<<< Wiki: Lesson 3 | Wiki: Lesson 5 >>>
Lesson links
- Lesson video
- Lesson notes from @hiromi
- Lecture notebook from @timlee
- Kaggle Kernel for lesson 4
- Running IMDB notebook under 10 minutes
Articles
- Vitaly’s Article
- Rachel’s Article on Validation Set
- The Cyclical Learning Rate Technique
- Exploring Stochastic Gradient Descent with Restarts (SGDR)
- Transfer Learning Using Differential Rates
- Deep Learning, NLP, and Representations
Video timeline
-
00:00:04 More cool guides & posts made by Fast.ai classmates
“Improving the way we work with learning rate”, “Cyclical Learning Rate technique”,
“Exploring Stochastic Gradient Descent with Restarts (SGDR)”, “Transfer Learning using differential learning rates”, “Getting Computers to see better than Humans” -
00:03:04 Where we go from here: Lesson 3 -> 4 -> 5
Structured Data Deep Learning, Natural Language Processing (NLP), Recommendation Systems -
00:05:04 Dropout discussion with “Dog_Breeds”,
looking at a sequential model’s layers with ‘learn’, Linear activation, ReLu, LogSoftmax -
00:18:04 Question: “What kind of ‘p’ to use for Dropout as default”, overfitting, underfitting, ‘xtra_fc=’
-
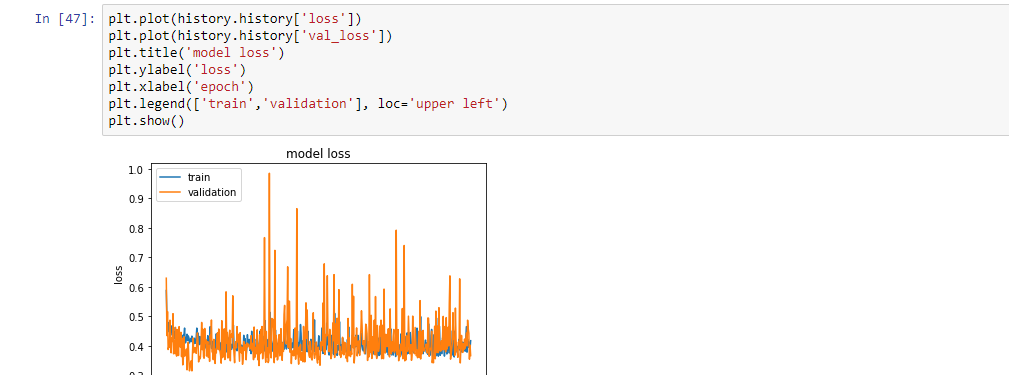
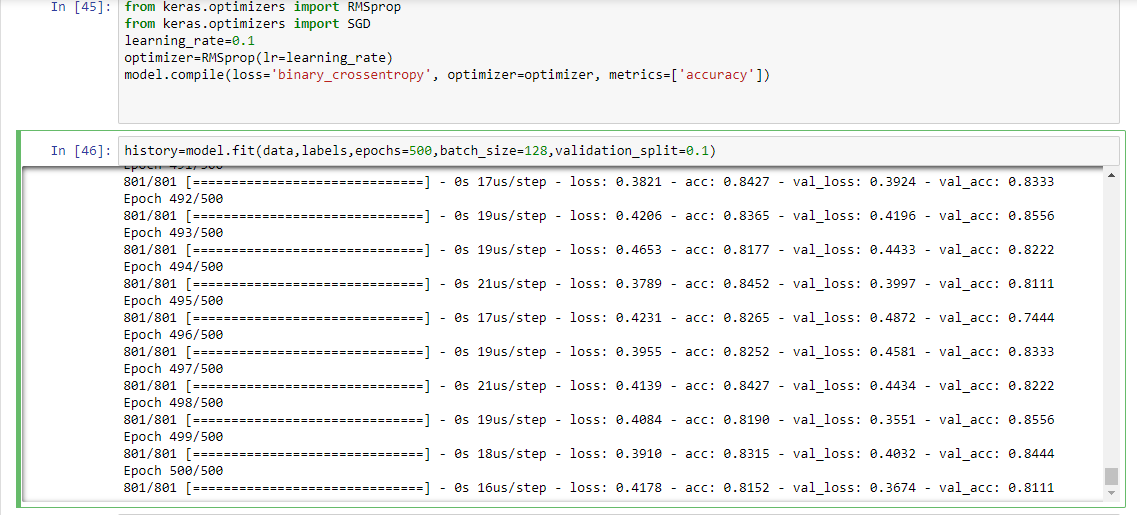
00:23:45 Question: “Why monitor the Loss / LogLoss vs Accuracy”
-
00:25:04 Looking at Structured and Time Series data with Rossmann Kaggle competition, categorical & continuous variables, ‘.astype(‘category’)’
-
00:35:50 fastai library ‘proc_df()’, ‘yl = np.log(y)’, missing values, ‘train_ratio’, ‘val_idx’. “How (and why) to create a good validation set” post by Rachel
-
00:39:45 RMSPE: Root Mean Square Percentage Error,
create ModelData object, ‘md = ColumnarModelData.from_data_frame()’ -
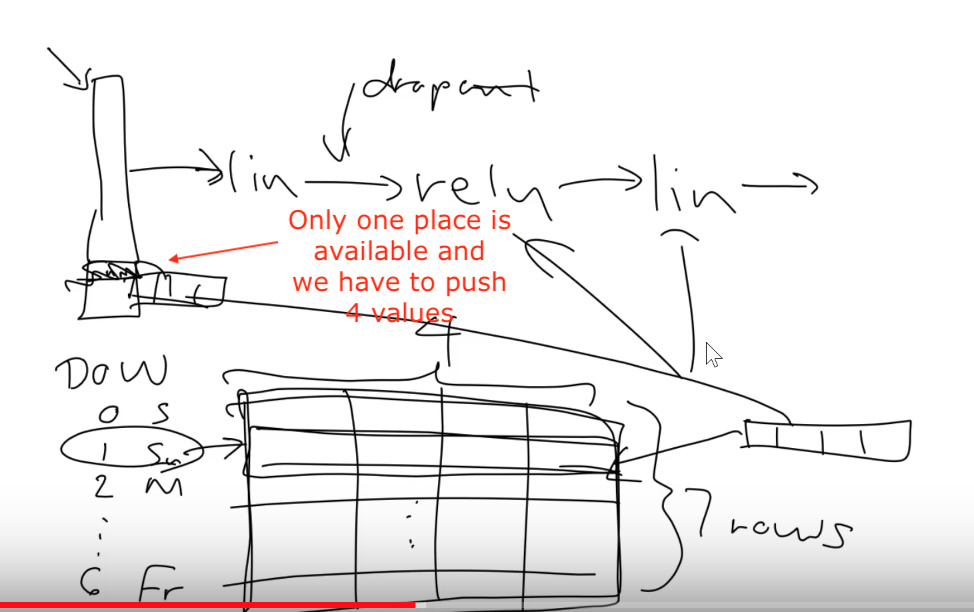
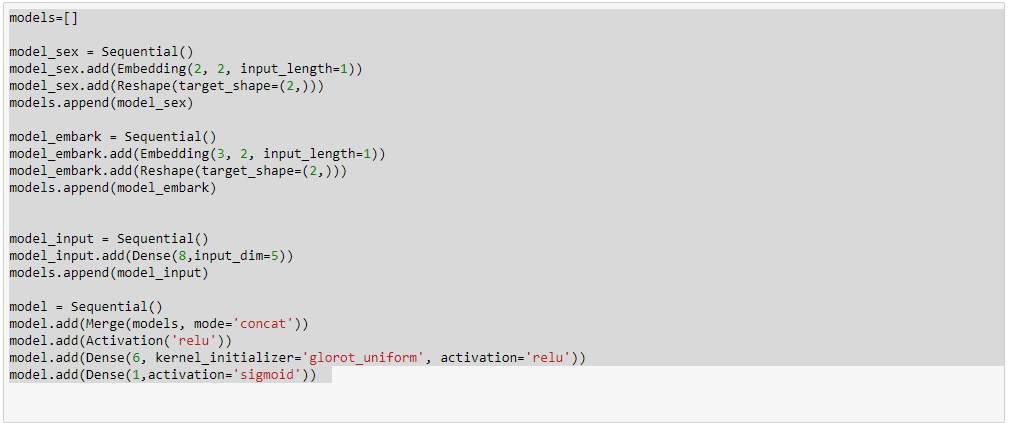
