This thread’s objective is to discuss the ULMFiT implementations in different languages and share our roadblocks and approaches.
A word to newcomers
This thread is huge, and can be overwhelmed, but there is an easy way to get started.
how to contribute
If you want to participate, simply:
pick the language
start a new thread “ULMFIT - language”,
copy what is currently in this message to your new thread
inform the person that was previously working on the language that you want to participate
place a link to this message
and finally post a message to everyone at the bottom of this thread, so ppl can join
There is still plenty of languages to tackle so far we beat SOTA for :
Thai, Polish, German, Indonesian, Hindi, Malay. (AFAIK)
WIP:
French [high acc, no baseline yet], Portuguses [high acc, no baseline yet] , Chinese
This is a Wiki, please add you name (via hyperlink not @user_name) and the language you are working on by alphabetical order. Feel free to form a group to discuss your language specific problems as well.
@jeremy Technically speaking, Chinese is one language but with two set of written characters (simplified and traditional). To be honest, I (and most of the people I know) use them interchangeably. Currently, I am using the same data set as @shoof and converted it traditional characters via mafan. Should I train the traditional only or both? Since it will take very long to train a model, your direction is highly appreciated.
I am not an expert at Chinese or at Chinese text encoding, but my husband is legitimately an expert at Asian script text encoding. I asked him, and he said that Simplified and Traditional are not just different in the shape of the characters – it’s not like they are different fonts, it’s more like different spelling. (Please forgive me if I am telling you something you already know.) For example, he says there are multiple cases where there are several Traditional characters which all map to the same Simplified character. (This is why the Unicode standard has two different sets of encodings for the characters.)
One thing he does not know is how different the “spelling” is between Simplified and Traditional. There are many characters where the Traditional and Simplified have the same Unicode encoding (like Horse, which is Unicode U+99AC for both Simplified and Traditional (and Japanese and Korean and Vietnamese)
In English, the regional spelling differences are minor enough that I think (I could be wrong!) that usually people just train on “English” and don’t worry about whether it is US or British or Australian or Indian English.
However, for US/British/Australian/Indian/etc., they all use characters from the same Unicode set – the same alphabet. A Latin “G” is unicode U+FF27, regardless of whether it’s Australian or Canadian. However, the Traditional Chinese for the first symbol in “country” (國) is unicode U+570B while the Simplified (国) is U+56FD. This means that whatever model you have is going to think that 國 and 国 are completely different words.
Now, maybe mafan is clever enough to know all the mappings between Simplified and Chinese – I don’t know and it’s late enough that I’m not going to try to download and try to convert 國 to 国. If that is the case, then my non-Chinese-expert-self thinks it’s probably reasonable to just train on one.
However, using a simplified corpus which has been translated via mafan seems like it wouldn’t buy you anything. If mafan is that good, then you could just use mafan translate the Simplified on the input and output and you’d be done. If mafan is not that good, then I would think you would need to have a Traditional corpus.
It might also be – I don’t know – that there will be subtle differences in the words used in Simplified and Traditional corpuses. Just like there were words in the IMDB database which were not in Wikitext103, maybe there is e.g. a minor celebrity star in Hong Kong whose name has unusual characters which are not used commonly in China. So I would think that if you want to do Traditional, you should get a Traditional corpus, not just translate a Simplified corpus.
My opinion, probably worth as much as you paid for it.
@Moody and I are both Chinese speakers (her natively, me poorly!) so we’re familiar with the issue. It’s an interesting one and your husband’s analogy is a pretty good one. However any English analogy is going to have problems since this issue is fairly specific to logographic scripts.
In the case of 国 it’s easy, since there’s a clear 1-1 reversible mapping. The problem is that not all characters have that.
Yeah so… it’s a shame you didn’t go the other way, I think, since IIRC every traditional char maps to a single simplified char, but not visa versa. So that would be more reliable. You can map a simplified corpus to traditional, but because the mapping isn’t unique, you need to use a language model (hah!) or at least n-gram frequencies to handle the ambiguities. According to opencc for example, they just map to the first match if there’s an ambiguity. I don’t know if hanziconv and mafan do the same thing - I wouldn’t be surprised if that’s all they did, unfortunately.
I don’t think it’s going to matter too much however if you end up with a slightly-wrong corpus. Simplified Chinese characters are designed such that ambiguities are unlikely to be a problem in understanding language. So I’d guess you’ll be fine - but just be aware that the issue exists.
FYI, my tokenization seems stalled after a while and I used chunk size = 24k as in the notebook.
I’m using 5k instead and so far so good. Maybe worth noting in case you don’t have a powerful machine like the one Jeremy has!
The 1-1 mapping thing really bothered me for a while too! I think simplification actually removed the “soul” of the language. Once gone, it’s not easy to get it back (maybe a NN mapping could be better?)!
Well I love the simplified characters personally. I think it’s an extraordinary linguistic project that was done very well.
Top Chinese writers throughout history have railed against the complexity of the character set. For a long time it was explicitly designed to maximize exclusivity of the educated class!
