The stability of the ssh connection shouldn’t matter. Just make sure you’re always running in a tmux session, so you can always re-connect later.
1 Like
I believe that @piotr.czapla and friends are working on that at the moment! ![]()
3 Likes
tmux is magic. I resisted using it for so long because I thought the setup was going to be annoying and the only thing I had to do was apt-get install tmux and it started working for me. No more Jupyter sessions being killed because I shut my laptop lid!
3 Likes
Thanks Jeremy. Thanks to your answer, I found in “Known issues” on the GPC website the following warning that confirms both my problem and your tmux solution:
**Intermittent disconnects** : At this time, we do not offer a specific SLA for connection lifetimes. Use terminal multiplexers like [tmux](https://tmux.github.io/) or [screen](http://www.gnu.org/software/screen/) if you plan to keep the terminal window open for an extended period of time.
I hope this will also help other fastai users to train DL models online on huge datasets like LMs from scratch.
[ EDIT ] For people without technical background : the idea is to launch your jupyter notebook from a session opened online (on GCP for example) through tmux and not from your ubuntu terminal in your computer. Thus, even if your ssh connection stops, the session used to launch your jupyter notebook is still running online ![]() More information in this post.
More information in this post.
2 Likes
Could someone clarify why vocab.stoi and vocab.itos have different lengths? I’ve watched rachel’s video a couple of times and i’m still unclear. I understand that vocab.itos has all the unique words but then doesn’t vocab.stoi also have all the unique words?
Hi @kausik. You already gave halh of the answer. The whole answer is in the fastai text.transform page.
text.tranformcontains the functions that deal behind the scenes with the two main tasks when preparing texts for modelling: tokenization and numericalization.Tokenization splits the raw texts into tokens (which can be words, or punctuation signs…). The most basic way to do this would be to separate according to spaces, but it’s possible to be more subtle; for instance, the contractions like “isn’t” or “don’t” should be split in [“is”,“n’t”] or [“do”,“n’t”]. By default fastai will use the powerful spacy tokenizer.
Numericalization is easier as it just consists in attributing a unique id to each token and mapping each of those tokens to their respective ids.
For example, these 2 tasks are done by the factory method from_folder() of the TextList class when you create the databunch of the corpus thanks to the Data Block Api.
data = (TextList.from_folder(dest)
.split_by_rand_pct(0.1, seed=42)
.label_for_lm()
.databunch(bs=bs, num_workers=1))
If you look at the source code of the from_folder() method, you see for example the parameters max_vocab = 60000 (no more than 60 000 tokens in the vocabulary) and min_freq = 2 (a token is kept in the vocabulary if it appears at least twice in the corpus).
With these parameters (but there are others), we can understand that the vocab.itos which is the list of unique tokens is constrained (limited to 60 000 tokens with the highest frequency of occurrence, etc.) and then smaller in size than the vocab.stoi dictionary which contains all the tokens of the corpus.
Finally, the vocab.stoi dictionary has tokens as keys and their corresponding ids in vocab.itos as values. Thus, all tokens not belonging to the vocabulary will be mapped to the id of the special xxunk token (unknown).
Hope it helps.
2 Likes
Hi @jolackner,
As I want to train a French LM on GCP, I’m searching for the right configuration and in particular the training GPU time I will face.
I found in your link to Wikipedia articles count that in the last count (dec. 2018), there was 1.75 more articles in French (2.1 M) than in Vietnamese (1.2 M). However, it does not mean that the training of my French LM will be 1.75 bigger than the Vietnamese one.
In fact, your post gave me the idea to compare not the number of Wikipedia articles but my French databunch with the Vietnamese one created in the nn-vietnamese.ipynb notebook of Jeremy (note: the 2 databunches are created with nplutils.py from the course-nlp github).
Vietnamese databunch (bs = 128)
- number of text files in the docs folder = 70 928
- size of the docs folder = 668 Mo
- size of the vi_databunch file = 1.027 Go
French databunch (bs = 128)
- number of text files in the docs folder = 512 659 (7.2 more files)
- size of the docs folder = 3.9 Go (5.8 bigger)
- size of the fr_databunch file = 5.435 Go (5.3 bigger)
If we use only the databunch size as ratio and with all notebooks parameters identical and same GPU configuration as Jeremy, the 28mn30 by epoch for the training of the Vietnamese LM learner should be 28mn30 * 5.3 = 2h30mn by epoch to train the French LM learner.
I started with one NVIDIA Tesla T4 (batch size = 128) but the epoch training time (ETT) was about 6h.
Then, I’m testing one NVIDIA Tesla V100 with the same bs and my ETT decreased to 2h10mn (see screen shot).
