Efficient multi-lingual language model fine-tuning Written: 10 Sep 2019 by Julian Eisenschlos, Sebastian Ruder, Piotr Czapla, and Marcin Kadras
3 Likes
Hi @pierreguillou - regarding your question about benefits of SpaCy vs SentencePiece tokenization: the article’s (see Joseph Catanzarite’s post above) authors Eisenschlos, Ruder, Czapla, Kardas, Gugger and Howard come to the conclusion that for their new “MultiFiT” model (with 4 QRNN layers):
Subword tokenization outperforms wordbased tokenization on most languages, while being
faster to train due to the smaller vocabulary size.
The advantage seems more marked for Italian and German than for French. They found a Sentencepiece vocabulary size of 15k to be performing best and trained their multilingual models on 100 million tokens.
3 Likes
[ EDIT 09/23/2019 ] : I did finally trained a French Bidirectional Language Model with the MultiFiT configuration. It overpasses my other LMs (see my post) ![]()
Thanks @jcatanza and @jolackner. I agree with you: this MultiFiT configuration (see last page of the paper) must be tested and should give better results than the ULMFiT one.
If I found time, I will (by the way, I’ve already published my results using the ULMFiT configuration for a French LM and Sentiment Classifier).
1 Like
Hello, folks of this awesome community.
I am following the lectures of the NLP course at the moment. That’s how I learned about fast.ai in the first place. Now that I am learning more about the community I got super interested in going through the other course(Practical Deep Learning, not sure about the name). I am especially excited about starting to learn Swift! Do you have any suggestions on how to best follow the material? Finish the NLP course and the start Part 1 of Deep Learning? Or just straight into Part 2? Or just pick and choose? Thanks for any suggestion.
Update: I am at lesson 11 of the NLP course.
I really enjoyed going through this course over the summer and have been inspired to publish my first Medium post. It’s about using a pre-trained BERT model to solve English exam ‘gap-fill’ exercises. As a sometimes English teacher I was interested to see how the language model performed on a task that students struggle with. Spoiler: BERT did amazingly well, even on very advanced level exams.
3 Likes
Welcome! I would recommend part 1, this will allow you to start using deep learning for your own projects. Save part 2 for later when you want to dig deeper into the code and understand more about how the library works. The Swift developments are exciting if you are keen on code but part 1 is the place to go to learn first of all how to do deep learning.
Congratulations on your progress with the NLP course. I put the audio on my phone and repeatedly listened to the classes while running on the beach over the summer until I felt I understood the whole picture. Code-first away from a computer!
5 Likes
Thanks Alison, I will keep this in mind when I am done with the NLP course.
Meanwhile I developed my own little and cute iOS app to learn Swift 
I like your innovative approach to consuming the course material, I bet the nice viewing helped!
1 Like
Hi all, i’m studying the notebook 3-logreg-nb-imdb.ipynb in colab but i’ve a strange error in this cell
x_nb = xx.multiply(r)
m = LogisticRegression(dual=True, C=0.1)
m.fit(x_nb, y.items);
val_x_nb = val_x.multiply®
preds = m.predict(val_x_nb)
(preds.T==valid_labels).mean()
the scipy version in colab are 1.3.1 and the xx shape are (800, 260374) and r are (260374,).
The error is
ValueError: column index exceeds matrix dimensions
at row x_nb = xx.multiply®
Can someone help me ?
/usr/local/lib/python3.6/dist-packages/scipy/sparse/coo.py in _check(self)
285 raise ValueError('row index exceeds matrix dimensions')
286 if self.col.max() >= self.shape[1]:
–> 287 raise ValueError(‘column index exceeds matrix dimensions’)
288 if self.row.min() < 0:
289 raise ValueError(‘negative row index found’)
Thanks a lot
Hello @jeremy
I have a quick question on your Text generation algorithms (NLP video 14)
How about taking something of both worlds (beam’s context awareness and sampling’s surprising-ness) by baking sampling inside of each Beam Search Step? Has anyone tried this before?