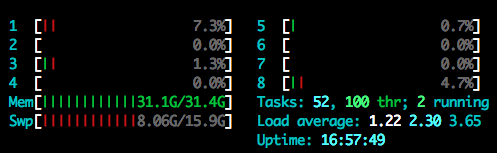
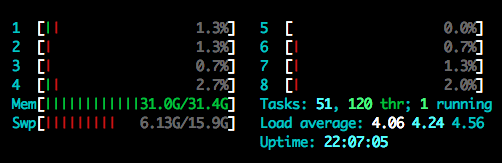
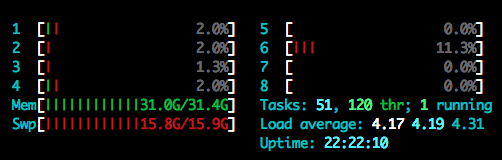
@jeremy During tokenization, I’ve been reducing batch sizes from 5k to 2k now, and every time when my RAM maxes out, all the CPU cores turn “quite” like this one. at the same time Swp increases, and my iteration seems “stalled” at this stage (iteration 321). I should have noticed it in my previous post suggesting batch size = 5k. This image seems like a “death sentence”…
If I wait longer (like the previous few times), I get an error message. concurrent.futures.process.BrokenProcessPool: A process in the process pool was terminated abruptly while the future was running or pending.
I think @lesscomfortable had a similar problem but he used batch 5k and perhaps a more powerful paperspace instance.
Would you recommend anything for this case? I don’t know much about garbage collection (reading it) or how the program keeps threads alive. Reducing batch size doesn’t seem to solve the memory problem. I also thought about creating and enabling a swp file, but even if there is Swp space, the processes wouldn’t move forward.
My machine was 32GB RAM. I would suggest to keep on reducing the chunk size, eventually one will work (it did for me ). But also save your progress so you don’t lose everything when (if) it crashes. I divided my trn_set into 12 and run the tokenizator on each of them, thus saving my progress.
But do not let go. The training part works fine if you can pass the tokenizer.
Yeah it’s running out of memory - your swap is full. Maybe try running on less cores? (Or even just run one one core?) I’m not sure why it’s using so much memory - I’m no expert at debugging Python memory issues. There’s a few memory debugging tips around, eg
Thanks Jeremy. I tried the single-core version proc_all while increased chunksize and it has the same issue of stalling after n_iter * batch size * text size per batch > RAM. I think the lists were just getting too big and I’m going around the problem by doing what @lesscomfortable did to save the list every n iterations incrementally, and then concat all at the end.
I started to attempt training a language model for korean as I planned to classify toxic comments.
I am currently using Konlpy for the tokeniser but sentencepiece suggested by Jeremy looks interesting as well.
I will try with what I have got at the moment first and update you. Thanks.
A note to those folks building langage models: there’s no reason to go beyond 100 million tokens - in my experiments it didn’t help. So if your corpus is bigger than that, remove some of the smaller articles (for instance) until the corpus is down to that size. Really large corpuses are a pain to work with, and don’t have any benefits I saw.
Click on the “Database backup dumps” (WikiDumps) link. (It took me a while to figure out it is a link!)
There will be a long list inside the WikiDump. In this example, I pick ‘zh_yue’ for Cantonese (a subset of Chinese) and download it. (Warning: some of the file are very big)
Under WikiExtactor directory, then install it by typing (sudo) python setup.py install
Syntax for extracting files into json format: WikiExtractor.py -s --json -o {new_folder_name} {wikidumps_file_name}
(Note: the {new_folder_name} will be created during extracting;
more download options available under WikiExtractor readme)
Example: $ WikiExtractor.py -s --json -o cantonese zh_yuewiki-20180401-pages-meta-current.xml.bz2
Hi everyone, I wanna work on Sanskrit Language but I am not finding useful sources to download the data from. Also there isn’t any suitable Tokenizer that I know of as of now. Please guide me to appropriate resources if somebody know.
Also for the tokenization I am thinking to use Sentencepiece that @jeremy mentioned in Lesson 10. I have gone through the github page but I am unable to figure out how it works ( I am not good with programming and command lines … ) . If anybody has tried it out please shine some light on its usage.

 ). But also save your progress so you don’t lose everything when (if) it crashes. I divided my trn_set into 12 and run the tokenizator on each of them, thus saving my progress.
). But also save your progress so you don’t lose everything when (if) it crashes. I divided my trn_set into 12 and run the tokenizator on each of them, thus saving my progress.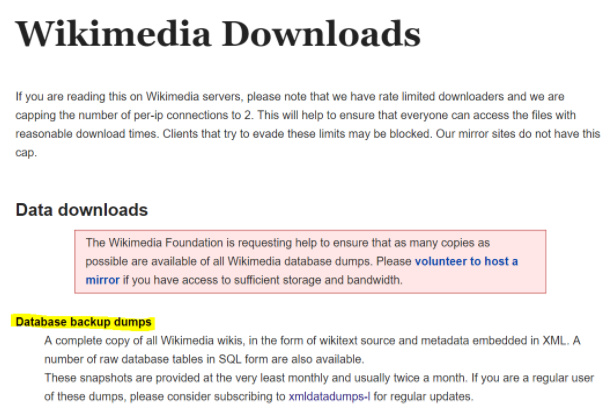
 ) . If anybody has tried it out please shine some light on its usage.
) . If anybody has tried it out please shine some light on its usage.