Note: Jeremy said that he used a TITAN RTX from the SF university but this GPU does not exist on GCP.
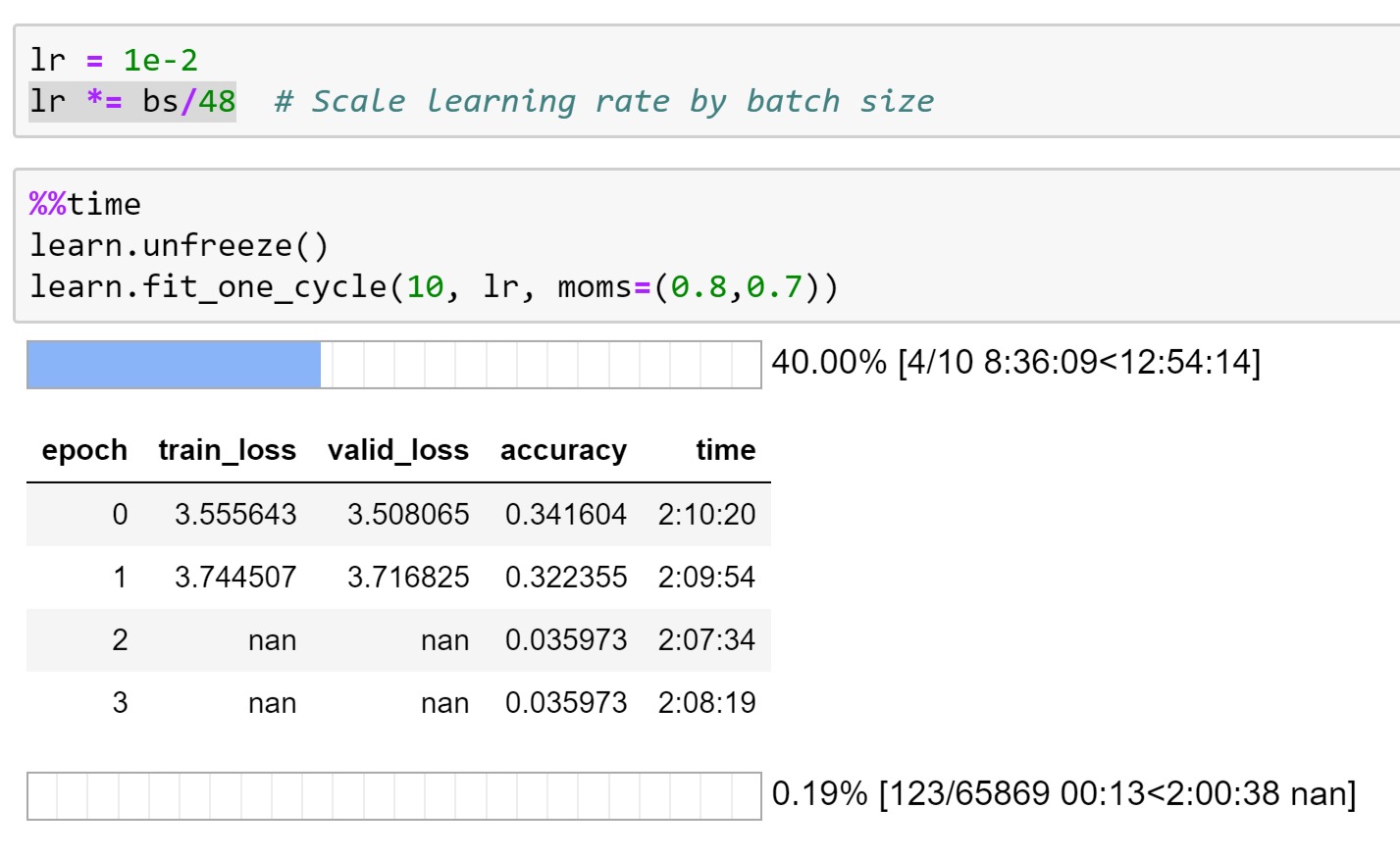
Great? Yes in terms of ETT but I’m still facing hard time with GCP. From the third epoch, nan values began to be displayed (see screen shot). For info, I’m using learn.to_fp16() and an initial Learning Rate (LR) of 1e-2 that was given by learn.lr_find() (see screen shot) but in reality 1e-2 * (128/48) = 2.6e-2 as I followed the code of Jeremy.
learn = language_model_learner(data, AWD_LSTM, drop_mult=0.5, pretrained=False).to_fp16()
I guess that the nan values mean that my losses diverge (ie, LR too high)?