I tried this while training a language model on my own writing and it was the most realistic among all generation decoders I tried.
Here are the samples from my experiments, input this is about
Greedy
This is about the problem is to be a lot of statement to a state of the strength and weakness of the problem is to be a lot of statement
Sampling
This is about speeches naws, because we do pers customer more. doing my better. 1. i could intelligence ⢠be resporl new 10-2019 practical aug 27 - 47 meeting.
Beam Search
This is about this text for? what do i expect to find in the text? is there any major empirical conclusion and reading after reading what i have (or have not) understood? (make your own note of the text? is there any major empirical conclusion and reading after reading what i have (or have not) understood?
Beam Search + Sampling
This is about the problem with the company and the problem and personal information and reading what i have (or have not) understood? (make your own note of the decision making and complexity is a consulting in the text? is there any major empirical conclusion and reading what are the main ideas presented in the company and then and the problem and predictions and problems and discussion of the problem and responsibilities and discussions and then and have the relationship of the company to learn from the problem with the world.
Thanks for all the great lectures.
2 Likes
Tiny comment about Implementing a GRU (NLP video 15).
Slides
hidden state = z_t ⊗ n_t + (1 - z_t) ⊗ h_t-1
where n_t is newgate and z_t is updategate
Code
updategate*h + (1-updategate)*newgate
I guess that pragmatically the end up in the same thing but the slide version update the hidden state with the “opposite” of the updategate 
Very helpful post.
Do you happen to have a notebook available demonstrating your implementations of each approach?
Hello @wgpubs
I don’t have a notebook, but you can see the source code here
I was thinking of maybe putting this on a notebook to show live performances. I was thinking of what good dataset to use other than my own writing. What do you think?
