<<< Post: Lição 3 | Post: Revisão>>>
Nesta aula, é apresentada a aplicação de DL em séries temporais, para gerar Embeddings e como utilizar Dropouts para regularização e evitar over fitting. A segunda parte foca na introdução do uso da biblioteca fastai para NLP, mais detalhes serão estudados na aula 5. Como prática iremos utilizar dados do PubMed para classificação de artigos científicos com base sem seus resumos.
Agenda:
09:00-10:40 Aula 4
10:40-10:50 Intervalo
10:50-12:00 Atividade prática
Roteiro do vídeo: baseado no post (Wiki: Lesson 4)
Intro
*Parte 1: 00:00:04 - 00:23:45
Discussões gerais, apresentação de artigos de interesse e dúvidas da aula passada. Para os links dos artigos consultar o post da @rachel.
Nessa parte iremos discutir somente as dúvidas sobre Dropouts: 00:18:04 “What kind of ‘p’ to use for Dropout as default”, overfitting, underfitting, ‘xtra_fc’”
*Parte 2: 00:25:04 - 01:07:10
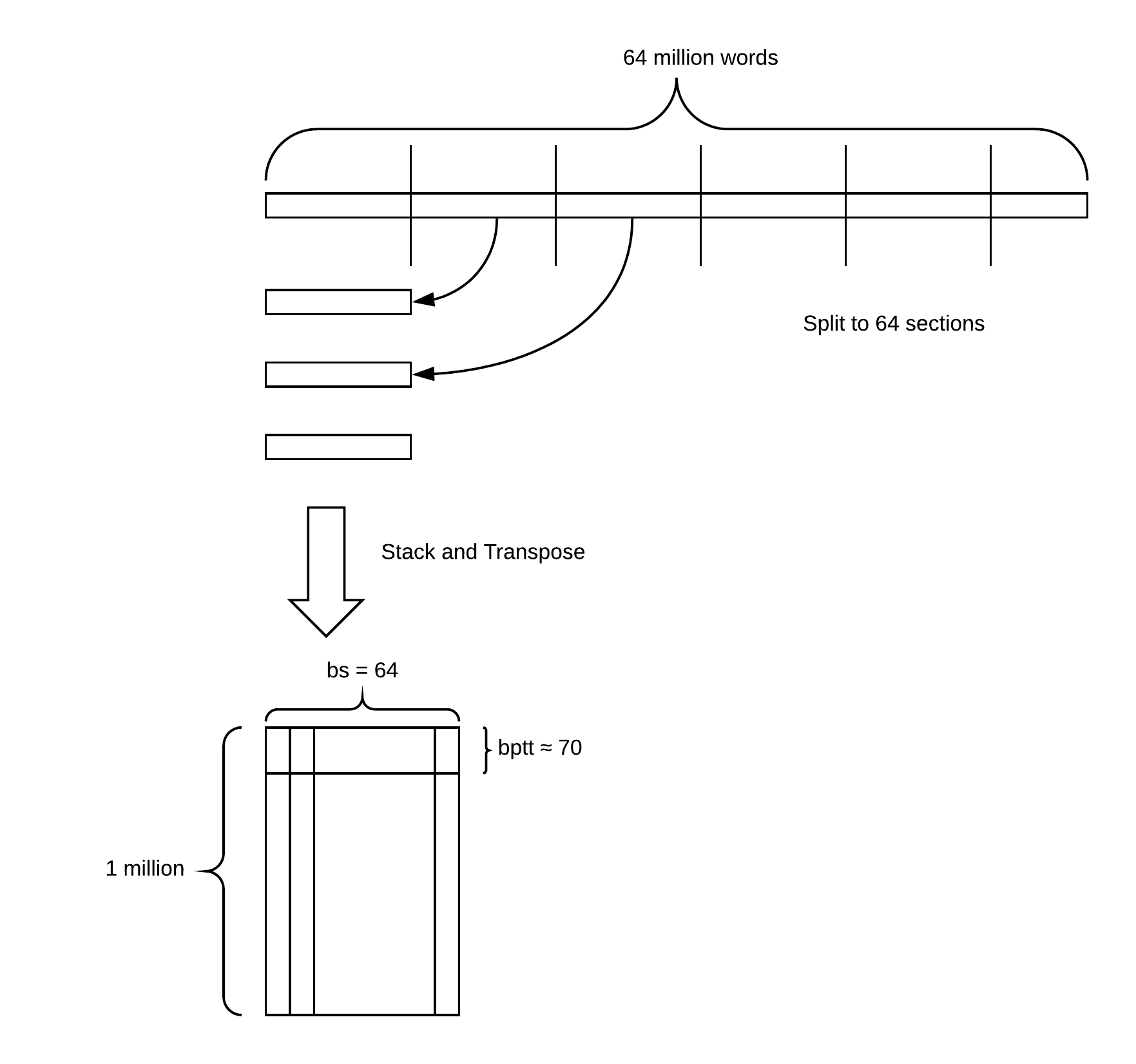
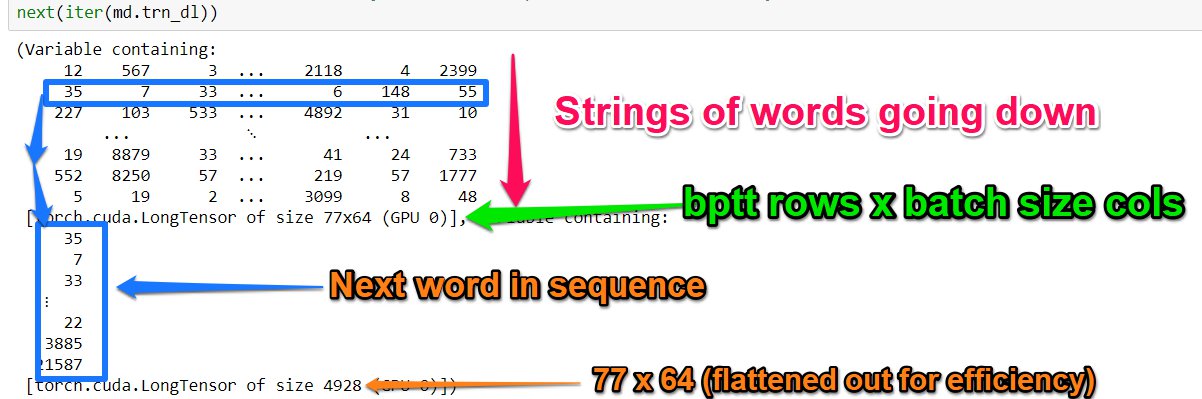
É apresentada a abordagem sobre dados estruturados e séries temporais na biblioteca fastai. Funções auxiliares da biblioteca para lidar com questões recorrentes nesses tipos de dados sãos apresentadas. A principal parte é a discussão sobre o que são embeddings para dados categóricos.
*Parte 3: 01:23:30 - 01:43:45