So my question to @rachel and @jeremy: why do we need to scale our LR? Should I keep my LR of 1e-2 ? Thanks.
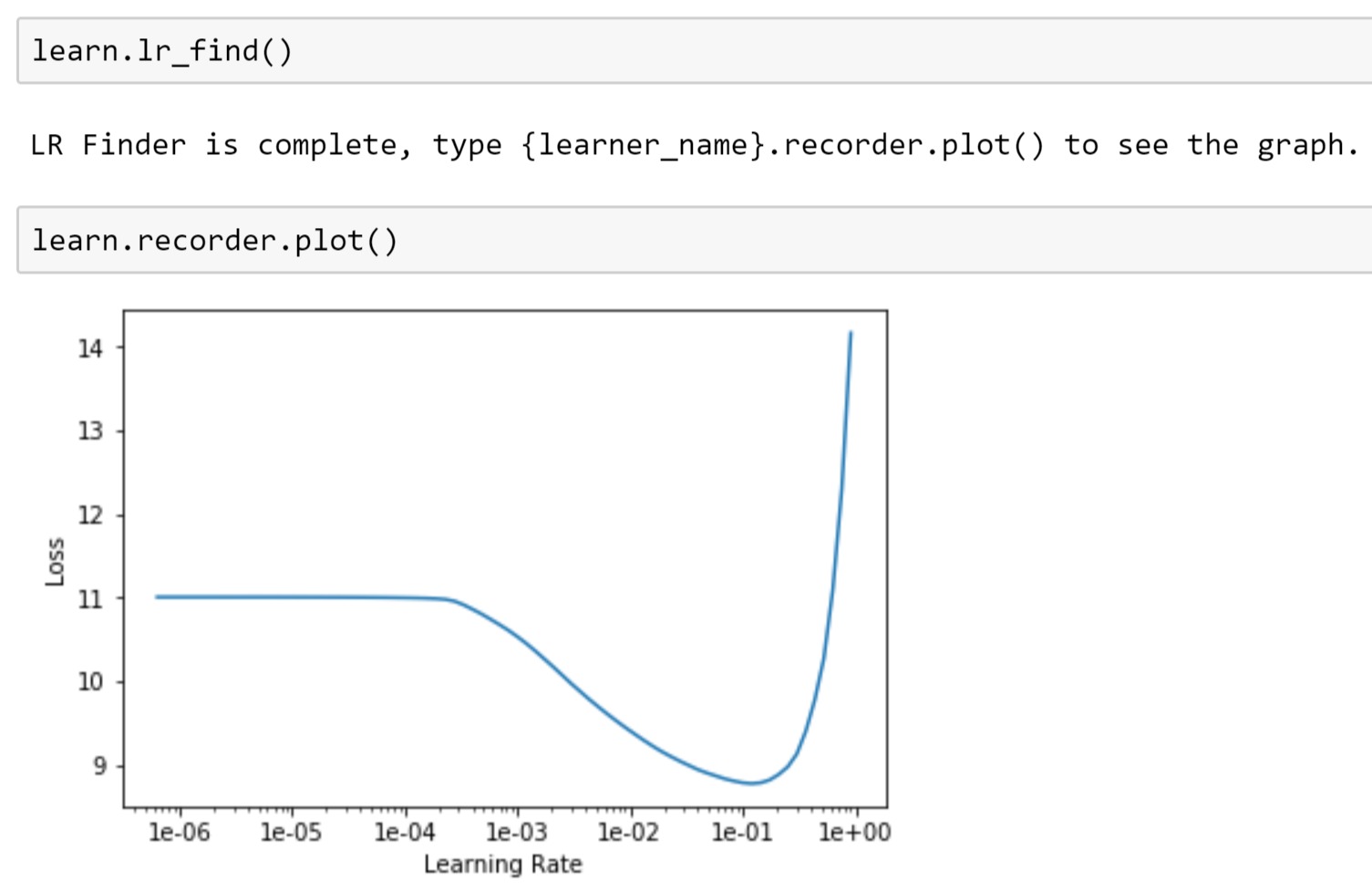
Training can be a little more flaky with fp16. Try making your LR 10x lower and see how it goes.
Thank you @pierreguillou for pointing out that the databunch size is much more relevant for training duration!
Re: the learning rate - I trained my German Wikipedia language model with lr = 3e-3 (and additionally scaled by batch size bs/48) after seeing similar problems with exploding losses.
My lr finder curve looked similar to your curve, although I ran a Sentencepiece tokenization, as German is heavy on concatenated words (“Donaudampfschifffahrtsgesellschaftskapitän” is a favourite).