1 Like
Nice code.
I would think the imdb dataset might be nice since so many folks are familiar with it. There are some other really good options you can check out here: https://course.fast.ai/datasets
re: NLP video 14
Are there any implementations of beam search and sampling for folks using a Transformer type model?
2 Likes
I am working with the lesson 7 notebooks on translation and natural text generation. I was wondering if anyone has had some success saving a trained model and using that for inference. I am running into the ff errors/roadblocks and would like if someone can point me in the right direction.
- Error loading saved model on CPU - Error message “ AttributeError: Can’t get attribute 'seq2seq_loss ’”, seq2seq_loss is the loss function specified in the notebook i’m running. Note: I can load the saved model on a GPU successfully.
- Prediction error - After i use the add_test function to add new data to the learner, i am a little confused on how to proceed with the prediction. I used the pred_acts function from the notebook with dataset type set to Test but it returns this error “ TypeError: object of type ‘int’ has no len() ”
#Disclaimer - i’m a newbie so i may not have tried some ‘obvious’ solutions. Thanks in advance
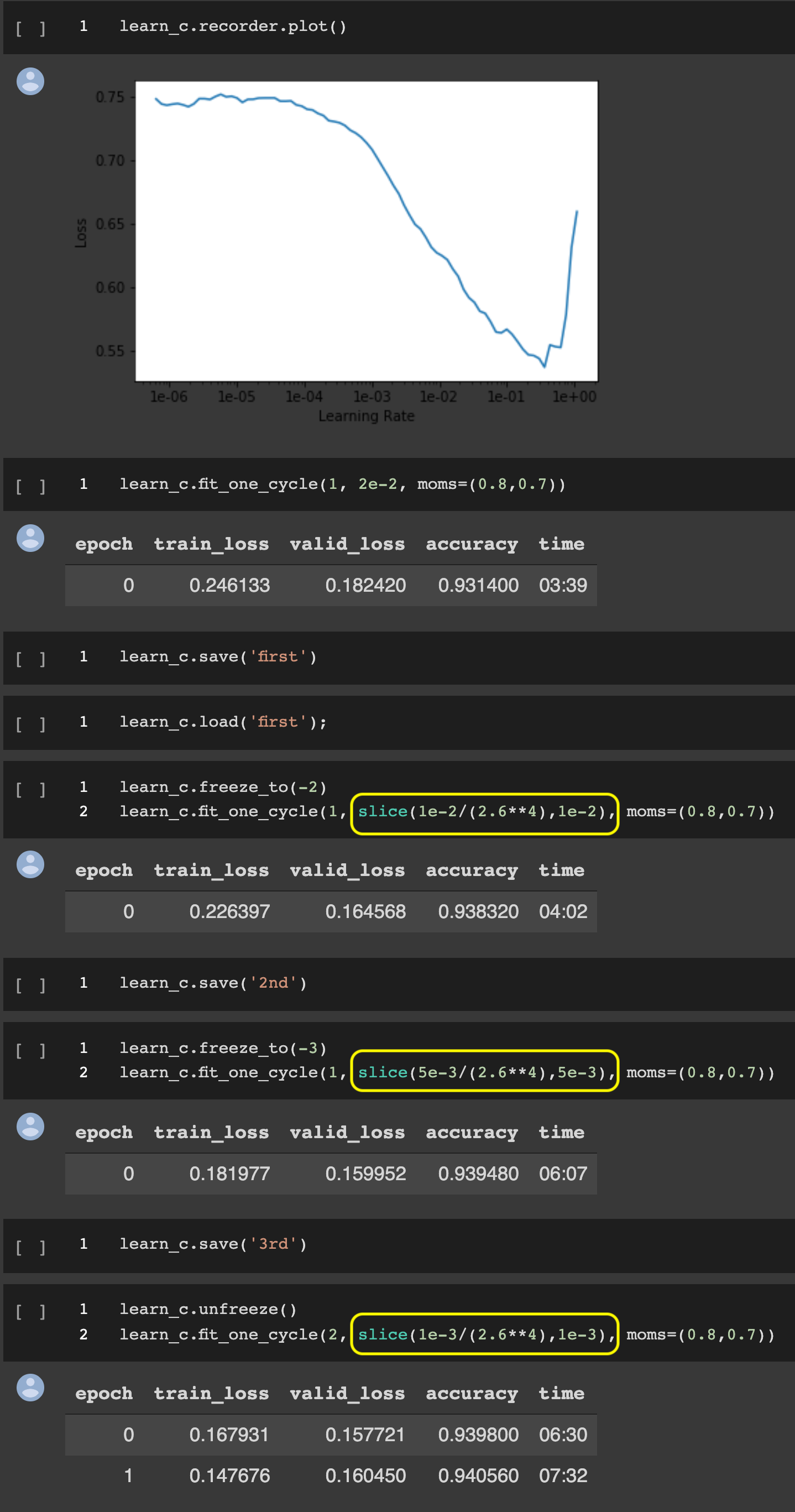
Finding learning rates for training the imdb classifier. I am currently working through notebook 5-nn-imdb.ipynb. When Jeremy creates the classifier for the imdb movie reviews he is using rather complicated formulas for the learning rates.
I think he is using slice because we want the first layer be training with a smaller learning rate than the last layers.
The first learning rate can be found using lr_find(). But how would I find the lr for freeze_tor(-2), freeze_to(-3), etc.?
1 Like
You’d do the freeze first then call lr_find().
1 Like
You mean do:
freeze_to(-1)
lr_find()
find best learning rate
freeze_to(-2)
lr_find()
find best learning rate again
… ?