00:45:30 ‘md.get_learner(emb_szs,…)’, embeddings
-
00:50:40 Dealing with categorical variables
like ‘day-of-week’ (Rossmann cont.), embedding matrices, ‘cat_sz’, ‘emb_szs’, Pinterest, Instacart -
01:07:10 Improving Date fields with ‘add_datepart’, and final results & questions on Rossmann, step-by-step summary of Jeremy’s approach
Pause
-
01:20:10 More discussion on using Fast.ai library for Structured Data.
-
01:23:30 Intro to Natural Language Processing (NLP)
notebook ‘lang_model-arxiv.ipynb’ -
01:31:15 Creating a Language Model with IMDB dataset
notebook ‘lesson4-imdb.ipynb’ -
01:31:34 Question: “So why don’t you think that doing just directly what you want to do doesn’t work better?” (referring to the pre-training of a language model before predicting whether a review is positive or negative)
-
01:33:09 Question: “Is this similar to the char-rnn by karpathy?”
-
01:39:30 Tokenize: splitting a sentence into an array of tokens
-
01:43:45 Build a vocabulary ‘TEXT.vocab’ with ‘dill/pickle’; ‘next(iter(md.trn_dl))’
-
The rest of the video covers the ins and outs of the notebook ‘lesson4-imdb’, don’t forget to use ‘J’ and ‘L’ for 10 sec backward/forward on YouTube videos.
-
02:11:30 Intro to Lesson 5: Collaborative Filtering with Movielens
Notes
Embeddings vs One-Hot Encoding: Embeddings are better than One-Hot Encodings because it allows for relationships to be shown between days. (Saturday and Sunday are both weekends). One-Hot Encoding shows each value perfectly equal to each other. Wednesday and Saturday have the same relationship as Saturday and Sunday. In other words, Embedding gives a neural network a chance to learn “rich representations”.
Overfitting vs. Underfitting, an example
training, validation, accuracy
0.3, 0.2, 0.92 = under fitting
0.2, 0.3, 0.92 = over fitting