After 10 epochs (GCP, P4, fp16, 2hrs/epoch), I got to 43.7% accuracy with the fwd model…
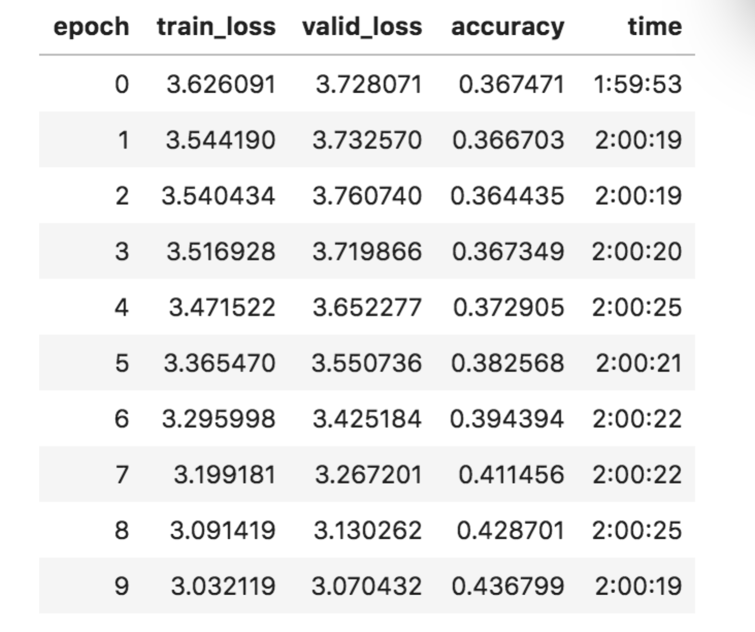
… and 48% accuracy with the backwards model (I restarted training, printout from last 5 epochs):
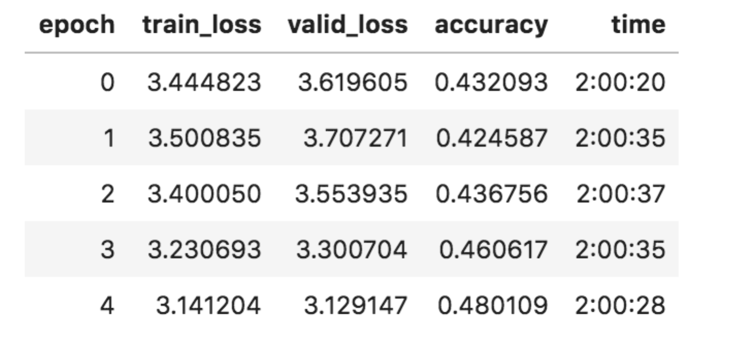
I’d like to better understand what the higher backwards prediction accuracy says about the German language (Jeremy mentioned in the videos that Vietnamese seems easier to predict backwards than forwards) and what use could be made of that. For a downstream regression task it didn’t seem to make a big difference so far.
Hello @jolackner. I’m impressed by your “2 hours by epoch on a P4”!
Could you tell us more about your data and parameters ? (size of vocab.itos and vocab.stoi, size of your dataset used to create your databunch, batch size, drop_mult in your learner…). Thank you.
Note: I asked as well yesterday a question relative to the dataset size to be used for training in the Language Model Zoo thread.
Hello @pierreguillou. It’s really not impressive at all, I simply reduced the Wikipedia dataset successively until I could generate a databunch without the GCP session freezing up on me - Sentencepiece tokenization is more memory intensive than Spacy tokenization.
In the end my German fwd databunch had a size of 939 MB (same size bwd, obviously). Batch size was bs=128 and I don’t think I changed drop_mult from the notebook suggestions (but I can check once home, can’t ssh into GCP from here). I used the default sentencepiece vocab size of 30k.
EDIT: The 939 MB databunch contained 113 Million subword tokens. I followed the “Turkish ULMFit from scratch” notebook, not straying from the suggested drop_mult=0.1 & wd=0.1 .
Thanks @jolackner.
On my side, I reduced by 5 the size of my databunch of the French wikipedia dataset from 5.435 Go to 1.077 Go in order to have a corpus of about 100 millions of tokens as adviced by Jeremy.
Note: if I understand well that using a databunch of 1 Go instead of 5 Go will speed up the ETT (Epoch Traing Time) of my Language Model, I think that I’m loosing a lot of language knowledge. Do you have an opinion on that?