Yes, you do the standard learn.lr_find() learn.recorder.plot() and pick
1 Like
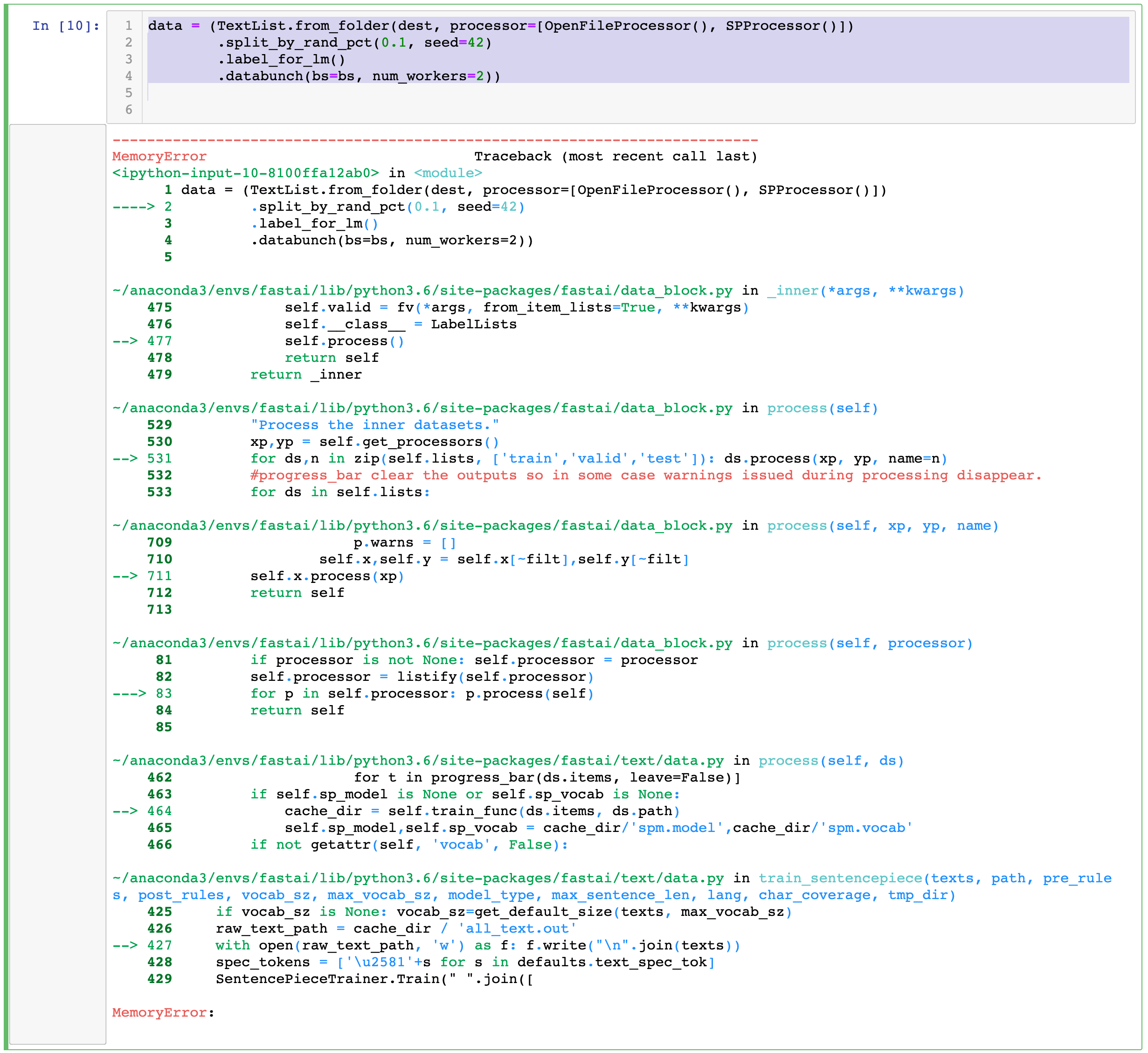
Generating a German language-model, the way Jeremy does for Turkish language. After watching the lecture videos, I was curious to build my own language model for German. I have followed the steps but set language to “de” when downloading the wiki sites.
Nevertheless this line throws an error: MemmoryError: (I have watched the processes with the top on the terminal and the jupyter process never ran over 50% memory usage).
My system has 32GB RAM. (GPU RAM was not used at this stage)
The error occurs after the progresbar finishes. Any idea where to dig deeper to find the error?