Os conceitos iniciais sobre NLP utilizando a fastai e a torchtext, sem muitos detalhes dos conceitos. Mais detalhes serão explicados na aula 5.
Desafio:
Apesar da atenção grande em cima das competições do Kaggle, essa aula vamos torrar um pouco os neurônios para entender os conceitos básicos de vocabulário e testar uma classificação multilabel com a fastai. A base do desafio é a talk realizada em 2017 no Spark Summit: https://databricks.com/session/natural-language-understanding-at-scale-with-spark-native-nlp-spark-ml-and-tensorflow. A ideia é pegar 1.000 documentos do pubmed de 6 categorias diferentes e tentar criar uma rede para prever sua categoria.
Nossa baseline é uma acurácia de 99%.
Parte 1: Utilizar os vetores pré-treinados do IMDB para tentar classificar. Qual o impacto de utilizar um vetor pré-treinado?
Parte 2: Criar o modelo/vocabulário em cima dos dados baixados. Qual tamanho para o novo vocabulário?
Parte 3: Rodar as 6 etapas do fastai para classificar os textos.
Amanhã o notebook com o download dos dados será postado na atualização do post.
Importante
O dataset do IMDB gera vetores esparsos muito grandes e a parte de treino é bem demorada. O @vikbehal salvou a parte de criação do modelo e depois do fine tunning para classificação de sentimentos. Portanto durante a aula, ao invés de rodarmos cada passo iremos carregar os modelos fornecidos.



{kind=link}
{kind=link}