On this base, I’m training today my French LM with the learner parameters values of the nn-vietnamese.ipynb notebook:
# bs = 128
# len(vocab.itos) = 60 000
learn = language_model_learner(data, AWD_LSTM, drop_mult=0.5, wd=0.01, pretrained=False).to_fp16()
After that, I will train it from scratch with the learner parameters values of the nn-turkish.ipynb notebook like you did (ie, drop_mult=0.1 & wd=0.1):
learn = language_model_learner(data, AWD_LSTM, drop_mult=0.1, wd=0.1, pretrained=False).to_fp16()
I will published the results afterwards.
The default model size isn’t big enough to take advantage of it. I believe that @bfarzin has had some success with larger models and a larger corpus, however.
Hello @bfarzin. After Jeremy’s post, I looked in the forum for information about your larger LM model with a larger corpus. I found a post and a blog post from you about using QRNN instead of AWD-LSTM. This is the way to train a LM with a larger corpus? Thanks.
I’m away from my machine this week and can look more in depth next week. But iirc I used titan GTX which has 24 Gb memory. My experience was that SentencdPiece worked well and took far less memory. QRNN also helped on memory but I did not try with fp16 because that was not supported at he time (I think it’s supported now)
You do get better results when you have a bigger corpus in general because you want the tokenization to see as big a vocab as possible.
I also had luck with distributed learning across multiple AWS machines. But that can be expensive to run to reduce time per epoch.
Coming, what is your objective? Build an LM from scratch?
Hi @KevinB. Clearly, it is a good pratice to use tmux to deal with running a Jupyter Notebook on an online GPU. I found in the forum a short howto guide and a post about “Restoring Jupyter client’s GUI (scores and graphs…etc) after client disconnects for long time” (and a “tmux shortcuts & cheatsheet” page).
About GCP: as the notebook server is launched with the instance in GCP, I’m not sure if tmux is needed (a ssh disconnection will not stop the notebook server) but it is good practice. I do the following:
-
SSH connection to my fastai instance:
gcloud compute ssh --zone=MY-ZONE-INSTANCE jupyter@MY-FASTAI-INSTANCE -
Launch of my tmux session:
tmux new -s fastai -
Creation of 2 vertical panes:
ctrl b + % -
Launch of the notebook server on port 8081 (as the port 8080 is already used):
jupyter notebook --NotebookApp.iopub_msg_rate_limit=1e7 --NotebookApp.iopub_data_rate_limit=1e10 --port 8081 --no-browser -
Detach my tmux session
ctrl b + d -
Stop my ssh connection:
exit -
SSH connection again to my fastai instance but now with association between the port 8081 of the jupyter notebook server on my GCP fastai instance and my local port 8080 on my computer
gcloud compute ssh --zone=MY-ZONE-INSTANCE jupyter@MY-FASTAI-INSTANCE -- -L 8080:localhost:8081
That’s it. I can run my notebooks from my GCP fastai instance at http://localhost:8080/tree on a web browser. If my ssh connection stops, my Jupyter server is still running in the tmux session on GCP. I have only to redo the step 7 above and I get back my notebooks which were not stopped by the ssh disconnection.
5 Likes
Nice, that looks like great information! I don’t use GCP myself, but that information seems super useful for everybody that does.
One think you might want to look into is tmuxp which can do a lot of that pre-setup for you. You can read more about it here
So in this lesson course-nlp/6-rnn-english-numbers.ipynb at master · fastai/course-nlp · GitHub
I am bit confused about the target section
def loss4(input,target): return F.cross_entropy(input, target[:,-1])
def acc4 (input,target): return accuracy(input, target[:,-1])
Why is target given as target[:,-1]? I am bit confused about what’s happening under the hood here?
If you are looking for a labeled dataset in English US, English UK, French, German or Japanese to train and test your ULMFiT classifier, you can download the Amazon Customer Reviews Datasets.
If you need help, I published a download guide.
Thanks for your answer. In order to understand the NLP course, I run all the notebooks. This helps to understand the course and in addition, the problems encountered allow to understand the limits of the LM models (a LM model even through ULMFiT is not magic, it will not generate great texts, it takes time to be trained, IRL there are ssh disconnections when training a model for a long time, sometimes it is hard to launch your GPC instance because “GCP does not have enough resources available to fulfill the request”, you can change the LM architecture from AWD-LSTM to QRNN but for what benefits and how, the same for tokenizing from SpaCy to SentencePiece but for what benefits and how, etc.).
I did succeed to train a French LM from scratch with a 100 millions tokens dataset by using the nn-vietnamese.ipynb notebook (I will publish it) but now, I would like to get a better LM to test for example the generation of synthetic text. That’s why I’m trying to use all my Wikipedia dataset (almost 500 millions tokens) but for that I need a deeper LM or a different one (GPT-2, BERT…) or/and others parameters or/and more GPUs. Any information/advice is welcome. Thanks.
1 Like