffling, etc is due to the fact it’s done on the interior DataLoader level.
I hope this helps you guys, let me know if there are any questions! (Or recommendations on how to improve this method further)